1. 引言
1.1 神经网络的术语
-
1.偏置bias
-
2.激活函数:
sigmoid函数;tanh函数;Relu函数。
- 3.损失函数:
最小平方误差准则(MSE)、交叉熵(cross-entropy)、对数似然函数(log-likelihood)、指数损失函数(exp-loss)、Hinge损失函数(Hinge-loss)、0-1损失函数、绝对值损失函数
- 4.反向传播优化算法:
随机梯度下降(SGD)、动量(Momentum)、涅斯捷罗夫(Nesterov)算法、Adagrad、Adadelta、Adam、Adamax、Nadam.
1.2 损失函数TensorFlow语句
#mse
mse = tf.reduce_sum(tf.square(y_ - y))
#交叉熵
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
#softmax回归后的交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y,y_)
1.3 神经网络的实现过程
-提取实体的特征向量;
-定义神经网络的结构;
-用训练数据得到参数;
-训练好后预测未知数据;
2. 前向传播算法实现
知识点:
1、x=tf.constant([[0.7,0.9]])代表shape[1,2]?等价于
x=tf.constant([0.7,0.9],shape[1,2])
2.2 示例2
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 10 21:53:08 2017@author: RoFun
"""import tensorflow as tfw1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
#b1=tf.Variable(tf.constant(0,shape=[3]))w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#b2=tf.Variable(tf.constant(0,shape=[1]))#x=tf.constant([[0.7,0.9]])
x = tf.placeholder(tf.float32,name='input')a=tf.matmul(x,w1)
y=tf.matmul(a,w2)sess=tf.Session()
init_op=tf.global_variables_initializer()
sess.run(init_op)print(sess.run(y,feed_dict={
x:[[0.7,0.9]]}))
sess.close()
运行结果
runfile('G:/tensorflow/qianxiang.py', wdir='G:/tensorflow')
[[ 3.95757794]]
知识点:
1.使用tf.placeholder()来存放输入数据,可以不定义shape属性;
2、feed_dict是placeholder用到的取值字典(map);
3. 神经网络模型训练
上一节使用的神经网络结构,给定的参数都是随机的,在使用神经网络解决实际的分类、回归问题,我们往往需要采用监督方式来获得结构的参数。
3.1模型训练步骤
训练的步骤:
1、定义神经网络的结构和前向传播输出结果;
2、定义损失函数和反向传播算法优化;
3、生成会话,并在训练数据上反复运行反向传播优化算法。
#定义损失函数
cross_entropy=-tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,e-10,1.0)))
#定义学习率
learning_rate=0.001
#定义反向传播算法
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
3.2 demo
这个demo是线性处理数据的神经网络结构。
#完整神经网络样例程序
import tensorflow as tf
from numpy.random import RandomState#1. 定义神经网络的参数,输入和输出节点。
batch_size = 8
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
x = tf.placeholder(tf.float32, shape=(None, 2), name="x-input")
y_= tf.placeholder(tf.float32, shape=(None, 1), name='y-input')#2. 定义前向传播过程,损失函数及反向传播算法。
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)#3. 生成模拟数据集。
rdm = RandomState(1)
X = rdm.rand(128,2)
Y = [[int(x1+x2 < 1)] for (x1, x2) in X]#4. 创建一个会话来运行TensorFlow程序。
with tf.Session() as sess:init_op = tf.global_variables_initializer()sess.run(init_op)# 输出目前(未经训练)的参数取值。print("w1:", sess.run(w1))print("w2:", sess.run(w2))print("\n")# 训练模型。STEPS = 5000for i in range(STEPS):start = (i*batch_size) % 128end = (i*batch_size) % 128 + batch_sizesess.run(train_step, feed_dict={
x: X[start:end], y_: Y[start:end]})if i % 1000 == 0:total_cross_entropy = sess.run(cross_entropy, feed_dict={
x: X, y_: Y})print("After %d training step(s), cross entropy on all data is %g" % (i, total_cross_entropy))# 输出训练后的参数取值。print("\n")print("w1:", sess.run(w1))print("w2:", sess.run(w2))
输出结果
w1: [[-0.81131822 1.48459876 0.06532937][-2.4427042 0.0992484 0.59122431]]
w2: [[-0.81131822][ 1.48459876][ 0.06532937]]After 0 training step(s), cross entropy on all data is 0.0674925
After 1000 training step(s), cross entropy on all data is 0.0163385
After 2000 training step(s), cross entropy on all data is 0.00907547
After 3000 training step(s), cross entropy on all data is 0.00714436
After 4000 training step(s), cross entropy on all data is 0.00578471w1: [[-1.9618274 2.58235407 1.68203783][-3.46817183 1.06982327 2.11788988]]
w2: [[-1.8247149 ][ 2.68546653][ 1.41819513]]
知识点:
1. tf.reduce_mean(input_tensor, reduction_indices=None, keep_dims=False, name=None)功能:求平均值参数1--input_tensor:待求值的tensor。参数2--reduction_indices:在哪一维上求解。2.常用优化函数:
tf.train.GradientDescentOptimizer
tf.train.AdamOptimizer()
tf.train.MomentumOptimizer()
4. 完整前向神经网络样例
4.1 示例1
下面的程序还是使用线性的神经网络,从CSV文件读取数据。
#-基于神经网络模型预测
#完整神经网络样例程序
import tensorflow as tf
from numpy.random import RandomState#1. 定义神经网络的参数,输入和输出节点。
