Lex �� Yacc �� Unix ��Linux �´ʷ�����ķ������������ߣ��������������ߣ�������Լ�������Ҫ�ı�������Ҳ���������������г������ԵĽ���������Ҫע�����linux�µ��������������ɵij���Դ��ֻ����C��C++���ԣ���Ȼ�������������ƿ�������JavaԴ��������������ϳ��õ�JavaCC(Java Compiler Compiler)��������ݿ���ȥ����������Lex��Yacc�ѱ���ֲ��windows�£����ڳ��õĹ�����Parser Generator������ֻ����Linux ��Lex��Yacc��ʹ�÷�����
Lex����
Lex ͨ����.lex��.l�ļ�����ĸ�ʽ����һ��C����Դ���ļ���ͨ���������Դ�룬��������.lex�ļ���.l�ļ�����ı�������.lex��.l�ļ��ĸ�ʽ������:
1.ȫ�ֱ�����������
2.�ʷ�����
3.�������岿��
������һ�������ӣ�lex_example.l�ļ�
%{ //ȫ����������
/*��ľ100 linux
www.linmu100.com
*/
#include <stdio.h>
extern char *yytext;
extern FILE *yyin;
int sem_count = 0;
%}
//�����岿�֣�
%%
[a-zA-Z][a-zA-Z0-9]* {printf("WORD[%s] ", yytext);}
[a-zA-Z0-9\/.-]+ printf("FILENAME ");
\" printf("QUOTE ");
\{ printf("OBRACE ");
\} printf("EBRACE ");
; {sem_count++; printf("SEMICOLON ");}
\n printf("\n");
[ \t]+ /* ignore whitespace */;
%%
//����Ϊ�������岿��
int main(int avgs, char *avgr[])
{
yyin = fopen(avgr[1], "r");
if (!yyin)
{
return 0;
}
yylex();
printf("sem_count : %d\n", sem_count);
fclose(yyin);
return 1;
}
Lex ���ø�ʽ���±����������ʽ��
| �ַ� |
���� |
| A-Z, 0-9, a-z |
�����˲���ģʽ���ַ������֡� |
| . |
ƥ�������ַ������� \n�� |
| - |
����ָ����Χ�����磺A-Z ָ�� A �� Z ֮��������ַ��� |
| [ ] |
һ���ַ����ϡ�ƥ�������ڵ����� �ַ��������һ���ַ��� ^ ��ô����ʾ��ģʽ������: [abC] ƥ�� a, b, �� C�е��κ�һ���� |
| * |
ƥ��0�����߶��������ģʽ�� |
| + |
ƥ��1�����߶������ģʽ�� |
| ? |
ƥ��0����1������ģʽ�� |
| $ |
��Ϊģʽ�����һ���ַ�ƥ��һ�еĽ�β�� |
| { } |
ָ��һ��ģʽ���ܳ��ֵĴ����� ����: A{1,3} ��ʾ A ���ܳ���1�λ�3�Ρ� |
| \ |
����ת��Ԫ�ַ���ͬ�����������ַ��ڴ˱��ж�����������壬ֻȡ�ַ��ı��⡣ |
| ^ |
�� |
| | |
����ʽ������� |
| "<һЩ����>" |
�ַ������溬�塣Ԫ�ַ����С� |
| / |
��ǰƥ�䡣�����ƥ���ģ���еġ�/������к�������ʽ��ֻƥ��ģ���С�/��ǰ��IJ��֡��磺������� A01����ô��ģ�� A0/1 �е� A0 ��ƥ��ġ� |
| ( ) |
��һϵ�г������ʽ���顣 |
�������ʽ����
| �������ʽ |
���� |
| joke[rs] |
ƥ�� jokes �� joker�� |
| A{1,2}shis+ |
ƥ�� AAshis, Ashis, AAshi, Ashi�� |
| (A[b-e])+ |
ƥ���� A ����λ�ú����Ĵ� b �� e �������ַ��е� 0 ���� 1���� |
ʹ��lexɨ�����������ļ� lex_example.l��
lex lex_example.l
ȱʡ������lex.yy.c�ļ���Ȼ����gcc��������ļ���ע��Ҫ��-llѡ��:
gcc lex.yy.c -o analyse -ll
������������һ���Ĵʷ�������analyse���������ļ�demo��������������ʾ:
firstword;
secondword;
thirdword
fourthword{
fifthword
}
��������:
./analyse demo
����������ʾ��
WORD[firstword] SEMICOLON
WORD[secondword] SEMICOLON
WORD[thirdword]
WORD[fourthword] OBRACE
WORD[fifthword]
EBRACE
sem_count : 2
ʵ���ϣ���������lex_example.l�ļ����������岿�ֿ�����ȫʡ�ԣ���Ϊlex���Զ�Ϊ������main��������ʱ��Ȼ��������������analyse����������:
