微服务架构体系中,通常一个业务系统会有很多的微服务,比如:OrderService、ProductService、UserService...,为了让调用更简单,一般会在这些服务前端再封装一层,类似下面这样:
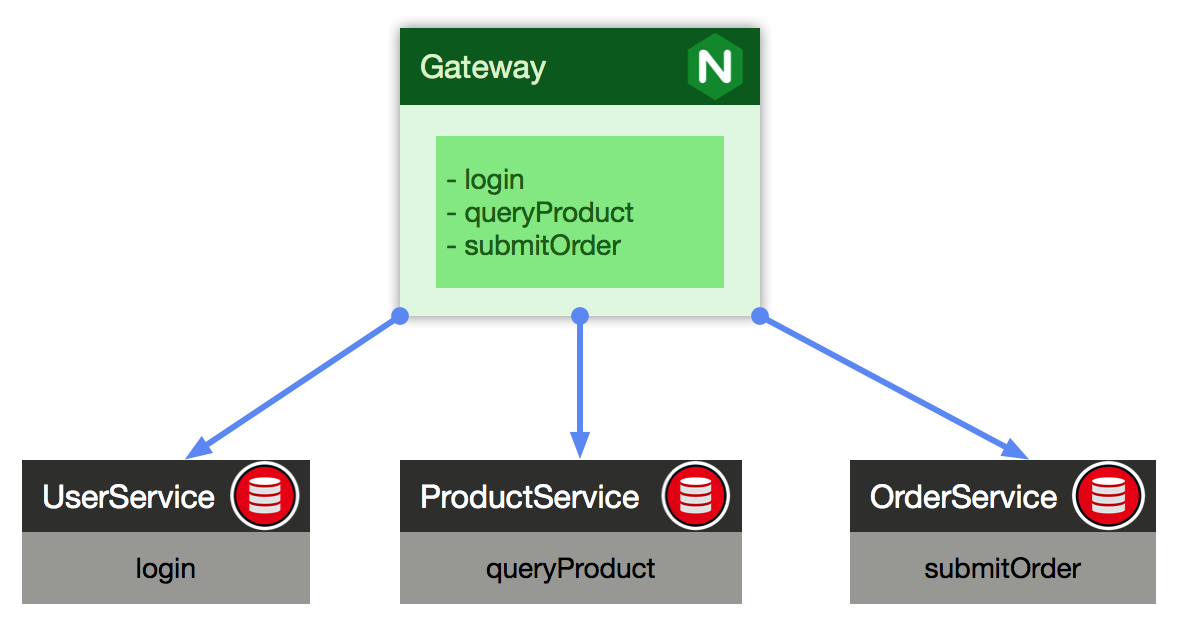
前面这一层俗称为“网关层”,其存在意义在于,将"1对N"问题 转换成了"1对1”问题,同时在请求到达真正的微服务之前,可以做一些预处理,比如:来源合法性检测,权限校验,反爬虫之类...
传统方式下,最土的办法,网关层可以人肉封装,类似以下示例代码:
LoginResult login(...){<br>
//TODO 预处理...
return
userService.login();
//调用用户服务的登录方法
}
Product queryProduct(...){<br>
//TODO 预处理...
return
productService.queryProduct();
//调用产品服务的查询方法
}
Order submitOrder(...){<br>
//TODO 预处理...