batch_size = 8w1= tf.Variable(tf.random_normal([6, 7], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([7, 1], stddev=1, seed=1))
x = tf.placeholder(tf.float32, name="x-input")
y_= tf.placeholder(tf.float32, name='y-input')#2. 定义前向传播过程,损失函数及反向传播算法。
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
#cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))) mse = tf.reduce_sum(tf.square(y_ - y))
#train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
train_step = tf.train.AdamOptimizer(0.001).minimize(mse)# #3. 生成模拟数据集。
# rdm = RandomState(1)
# X = rdm.rand(128,2)
# Y = [[int(x1+x2 < 1)] for (x1, x2) in X]#3.读取csv至字典x,y
import csv# 读取csv至字典
csvFile = open(r'G:\训练小样本.csv', "r")
reader = csv.reader(csvFile)
# 建立空字典
result = {
}
i=0
for item in reader:if reader.line_num==1:continueresult[i]=itemi=i+1# 建立空字典
j=0
xx={
}
yy={
}
for i in list(range(29)):xx[j]=result[i][1:-1]yy[j]=result[i][-1]j=j+1csvFile.close()##3.1字典转换成list
X=[]
Y=[]
for i in xx.values():X.append(i)
for j in yy.values():Y.append(j) #4. 创建一个会话来运行TensorFlow程序。
with tf.Session() as sess:init_op = tf.global_variables_initializer()sess.run(init_op)# 输出目前(未经训练)的参数取值。print("w1:", sess.run(w1))print("w2:", sess.run(w2))print("\n")# 训练模型。STEPS = 4for i in range(STEPS):start = (i*batch_size) % 29end = (i*batch_size) % 128 + batch_sizesess.run(train_step, feed_dict={
x: X[start:end], y_: Y[start:end]})# total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y})# print("After %d training step(s), cross entropy on all data is %g" % (i, total_cross_entropy))total_mse=sess.run(mse,feed_dict={
x: X, y_: Y})print("After %d training step(s), mse on all data is %g" % (i, total_mse))# 输出训练后的参数取值。print("\n")print("w1:", sess.run(w1))print("w2:", sess.run(w2))示例2
下面的demo主要加了bias和激活函数(activation),从而可以处理非线性的问题。
import tensorflow as tf#weights=tf.Variable(tf.random_normal([2.0,3.0],stddev=2))w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
b1=tf.Variable(tf.constant(0.0,shape=[3]))w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
b2=tf.Variable(tf.constant(0.0,shape=[1]))x=tf.constant([[0.7,0.9]])a=tf.nn.relu(tf.matmul(x,w1)+b1)
y=tf.nn.relu(tf.matmul(a,w2)+b2)
sess=tf.Session()init_op=tf.global_variables_initializer()
sess.run(init_op)print(sess.run(y))
sess.close()
5. 神经网络优化算法
下面将简单介绍反向传播算法。
反向传播算法,是使用一些优化算法,如梯度下降法,来优化网络的所有参数。
5.1 梯度下降法
公式:
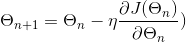
5.2 随机梯度下降法(stochastic gradient descent)
使用梯度下降法,往往存在计算量大的问题,为此,我们使用了随机梯度下降(SGD)。
SGD, 每次只取一个或者一部分样本进行训练,比起每次随机取一个样本的方法 训练波动更小,更加稳定,更加高效,这基本上是最常用的一种优化方法。
5.3 学习率的设置
#学习率的设置import tensorflow as tf
TRAINING_STEPS = 10
LEARNING_RATE = 1
x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x")
y = tf.square(x)train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y)with tf.Session() as sess:sess.run(tf.global_variables_initializer())for i in range(TRAINING_STEPS):sess.run(train_op)x_value = sess.run(x)print("After %s iteration(s): x%s is %f."% (i+1, i+1, x_value))
5.4 正则化处理过拟合问题
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as npdata = []
label = []
np.random.seed(0)# 以原点为圆心,半径为1的圆把散点划分成红蓝两部分,并加入随机噪音。
for i in range(150):x1 = np.random.uniform(-1,1)x2 = np.random.uniform(0,2)if x1**2 + x2**2 <= 1:data.append([np.random.normal(x1, 0.1),np.random.normal(x2,0.1)])label.append(0)else:data.append([np.random.normal(x1, 0.1), np.random.normal(x2, 0.1)])label.append(1)data = np.hstack(data).reshape(-1,2)
label = np.hstack(label).reshape(-1, 1)
plt.scatter(data[:,0], data[:,1], c=label,cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.show()def get_weight(shape, lambda1):var = tf.Variable(tf.random_normal(shape), dtype=tf.float32)tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lambda1)(var))return varx = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
