neo4j cypher操作
文章目录
- neo4j cypher操作
-
- neo4j CMD命令
- 前言
- 1增加
-
- 1.1 增加节点
- 1.2 查询节点
- 2 关系
-
- 2.1 创建关系
- 2.2 查询关系
- 3 删除
-
- 3.1 删除节点
- 3.2 删除关系
- 3.3 删除所有节点关系,清空数据库
-
- a
- b
- 4 set 增添修改属性
- 中文版neo4j
-
- 1.创建图片节点
- 参考
neo4j CMD命令
前言
# 安装服务
neo4j install-service
# 卸载服务
neo4j uninstall-service# 启动浏览器控制台(包括启动服务)
neo4j console
# 启动服务
neo4j start
# 停止服务
neo4j stop
# 查询服务状态
neo4j status
#重启服务
neo4j restart
1增加
1.1 增加节点
a create
最简单的创建节点,不管数据库是否拥有相同的属性和标签,创建一个新的节点。
如果之前拥有相同的属性和标签的节点,那么两者的 id 不一样
create (:明星{name:"刘德华"})

b create 有return
// 加一个return 会显示节点
create (n:明星{name:"刘德华"}) return n

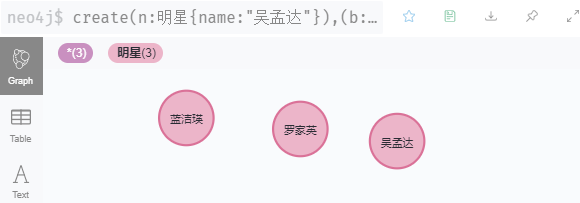
c 多个节点 create
// 这个是同时创建多个节点,n 是变量,可以在运行后直接显示创建的节点,但不能每个节点都一样
create(n:明星{
name:"吴孟达"}),(b:明星{
name:"罗家英"}),(c:明星{
name:"蓝洁瑛"}) return n,b,c
一般情况下推荐用 merge
d merge
merge 是合并,融合的意思,用它创建节点关系,它会事先检查数据库是否含有相同的属性和标签的节点,如果含有就不会创建新的节点。
// 单个创建和 create 一样
merge(:明星{name:"刘德华"})

可以看到没有改变,因为之前已经创建了 刘德华 的节点了
// 下面和create对应,不过不会重复节点了
// 属性
merge(a:明星{name:"刘德华"}) return a// 多个创建不使用逗号隔开,而是重写 merge
merge(n:明星{name:"吴孟达"}) merge(b:明星{name:"罗家英"}) return n,b
e 多个属性
##
merge(a:明星{name:"周星驰",出生日期:'1962-06-22'}) return amerge(a:明星{name:"吴孟达",出生日期:'1952-01-02'}) return a

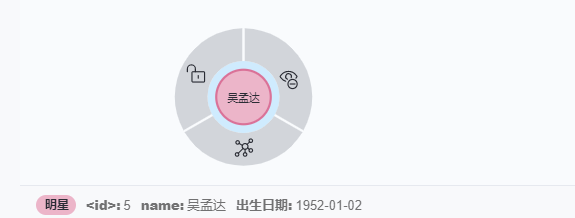
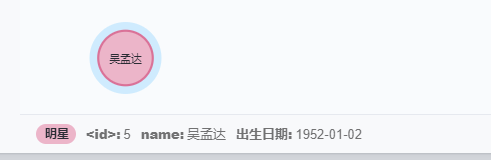
注意,使用merge时遇上多属性,即使前面所有节点属性相同,只要有属性不一样,也会创建新节点,如上面图,之前已经建立 吴孟达 的节点,id是1,但这里id是5
异常
// 在浏览器创建不会显示'大话西游',节点标签最好是英文,
// 即外面的 电影 改为英文
merge (a:电影{电影:'大话西游'}) return a
// 下面几种情况也不行
merge (a:电影{name:'大话西游'}) return a
merge (a:film{name:'大话西游'}) return a
改为
merge (a:film{电影:'大话西游'}) return a