return
orderService.submitOrder();
//调用订单服务的查询方法
}
|
这样做,当然能跑起来,但是维护量大,以后各个微服务增加了新方法,都需要在网关层手动增加相应的方法封装,而spring cloud 中的zuul很好的解决了这一问题,示意图如下:
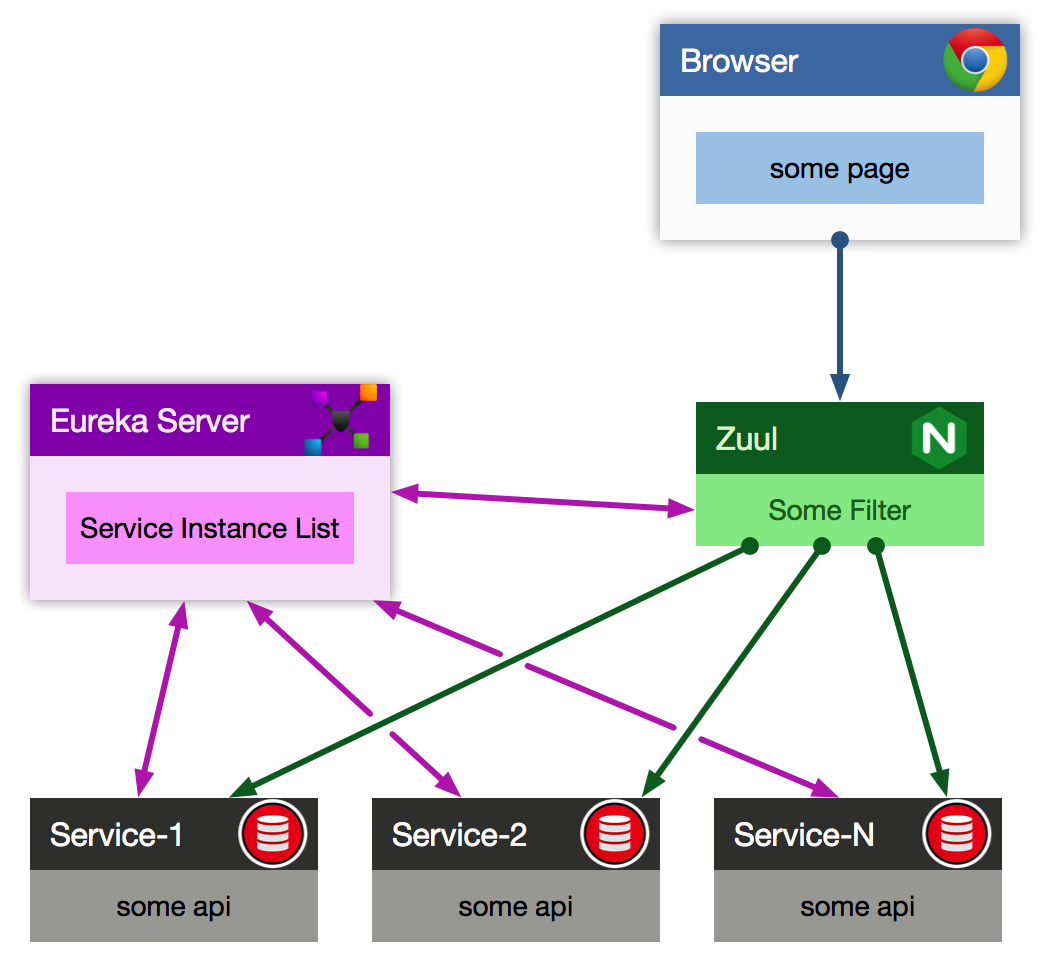
Zuul做为网关层,自身也是一个微服务,跟其它服务Service-1,Service-2, ... Service-N一样,都注册在eureka server上,可以相互发现,zuul能感知到哪些服务在线,同时通过配置路由规则(后面会给出示例),可以将请求自动转发到指定的后端微服务上,对于一些公用的预处理(比如:权限认证,token合法性校验,灰度验证时部分流量引导之类),可以放在所谓的过滤器(ZuulFilter)里处理,这样后端服务以后新增了服务,zuul层几乎不用修改。
使用步骤:
一、添加zuul依赖的jar包
|
1
|
compile
'org.springframework.cloud:spring-cloud-starter-zuul'
|
二、application.yml里配置路由
|
1
2
3
4
5
6
7
8
9
|
zuul:
routes:
api-a:
path: /api-user/**
service-id: service-provider
sensitive-headers:
api-b:
path: /api-order/**
service-id: service-consumer
|
解释一下:上面这段配置表示,/api-user/开头的url请求,将转发到service-provider这个微服务上,/api-order/开头的url请求,将转发到service-consumer这个微服务上。
三、熔断处理
如果网关后面的微服务挂了,zuul还允许定义一个fallback类,用于熔断处理,参考下面的代码:
开发人员只要在getRoute这个方法里指定要处理的微服务实例,然后重写fallbackResponse即可。

此时,如果观察/health端点,也可以看到hystrix处于融断开启状态

四、ZuulFilter过滤器
过滤器是一个很有用的机制,下面分几种经典场景演示下:
4.1、token校验/安全认证
网关直接暴露在公网上时,终端要调用某个服务,通常会把登录后的token传过来,网关层对token进行有效性验证,如果token无效(或没传token),提示重新登录或直接拒绝。另外,网关后面的微服务,如果设置了spring security中的basic Auth(即:不允许匿名访问,必须提供用户名、密码),也可以在Filter中处理。参考下面的代码:
Filter一共有4种类型,其常量值在org.springframework.cloud.netflix.zuul.filters.support.FilterConstants 中定义
安全校验,一般放在请求真正处理之前,所以上面的示例filterType指定为pre,剩下的只要在shouldFilter()、run()方法中重写自己的逻辑即可。
4.2 动态修改请求参数
