(一)数据集(环境配置)
本次论文复现环节中:这篇文章是这期论文复现最关键的环节。
1. 下载并安装matab2016a破解版、pycharm、python环境
Matlab:百度云的链接自己找的,安装成功与否是未知的,需要自己尝试。
Pycharm:百度一下,官网就可以,同样,要破解版自己找吧,这个教程很多,不一一赘述。
Python:这里需要0.4.1版本,CUDA 8.0 ,最好是GPU版本,可缩短大量训练时间。
以上软件网上安装入门教程一大堆,不会的话自己可以现学哦,B站什么的so easy!
2. 下载初始数据代码
- 将项目代码用pycharm打开

整体是这样子

3. 数据集和相关安装环境的配置
-
下载项目依赖两个数据集(其实就一个数据集,第二步是下载HHA算法)
github仓库:https://github.com/yanx27/3DGNN_pytorch
-
数据集准备环节有两步

NYU_Depth_V2 dataset 这是纽约大学的深度学习数据集。稍微介绍一下,免得搞了半天不知道在做啥。
NYU-Depth V2数据集由来自各种室内场景的视频序列组成,这些序列由Microsoft Kinect的RGB和Depth摄像机记录。
它具有以下特点:
- 1449个密集标记的RGB和深度图像对齐对
- 来自3个城市的464个新场景
- 407,024个新的未标记帧
- 每个对象都标有一个类和一个实例号(cup1,cup2,cup3等)
数据集包含几个组成部分:
- 标记的:视频数据的子集,并带有密集的多类标记。此数据也已进行了预处理,以填写缺少的深度标签。
- Raw:Kinect提供的原始rgb,深度和加速度计数据。
- 工具箱:用于处理数据和标签的有用功能。
下面附上下载地址,这位大哥把下载好的数据放在了百度云里真的太贴心了。
NYU v2数据集官方下载地址:https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
NYU v2数据集百度云下载地址:https://pan.baidu.com/s/1rIUbsEUjkZJheEZ5wTb5aA 密码: bfi4
转成图片格式的NYU v2数据集百度云下载地址:https://pan.baidu.com/s/1Ut4wk4wwIubB9ZERfbg5Vw 提取码: f1n8
版权声明:本文为CSDN博主「sinat_26871259」的原创文章,遵循 CC 4.0 BY-SA 版权协议。
原文链接:https://blog.csdn.net/sinat_26871259/article/details/82351276**
下载好之后是这样的

具体图片展示(depths这个文件夹的内容)

-
数据集的准备
1. 先放 NYU_Depth_V2 数据集,注意看我的路径,3DGNN_pytorch-master就是项目根目录

2. 新建hha文件(同级)
HHA is an encoding method which extract the information in the depth image which was proposed in Learning Rich Features from RGB-D Images for Object Detection and Segmentation.hha是个数据类型编码,把一般数据用hha方式编码即可,这里需要用到matlab,下面的实现此过程的matlab代码的仓库地址。https://github.com/charlesCXK/Depth2HHA
-
matlab实现 depth―>hha
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bHrlqKiH-1591411900349)(en-resource://database/530:1)]](https://img-blog.csdnimg.cn/20200606105527859.png)
其实不用在意这个raw-depth和depth的说法,通俗来说就是depth才是深度信息的图,是我们需要的数据,而raw-depth是保存depth用的通道有多深。这个数据集中raw-depth数据有误,现在按我说的来:
1. 在depth和rawdepth两个文件夹中
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vkt2O8zY-1591411900350)(en-resource://database/540:1)]](https://img-blog.csdnimg.cn/20200606105512625.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4NDg0NDMw,size_16,color_FFFFFF,t_70)
2. 打开main.m后修改读取到我们的depth文件地址,然后修改输出地址为hha后,运行即可。
每个人的hha展示图可能不一样,是因为单位没修改正确。