1.2 查询节点
先学习一下查询,因为建立关系一般需要查询节点获取节点对象
查询 MATCH 经常需要与其他的语句配合才可以使用.
a
MATCH (n:明星{name:'周星驰'}) RETURN n
或
MATCH (n:'明星'{name:'周星驰'}) RETURN n

b
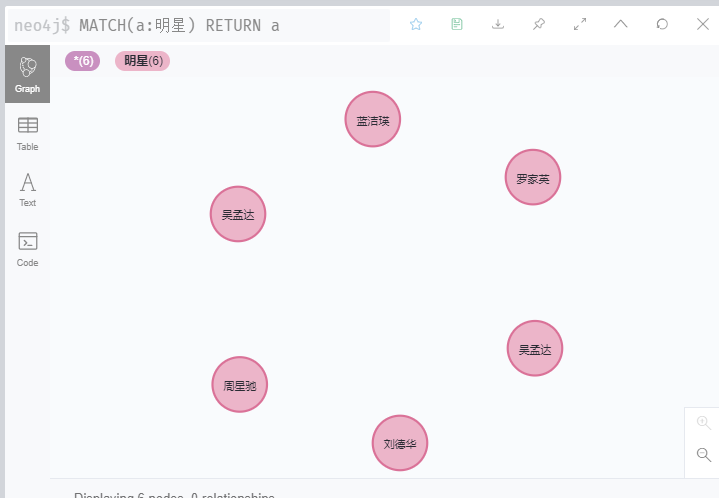
// 匹配 节点标签为 《申请人》 的结点
MATCH(a:明星)
RETURN a
c
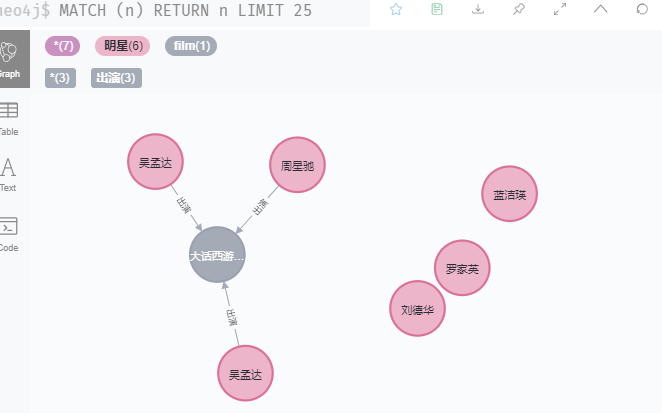
// 匹配所有的结点,并限定显示 25 个节点,如果节点有关系也会显示出来
MATCH (n) RETURN n LIMIT 25
d
// 先匹配出所有 结点标签为 《申请人》 的节点,再筛选出 属性为申请人="邹继富" 的结点,最后返回
MATCH(a:明星{})
WHERE a.name="吴孟达"
RETURN a
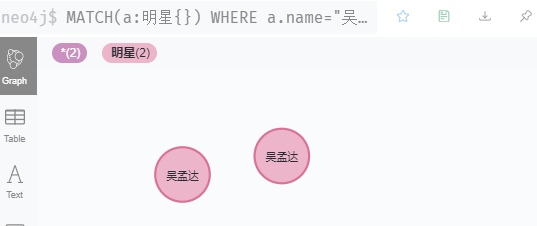
// 多标签
match (n:明星{name:'吴孟达',出生日期:'1952-01-02'}) return n
2 关系
2.1 创建关系
**a **
创建节点的同时创建关系
merge (n:明星{name:"周星驰"}) merge (m:film{电影:"大话西游之月光宝盒"}) merge (n)-[r:出演]->(m) return r
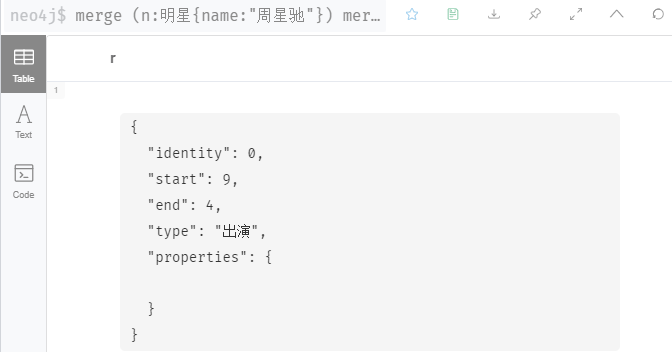
查看关系
b 先匹配 获取节点对象,再创建关系
MATCH(a:明星),(b:film)
WHERE a.name="吴孟达" AND b.电影="大话西游之月光宝盒"
CREATE(a)-[r:出演]->(b) RETURN r