./analse < demo
������£�
WORD[firstword] SEMICOLON
WORD[secondword] SEMICOLON
WORD[thirdword]
WORD[fourthword] OBRACE
WORD[fifthword]
EBRACE
������lex_example.l�ļ������ǻ�ʹ��������������
extern char *yytext;
extern FILE *yyin;
������������lex�ṩ���ⲿ��ڣ��û����Ը����Լ���Ҫ�Լ����ģ�lex�ṩ�����½ӿڣ�
Lex ����
| yyin |
FILE* ���͡� ��ָ�� lexer ���ڽ����ĵ�ǰ�ļ��� |
| yyout |
FILE* ���͡� ��ָ���¼ lexer �����λ�á� ȱʡ����£�yyin �� yyout ��ָ������������� |
| yytext |
ƥ��ģʽ���ı��洢����һ�����У�char*���� |
| yyleng |
����ƥ��ģʽ�ij��ȡ� |
| yylineno |
�ṩ��ǰ��������Ϣ����lexer��һ��֧�֡��� |
Lex ����
| yylex() |
��һ������ʼ������ ���� Lex �Զ����ɡ� |
| yywrap() |
�� һ�������ļ��������룩��ĩβ���á���������ķ���ֵ��1����ֹͣ������ ���������������������ļ����������д�ڵ����Σ�����ܹ���������ļ��� ������ʹ�� yyin �ļ�ָ�루���ϱ���ָ��ͬ���ļ���ֱ�����е��ļ��������������yywrap() ���Է��� 1 ����ʾ�����Ľ����� |
| yyless(int n) |
��һ�������������ͻس���ǰ�n? ���ַ�������ж�����ǡ� |
| yymore() |
��һ�������� Lexer ����һ����Ǹ��ӵ���ǰ��Ǻ� |
������һ�������ַ�������.l�ļ����ݣ�����Ȥ�����ѿ��Ա�������
%{
/*
��ľ100 linux
www.linmu100.com
*/
int wc = 0; /* word count */
%}
%%
[a-zA-Z]+ { wc++; }
\n|. { /* gobble up */ }
%%
int main(void)
{
int n = yylex();
return n;
}
int yywrap(void)
{
printf("word count: %d\n", wc);
return 1;
}
yacc����
Yacc �� Yet Another Compiler Compiler����д�� Yacc �� GNU ����� Bison������һ����������ߡ����ðͿ�˹��ʽ(BNF, Backus Naur Form)����д�����չ�����Yacc �ļ��� .y ����
ʵ���ϣ�yacc��������������ĺ��ģ�.y�ļ���ʽ��.l�ļ�һ�������Σ���ÿһ�ε�����������ͬ��
1.ȫ�ֱ����������ս����(�ն˷���)����
2.�����
3.��������
������һ����yacc_example.y�ļ���������һ���ļ�������
%{
//ȫ�ֱ�������
#include <ctype.h>
#include <stdio.h>
#define YYSTYPE double /*double type for YACC stack; for yylval*/
/*��ľ100 www.linmu100.com */
void yyerror(const char *str)
{
fprintf(stderr, "error:%s\n", str );
}
%}
//�ս������
%token NUMBER
%%
lines : lines expr '\n' { printf("%g\n", $2); }
| lines '\n'
| /* e */
| error '\n' { yyerror("reenter last line:"); /*yyerrok(); */}
;
expr : expr '+' term { $$ = $1 + $3; }
| expr '-' term { $$ = $1 - $3; }
| term
;
term : term '*' factor { $$ = $1 * $3; }
| term '/' factor { $$ = $1 / $3; }
| factor
;
factor : '(' expr ')' { $$ = $2; }
| '(' expr error { $$ = $2; yyerror("missing ')'"); /*yyerrok(); */}
| '-' factor { $$ = -$2; }
| NUMBER
;
%%
//���ϲ���Ϊ����壬���²���Ϊ��������
int main(void)
{
return yyparse();
}
int yylex(void)
{
int c;
while ((c = getchar()) == ' ');
if (c == '.' || isdigit(c)) {
ungetc(c, stdin);
scanf("%lf", &yylval);
return NUMBER;
}
return c;
}
ʹ��yaccɨ������ļ���
yacc yacc_example.y
ȱʡ������һ��y.tab.c�ļ���Ȼ����gcc��������ļ���ע��Ҫ��ѡ�� -ll �� -ly��
