摘要
置信度校正——预测代表真实正确性似然(可能性)的概率估计问题,在许多应用中对分类模型是重要的。
通过大量的实验,我们观察到深度网络的深度、宽度、权重衰减和批归一化是影响校准的重要因素。
在这篇文章中,还提出了一种基于早期置信度校准方法Platt scaling的变式——temperature scaling
一.引言
校准的概率的重要性
- 分类网络不仅需要准确,还需要知道什么时候是不正确的。
- 在一些实际应用中,人们需要可靠的模型进行判断,而不是单纯的需要一个高准确率的模型.以自动驾驶为例,检测网络应该对检测出的障碍物出现与否的概率非常地自信,这样驾驶员才能放心根据模型输出的概率进行判断.然后,模型也不能盲目地给一个不确定地目标很高的置信度,而是应该给到一个低的置信度,这样汽车应该更多地依靠其他传感器的输出来制动.
- 另外,好的概率估计也可以使神经网络纳入概率模型中.
存在问题
- 现在的深度模型相比之前而言存在过自信的问题.
二.定义
- 输入 X
- 标签 Y 有K个类别
- 模型 h 有h(X)=(\hat(Y),\hat(P))
- 置信度校准问题定义:

- 评级指标:
①Reliability Diagram
②ECE
③MCE
④NLL
三. 模型失准原因分析
①模型容量
通过神经网络的层数(深度),以及每一层滤波器的数量(宽度)来体现.模型越深越宽,校准性可能越低
②批归一化
经过批归一化的网络更容易变得不校准,且和使用的模型超参没有关系。
③权重衰退
作为一种深度网络训练的正则化手段。权重衰减较小的训练会给校准带来负面影响
④NLL
NLL损失和准确度之间关系可能不大,这种断开是因为神经网络可以过拟合NLL而不会过拟合0/1损耗。高容量的模型并不能避免过拟合导致的概率误差,而不是分类误差
This phenomenon renders a concrete explanation of miscalibration: the network learns better classification accuracy at the expense of well-modeled probabilities.
四、校准方法
这里的方法主要都是后处理的方法,需要先划分出一个held-out validation数据集,在这个基础上进行参数优化。
4. 1 二分类模型
- histagram binning
- Isotonic regression
- Beyesian Binning into Quantiles
- Platt Scaling
(具体详见我另一篇博文几种经典概率校准方法(Platt scaling、 histogram binning、 isotonic regression、 temperature scaling)_ROYOLE'S-CSDN博客![]() https://blog.csdn.net/royole98/article/details/120503829?spm=1001.2014.3001.5501)
https://blog.csdn.net/royole98/article/details/120503829?spm=1001.2014.3001.5501)
4. 2 多分类模型拓展
- Matrix and vector Scaling
对输出logits做线性变化
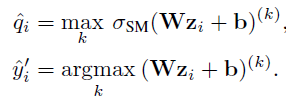
- Temperature Scaling

该模型等价于输出概率分布的熵值最大化,并受对数的约束
4. 3相关工作:
Calibration and confidence scores have been studied in various contexts in recent years.
- 对抗学习
- 结构化目标
- 集成学习
- 正则化
- 检测分布外样本
- 贝叶斯网络——和dropout之间的联系
相比之下,我们的框架没有扩充神经网络模型,它返回的是一个置信度评分,而不是可能输出的分布。