因为有两个吴孟达节点,所以有两个关系
c 创建多关系
一起创建多条关系,关系属性标识符 如 r != re
match (m:明星{name:'周星驰'}) match(n:明星{name:'吴孟达'}) merge (m)-[r:认识]->(n) merge (n)-[re:认识]->(m)
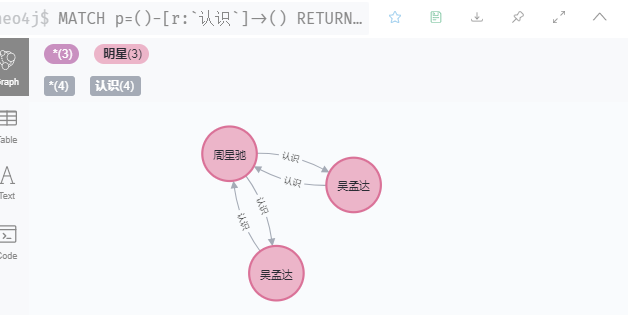
2.2 查询关系
前面已经建立以下关系
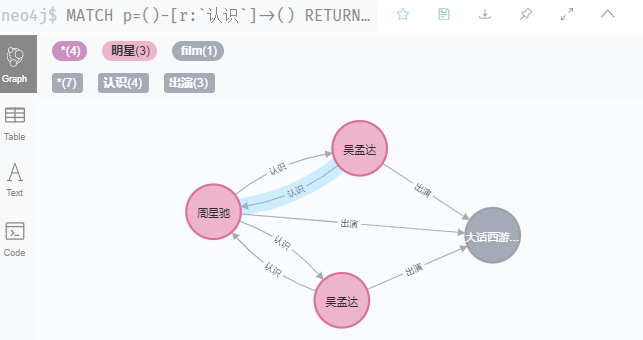
a 根据节点和关系的详细信息查询返回图表
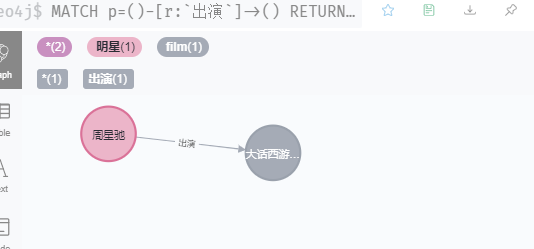
match(:`明星`{name:'周星驰'})-[r:`出演`]->(:film{`电影`:'大话西游之月光宝盒'}) return r
// 下面格式也可以
match(:明星{name:'周星驰'})-[r:出演]->(:film{电影:'大话西游之月光宝盒'}) return r
返回以下图表说明成功
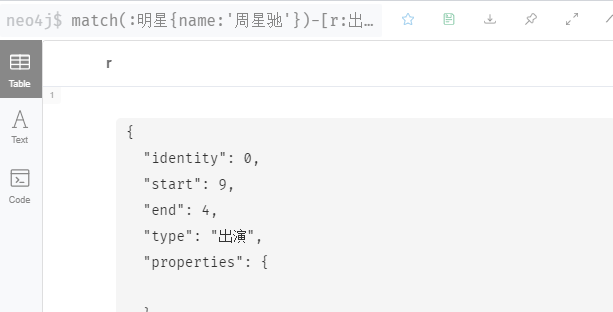
b 根据节点和关系的详细信息查询返回节点图
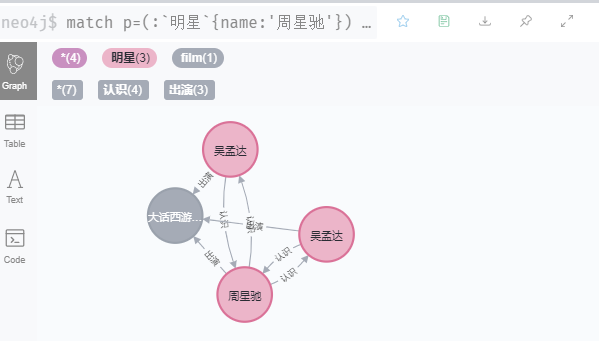
match p=(:明星{name:'周星驰'})-[r:出演]->(:film{电影:'大话西游之月光宝盒'}) return p
可以通过增加或减少节点条件,改变关系条件,获取更丰富的关系信息