这是包含了RD和Depth的没有对原始数据除1000的图

这是利用两个一样的Depth数据的没有对原始数据除1000的图

这是利用两个一样的Depth数据的有对原始数据除1000的图
第三个图说明,方案是正确的
到这一步我们的数据预处理和环境配置都已经完成,下一篇博客我将来为大家介绍如何用这个数据进行图神经网络学习(3DGNN)。
来个传送门:
- 【报错】使用下载好的mat数据集(2.8G)报错内存不够怎么办
(二)数据载入
载入mat文件
先说一下替换mat出现了问题之事。
看这个图,只有nyu开头的mat是可以用的,因为matlab再保存mat时,需要用特殊的版本和格式保存才可以,具体代码如下(matlab):
load('nyu_depth_v2_labeled.mat')todo=900;
%这里todo意思是把1449个图片cut,cut前多少张accelData=accelData(1:todo,:);
depths=depths(:,:,1:todo);
instances=instances(:,:,1:todo);
labels=labels(:,:,1:todo);
rawDepths=rawDepths(:,:,1:todo);
% size(images)
images=images(:,:,:,1:todo);
% rawDepthFilenames=rawDepthFilenames(1:14,:);
save('data.mat', 'sceneTypes', 'accelData', 'depths', 'images', 'instances', 'labels', 'names','namesToIds', 'rawDepthFilenames', 'rawDepths', 'rawRgbFilenames', 'scenes', '-v7.3')注意保存时:’-v7.3’
这样才能用源码方式正确打开mat
python项目的源码中
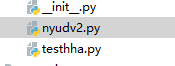
文件的打开mat步骤代码如下:
f = h5py.File(data_path + data_file,'r')
就要这样才行,加‘r’,以免提示警告
然后就可以加载mat和hha了。
载入hha文件

按代码中位置放即可。
还是这个py文件,我可能是在做测试的时候,改了一下路径,以下这个路径写的时候要注意
但是他是在根目录下run.py中运行的,注意路径问题。

(三)数据训练
- 运行run.py

长时间在0 这样子就是有问题的!

一直这样就有问题,应该是文件没有读进去,刚开始我就一直出现这样的问题,直到看了dataset的相关资料才发现其加载数据的原理
 就是这一步一定要注意。
就是这一步一定要注意。 - 几个报错问题
若没有报错(其实是电脑配置够的话)就会看见结果,若报错内容为关于内存的,就改小batchsize的大小,我的gpu 1060ti(6g),用300张图,batchsize为2差不多,极限可能是800张*batchsize=1。要修改就在这里(run.py)自己找。

之后不出意外,结果=>为这样,路径自己看,3dgnn_finish.pth是最好的一次结果所对应的模型参数。

(四)预测
网上找了一大堆关于加载pth和利用的教程。发现?如狗屎,太烂了,根本用不了。后来仔细读代码,想想代码中应该有output和预测结果的,不然,计算机如何对比预测结果与真实结果差异?然后计算loss,然后反向传播?我当时就给聪明的我一巴掌,这么简单的道理怎么现在才懂!
于是看代码发现,预测代码大概在这个函数里。
dataloader_va是预测集,查看加载这个dataloader_va的源码发现,他就是训练集。
然后用eval_set中的代码来找寻可以把input-output转化的地方:
就是这里!

细心的同学会发现:output这个地方就是代表输出,下文细说这是什么。
在我的项目中,预测代码在prediction.py中!是我自己写的,原文作者(torch)版本没有这个文件。
运行时需要改两个地方,自己创建合适的文件名。


第一个是输出预测的数据(1,2,3,4这样的类型数据)――后前拿这样的数据去matlab跑可视化
第二个是加载训练模型――pth
我这个是可以把一张、多张进行分割的,只需要对输入的图像进行修改就行。
修改地方

预测代码结束

结果:


这其实就是output的最终数据:就是每个像元最可能是什么类型的东西
(五)可视化
matlab可视化做的好一点,涉及矩阵的东西可以直接深入调看!
- 先新建一个文件夹存放数据

2. 运行这个m文件
这个m文件也是我自己写的。

不,实际上这是个函数,只需要给一个索引就行,这里应该把输入输出写成接口,人太懒了,不写了,每次需要自己改。
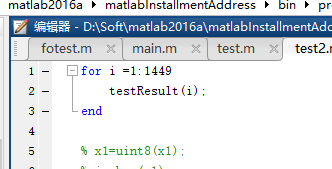
上图是调用方法,多少张图就for到第几个
实际上要运行这个
然后运行等待1449张图片!

大概1000s左右 over

后记
看看精度,对比一下原图,找问题,设计优化啥的。问题颇多,代码问题,原理问题,论文问题。
我写了一篇论文供参考和入门图神经网络。有对这方面感兴趣的可以前去下载这篇论文。
下载地址:https://download.csdn.net/download/qq_38484430/12517770