gcc y.tab.c -o analyse -ll
����./analyse���������ͼ��ʾ:
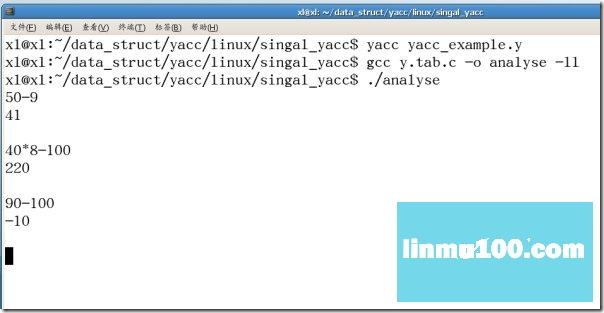
���ڶ���yacc_example.y�ļ�����һ��.y�ļ��Ĺ���
1.��ȫ�ֱ����������֣�������һ���ӿں���yyerror����������������ڳ���ʱ���õġ���һ����Ҫ������һЩ���������ݽṹ�������á�
2.%token NUMBER��������һ���ն˷�(�ս��)�������������Lex���صģ�����yacc��������õ���
3.����������������
3.1��������ֻ��һ���ӿڣ���һ��Ҫע�⣬��ѧ�߳����᷸������ж���ӿڵĴ���
3.2������lex�ļ�����yacc�ļ���Ҫע���������ԵĴʷ��������Ҫ���ڳ�ͻ�����ǰ�棬������֤�������ܹ���ᱻ����ƥ�䣬����lex�ļ��У�
temperator return T1;
temp return T2;
��yacc�ļ��У���������
command:
NUMBER CHAR
| NUMBER
;
����.y�ļ���Ҫע��ȫ������Լ��ݹ�ĵ��á�
��ѧ�߶���yacc�ļ�������ܻ��Ϊ���裬�ؼ���Ҫ����һЩ��ϰ��
Lex �� Yacc �Ľ��
lex��yacc���ʱ��Ҫע�����
lex�ļ�ͷҪ����yacc���ɵ�ͷ�ļ�:"y.tab.h"
������һ��lex��yacc��ϵ�ʵ����
lex_yacc_exp.l�ļ���
%{
/*��ľ100
www.linmu100.com
*/
#include <stdio.h>
#include <string.h>
#include "y.tab.h"
extern char *yytext;
%}
%%
[0-9]+ yylval.number=atoi(yytext); return NUMBER;
heater return TOKHEATER;
heat return TOKHEAT;
on|off yylval.number=!strcmp(yytext,"on"); return STATE;
target return TOKTARGET;
temperature return TOKTEMPERATURE;
[a-z0-9]+ yylval.string=strdup(yytext);return WORD;
\n /* ignore end of line */;
[ \t]+ /* ignore whitespace */;
%%
lex_yacc_exp.y�ļ�:
%{
/*��ľ100
www.linmu100.com
*/
#include <stdio.h>
#include <string.h>
void yyerror(const char *str)
{
fprintf(stderr,"error: %s\n",str);
}
int yywrap()
{
return 1;
}
main()
{
yyparse();
}
char *heater="xl's test";
%}
%token TOKHEATER TOKHEAT TOKTARGET TOKTEMPERATURE
%union
{
int number;
char *string;
}
%token <number> STATE
%token <number> NUMBER
%token <string> WORD
%%
commands:
| commands command
;
command:
heat_switch | target_set | heater_select
heat_switch:
TOKHEAT STATE
{
if($2)
printf("\tHeater '%s' turned on\n", heater);
else
printf("\tHeat '%s' turned off\n", heater);
}
;
target_set:
TOKTARGET TOKTEMPERATURE NUMBER
{
printf("\tHeater '%s' temperature set to %d\n",heater, $3);
}
;
heater_select:
TOKHEATER WORD
{
printf("\tSelected heater '%s'\n",$2);
heater=$2;
}
;
������������ֱ�����lex.yy.c��y.tab.c��y.tab.h�����ļ���
lex lex_yacc_exp.l
yacc -d lex_yacc_exp.y
gcc lex.yy.c y.tab.c -o analyse -ll
����һ�������demo����������:
heat on
target temperature 99
heater asdfsieiwef99adsf
����./analyse <demo����demo�ļ�����õ����½��:
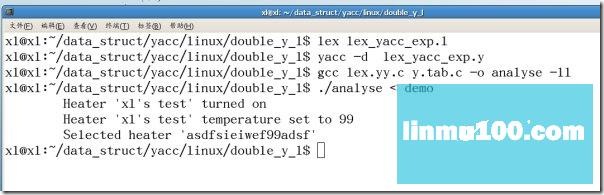
���
Lex �� Yacc �Ǻ�ǿ��Ĺ��ߣ�����ֻ������һЩ����֪ʶ��
The Lex & Yacc Page ���кܶ���Ȥ����ʷ�ο����Լ� �dz��õ� lex �� yacc �ĵ���
�ο��ĵ���
http://www.ibm.com/developerworks/cn/linux/l-lexyac.html
http://blog.csdn.net/ThinkinginLinux/archive/2005/03/19/323379.aspx