c 查询一个节点所有关系
match p=(:`明星`{name:'周星驰'})-->() return p
d 查询一种关系
MATCH p=()-[r:`出演`]->() RETURN p
// 限制显示两条关系
MATCH p=()-[r:`出演`]->() RETURN p limit 2
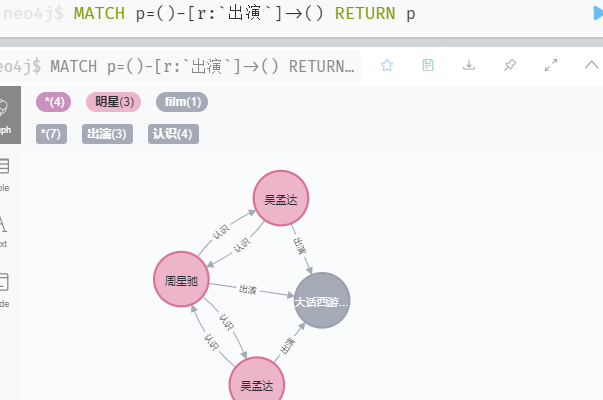
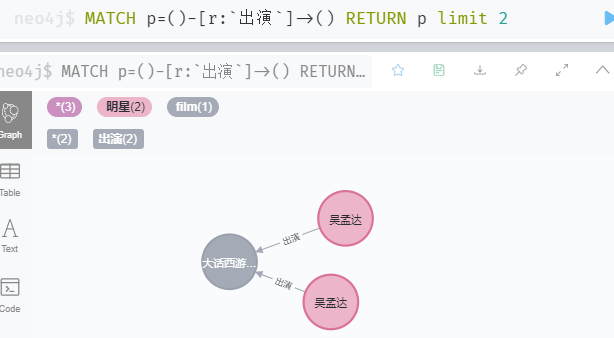
e 查询所有关系,限制显示25条
MATCH p=()-->() RETURN p LIMIT 25
3 删除
可以查询并return的都可以delete,只不过把
return改为delete
3.1 删除节点
// 先匹配出所有 结点标签为 《明星》 的节点,再筛选出 属性为申请人="周星驰" 的结点,最后删除,有关系的不能删除
MATCH(a:明星)
WHERE a.name="周星驰"
DELETE a
弹出错误,因为节点有关系

MATCH(a:明星)
WHERE a.name="罗家英"
DELETE a

3.2 删除关系
a
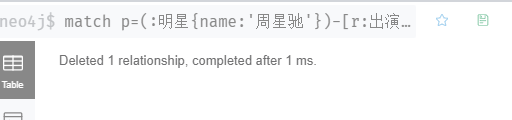
match p=(:明星{name:'周星驰'})-[r:出演]->(:film{电影:'大话西游之月光宝盒'}) delete r
b 删除关系同时删除连接的节点,如果节点还有其他关系就会弹出错误
merge (n:明星{name:"迪丽热巴"}) merge (m:粉丝{name:"我"}) merge (m)-[r:喜欢]->(n) merge (n)-[re:喜欢]->(m)// 删除关系同时删除连接的节点,如果节点还有其他关系就会弹出错误
MATCH p=()-[r:`喜欢`]->() delete p
3.3 删除所有节点关系,清空数据库
a
适合少量数据
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
DELETE n,r
MATCH (n)
WITH n LIMIT 1000000
DETACH DELETE n
b
match (n) detach delete n
4 set 增添修改属性
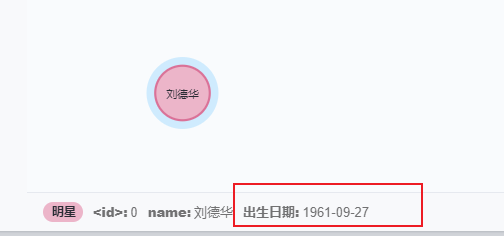
// 增添`出生日期`,如果有了就修改
match (n:`明星`{name:'刘德华'})
set n.`出生日期`='1961-09-27'
return n
中文版neo4j
1.创建图片节点
// 图片是在线的
CREATE (张帜:人员 {名称:"张帜", image:"http://we-yun.com/image/作者/张帜.jpg"})
// 只能使用http开头的网络,我用的是 4.2.1 版本
参考
Neo4j 第三篇:Cypher查询入门