����AD-Census����Դ�룬�������: https://github.com/ethan-li-coding/AD-Census
��ӭͬѧ����Github��Ŀ�����ۣ�������ò��������������������Ͻ�starһ�£���л��
AD-Census�㷨�������й�ѧ��Xing Mei����ICCV2011���������ġ�On Building an Accurate Stereo Matching System on Graphics Hardware��1���㷨Ч�ʸߡ�Ч����ɫ��Intel RealSense D400���ǻ��ڸ��㷨ʵ�ֵ�����ƥ�� 2��
��ϵ�н�����������˽�AD-Census�����ۣ�ϣ���ܹ���ͬѧ�ǵ�����ƥ���㷨�о�����������
AD-Census��һ�����ֲ��㷨�Ͱ�ȫ���㷨���ϵ��㷨���������ĸ����裺1 ��ʼ���ۼ��㡢2 ���۾ۺϡ�3 ɨ�����Ż���4 �Ӳ��Ż�����ƪ��������ɨ�����Ż����֡�
Step 1. AD-Census Cost Initialization
Step 2. Cross-based Cost Aggregation
Step 3. Scanline Optimization
Step 4. Multi-step Disparity Refinement
�����ۺ�߶��������ƥ��ϵ�С�����AD-Census: ��3��ɨ�����Ż�
����˽�����һ������ƥ�侭���㷨��SemiGlobalMatching����ɨ�����Ż��϶��Dz�İ���ģ���ҿ�����������ǰ��IJ��ͣ�
�����ۺ�߶��������ƥ��ϵ�С�����SGM����3�����۾ۺϣ�Cost Aggregation��
SGM�Ĵ��۾ۺϾ���ʹ�õ�ɨ�����Ż�˼·����AD-Census��ɨ�����Ż�˼·���ǽ����SGM��˼·���и߶�һ���ԡ�
We employ a multi-direction scanline optimizer based on Hirschmuller��s semi-global matching method
��ɨ�����Ż���Ŀ����Ҫ��һ����ߴ��۵�ȷ�ԣ�����ƥ������Ż�˼·��SGM�Ĵ��۾ۺ�˼·һģһ����ע��SGM��ɨ�����Ż��д��۾ۺϣ���AD-Census�ͽ�ɨ�����Ż���ʵ���ϱ�����һ���IJ�����ֻ�ǽз���ͬ���ѣ����Ż��ķ�����Ϊ4���ֱ������ҡ��ϡ��¡�

���� p p p ijһ���� r r r���Ż���ʽΪ��
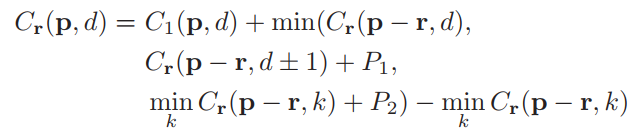
��SGM�Ĺ�ʽһ���ģ����������˽���ϸ����鿴���������IJ��͵�ַ������Ͳ�ϸ˵�ˡ�
�����ۺ�߶��������ƥ��ϵ�С�����SGM����3�����۾ۺϣ�Cost Aggregation��
AD-Census������������ P 1 P_1 P1?�� P 2 P_2 P2?ֵ���趨��ʽ����SGM�У� P 1 P_1 P1?�� P 2 �� P_2' P2��?��Ԥ��Ĺ̶�ֵ��ʵ��ʹ�õ� P 2 P_2 P2?�Ǹ�������ͼ�����������ص����Ȳ�ֵ��ʵʱ�����ģ�������ʽΪ P 2 = P 2 �� / ( I p ? I q ) P_2=P_2'/(I_p-I_q) P2?=P2��?/(Ip??Iq?)��
����Ad-Census�У� P 1 P_1 P1?�� P 2 P_2 P2?��ֻ�Ǻ�����ͼ������������ɫ�� D 1 = D c ( p , p ? r ) D_1=D_c(p,p-r) D1?=Dc?(p,p?r)�йأ����Һ�����ͼ��Ӧͬ���������������ɫ�� D 2 = D c ( p d , p d ? r ) D_2=D_c(pd,pd-r) D2?=Dc?(pd,pd?r)�йء�
��ע1��AD-Census�㷨Ĭ�������ɫͼ������������ɫ����������Ҷ�ͼ���������Ȳ��ɫ��Ķ����� D c ( p l , p ) = m a x i = R , G , B �O I i ( p l ) ? I i ( p ) �O D_c(p_l,p)=max_{i=R,G,B}|I_i(p_l)-I_i(p)| Dc?(pl?,p)=maxi=R,G,B?�OIi?(pl?)?Ii?(p)�O����������ɫ������ֵ�����ֵ��
��ע2�� p d pd pd ʵ�ʾ������� p p p ͨ���Ӳ� d d d �ҵ�������ͼ�ϵ�ͬ���� q = p ? d q=p-d q=p?d��
��ע3�� p ? r p-r p?r�����ۺϷ����ϵ���һ�����أ���������Ҿۺϣ��� p ? r p-r p?r���� p ? 1 p-1 p?1�����ҵ���ۺϣ��� p ? r p-r p?r���� p + 1 p+1 p+1��
�����趨�������£�
- P 1 = �� 1 , P 2 = �� 2 , i f D 1 < �� S O , D 2 < �� S O P_1=��_1,P_2=��_2, if D_1<��_{SO},D_2<��_{SO} P1?=��1?,P2?=��2?,ifD1?<��SO?,D2?<��SO?