zuulFilter可以拦截所有请求参数,并对其进行修改,比如:终端发过来的数据,出于安全要求,可能是经过加密处理的,需要在网关层进行参数解密,再传递到后面的服务;再比如:用户传过来的token值,需要转换成userId/userName这些信息,再传递到背后的微服务。参考下面的run方法:
更多filter的示例,可以参考官网:https://github.com/spring-cloud-samples/sample-zuul-filters
4.3 灰度发布(Gated Launch/Gray Release)
大型分布式系统中,灰度发布是保证线上系统安全生产的重要手段,一般的做法为:从集群中指定一台(或某几台)机器,每次做新版本发布前,先只发布这些机器上,先观察一下是否正常,如果稳定运行后,再发布到其它机器。这种策略(相当于按部分节点来灰度),大多数情况下可以满足要求,但是有一些特定场景,可能不太适用。
比如:笔者所在的“美味不用等”公司,主要B端用户为各餐饮品牌的商家,多数情况下,如果新上了一个功能,希望找一些规模较小的餐厅做试点,先看看上线后的运行情况,如果运行良好,再推广到其它商家。
再比如:后端服务有N多个版本在同时运行,比如V1、V2,现在新加了一个V3版本(这在手机app应用中很常见),希望只有部分升级了app的用户访问最新的V3版本服务,其它用户仍然访问旧版本,待系统稳定后,再大规模提示用户升级。
对于这些看上去需求各异的灰度需求,其实本质是一样的:将请求(根据参数内容+业务规则),将其转向到特定的灰度机器上。Spring Cloud MicroService中有一个metadata-map(元数据)设置,可以很好的满足这类需求。
首先要引入一个jar包:(这是github上开源的一个项目ribbon-discovery-filter-spring-cloud-starter)
|
1
|
compile
'io.jmnarloch:ribbon-discovery-filter-spring-cloud-starter:2.1.0'
|
示例如下:
在各个服务的application.yml中设置以下metadata-map
|
1
2
3
4
|
eureka:
instance:
metadata-map:
gated-launch:
false
|
即:所有节点发布后,默认灰度模式为false。然后把特定的灰度机器上的配置,该参数改成true(表明这台机器是用于灰度验证的)。
然后在ZuulFilter中参考下面的代码:
注意18-23行,这里演示了通过特定的token参数值,将请求引导到gated-lanuch=true的机器上。(注:参考这个原理,大家可以把参数值,换成自己的version-版本号,shopId-商家Id之类)。只要请求参数中的token=1234567890,这次请求就会转发到灰度节点上。
如果有朋友好奇这是怎么做到的,可以看下io.jmnarloch.spring.cloud.ribbon.predicate.MetadataAwarePredicate 这个类:
大致原理就是拿上下文中,开发人员设置的属性 与 服务节点里的metadata-map 进行比较,如果metadata-map中包括开发人员设置的属性,就返回成功(即:选择这台服务器)
示例源码:https://github.com/yjmyzz/spring-cloud-demo