- P 1 = �� 1 / 4 , P 2 = �� 2 / 4 , i f D 1 < �� S O , D 2 > �� S O P_1=��_1/4,P_2=��_2/4, if D_1<��_{SO},D_2>��_{SO} P1?=��1?/4,P2?=��2?/4,ifD1?<��SO?,D2?>��SO?
- P 1 = �� 1 / 4 , P 2 = �� 2 / 4 , i f D 1 > �� S O , D 2 < �� S O P_1=��_1/4,P_2=��_2/4, if D_1>��_{SO},D_2<��_{SO} P1?=��1?/4,P2?=��2?/4,ifD1?>��SO?,D2?<��SO?
- P 1 = �� 1 / 10 , P 2 = �� 2 / 10 , i f D 1 > �� S O , D 2 > �� S O P_1=��_1/10,P_2=��_2/10, if D_1>��_{SO},D_2>��_{SO} P1?=��1?/10,P2?=��2?/10,ifD1?>��SO?,D2?>��SO?
�� 1 , �� 2 ��_1,��_2 ��1?,��2?���趨�Ĺ̶���ֵ�� �� S O ��_{SO} ��SO?���趨����ɫ����ֵ��
��������Ҫ����� P 1 P_1 P1?�� P 2 P_2 P2?�������ڳͷ�ʲô����SGM�����۽��ܲ����У���˵�ıȽ���ϸ���ܵ���˵���������ڳͷ����ڵ������Ӳ����ܴ����ֱ��֣� P 1 P_1 P1?�ͷ��������1�����أ� P 2 P_2 P2?�ͷ��������1���������ϣ����������ݾ���һ�����裺��ɫ��������ؾ���������Ӳ�ֵ�����ͨ�����ж�����������ɫ�Ƿ�����������ɫ�������ô����Ϊ������Ӧ��Ҫ��������Ӳ������Ӳ����ܴ���ô��Ҫ����һ���ϴ�ijͷ�ֵ��Ҳ������ P 1 P_1 P1?�� P 2 P_2 P2?����Щ��
������λ�����֮�����������ΪʲôSGMҪ�������ȵIJ�ֵ������ P 2 P_2 P2?��Ҳ������AD-Census���������ĺ��塣���Ǿ�����SGM�Ļ����ϣ���������ǵĸ��Ӿ�ϸһЩ��������ͼ������Ȳ���ǽ����������³�����ҷ�����������������
- ����1����˼�ǣ��������ͼ�����ڵ�������ɫ���С����ô�������ش���ʾ����Ӳ���ͬ������ˣ��Ӳ��1���������϶�Ҫ�������ȳͷ����������� P 1 P_1 P1?�� P 2 P_2 P2?�����ġ�
- ����2����˼�ǣ������ͼ������������ɫ���С��������ͼ����������ɫ���Դ���ô�������Ӳ���ͬ������ĸ��ʽϵ�һ��������Խ��ͣ���ȵ�һ����������� P 1 P_1 P1?�� P 2 P_2 P2?��ֵ��
- ����3����2��һ����˼�������෴����ͼ����ɫ��С����ͼ����ɫ���Դ� P 1 P_1 P1?�� P 2 P_2 P2?��ֵ����2һ����
- ����4����˼�ǣ��������ͼ�����ڵ�������ɫ��ܴ���ô�������ص��Ӳ�������һ�����ģ��ܿ������Ӳ������������1���������ϡ����Գͷ�����Ӧ����С�� P 1 P_1 P1?�� P 2 P_2 P2?��ʱ������С�ġ�
���4��������Ż����ۣ�ȡƽ��ֵ�������� p p p ��
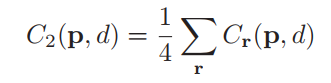
��ƪ�����ݾ͵��������һƪһ�����裬�������������һƪ��������AD-Census���һ�����Ӳ��Ż���
������飺
Ethan Li ��ӭ�ɣ�֪������ӭ�ɣ�
�人��ѧ ��Ӱ������ң��רҵ��ʿ
����������ƥ�䡢��ά�ؽ�
2019�����Ƽ�����һ�Ƚ���ʡ������
����ά��������������Դ
GitHub�� https://github.com/ethan-li-coding
���䣺ethan.li.whu@gmail.com
�����ţ�
��ӭ������
��ע��������·����л��
������ҳ��https://ethanli.blog.csdn.net

Zhang K , Lu J , Lafruit G . Cross-Based Local Stereo Matching Using Orthogonal Integral Images[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2009, 19(7):1073-1079. ??
Keselman L , Woodfill J I , Grunnet-Jepsen A , et al. Intel? RealSense? Stereoscopic Depth Cameras[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2017. ??