sample_size = len(data)# 每层节点的个数
layer_dimension = [2,10,5,3,1]n_layers = len(layer_dimension)cur_layer = x
in_dimension = layer_dimension[0]# 循环生成网络结构
for i in range(1, n_layers):out_dimension = layer_dimension[i]weight = get_weight([in_dimension, out_dimension], 0.003)bias = tf.Variable(tf.constant(0.1, shape=[out_dimension]))cur_layer = tf.nn.elu(tf.matmul(cur_layer, weight) + bias)in_dimension = layer_dimension[i]y= cur_layer# 损失函数的定义。
mse_loss = tf.reduce_sum(tf.pow(y_ - y, 2)) / sample_size
tf.add_to_collection('losses', mse_loss)
loss = tf.add_n(tf.get_collection('losses'))# 定义训练的目标函数mse_loss,训练次数及训练模型
train_op = tf.train.AdamOptimizer(0.001).minimize(mse_loss)
TRAINING_STEPS = 40000with tf.Session() as sess:tf.global_variables_initializer().run()for i in range(TRAINING_STEPS):sess.run(train_op, feed_dict={
x: data, y_: label})if i % 2000 == 0:print("After %d steps, mse_loss: %f" % (i,sess.run(mse_loss, feed_dict={
x: data, y_: label})))# 画出训练后的分割曲线 xx, yy = np.mgrid[-1.2:1.2:.01, -0.2:2.2:.01]grid = np.c_[xx.ravel(), yy.ravel()]probs = sess.run(y, feed_dict={
x:grid})probs = probs.reshape(xx.shape)plt.scatter(data[:,0], data[:,1], c=label,cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.contour(xx, yy, probs, levels=[.5], cmap="Greys", vmin=0, vmax=.1)
plt.show()
5.5 滑动平均模型(指数滑动平均)
#滑动平均模型import tensorflow as tfv1 = tf.Variable(0, dtype=tf.float32)
step = tf.Variable(0, trainable=False)
ema = tf.train.ExponentialMovingAverage(0.99, step)
maintain_averages_op = ema.apply([v1]) with tf.Session() as sess:# 初始化init_op = tf.global_variables_initializer()sess.run(init_op)print(sess.run([v1, ema.average(v1)]))# 更新变量v1的取值sess.run(tf.assign(v1, 5))sess.run(maintain_averages_op)print(sess.run([v1, ema.average(v1)]))# 更新step和v1的取值sess.run(tf.assign(step, 10000)) sess.run(tf.assign(v1, 10))sess.run(maintain_averages_op)print(sess.run([v1, ema.average(v1)])) # 更新一次v1的滑动平均值sess.run(maintain_averages_op)print(sess.run([v1, ema.average(v1)]))
运行结果:
[0.0, 0.0]
[5.0, 4.5]
[10.0, 4.5549998]
[10.0, 4.6094499]
知识点:
1.tf.train.ExponentialMovingAverage(decay, step):这个函数用来生成影子变量,decay为衰减率;step,是影响decay的一个参数;
6. 基于反向传播算法的深层神经网络实现
#tch-基于深层神经网络实现#天池-基于神经网络模型预测import tensorflow as tf
from numpy.random import RandomState#1. 定义神经网络的参数,输入和输出节点。
batch_size = 8# w1= tf.Variable(tf.random_normal([5, 7], stddev=1, seed=1))
# w2= tf.Variable(tf.random_normal([7, 1], stddev=1, seed=1))
x = tf.placeholder(tf.float32, name="x-input")
y_= tf.placeholder(tf.float32, name='y-input')
# b1=tf.Variable(tf.constant([0.0,0.0,0.0,0.0,0.0,0.0,0.0],shape=[7]))
# b2=tf.Variable(tf.constant(0.0,shape=[1]))#2.1计算3层神经网络L2正则化的损失函数def get_weight(shape, lambda1):var = tf.Variable(tf.random_normal(shape), dtype=tf.float32)tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lambda1)(var))return varsample_size = 8
# 每层节点的个数
layer_dimension = [5,7,1]n_layers = len(layer_dimension)#3cur_layer = x
in_dimension = layer_dimension[0] #2# 循环生成网络结构
for i in range(1, n_layers):out_dimension = layer_dimension[i]weight = get_weight([in_dimension, out_dimension], 0.003)bias = tf.Variable(tf.constant(0.1, shape=[out_dimension]))cur_layer = tf.nn.elu(tf.matmul(cur_layer, weight) + bias)in_dimension = layer_dimension[i]y= cur_layer# 正则化损失函数的定义。
mse_loss = tf.reduce_sum(tf.pow(y_ - y, 2)) / sample_size
tf.add_to_collection('losses', mse_loss)
loss = tf.add_n(tf.get_collection('losses'))
#train_step = tf.train.AdamOptimizer(0.001).minimize(loss)TRAINING_STEPS = 10
#LEARNING_RATE = 1
global_step=tf.Variable(0)
LEARNING_RATE=tf.train.exponential_decay(0.8,global_step,100,0.96,staircase=True)
train_step = \
tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(loss,global_step=global_step)#2.3.读取csv至字典x,y
import csv# 读取csv至字典
csvFile = open(r'G:\训练小样本.csv', "r")
reader = csv.reader(csvFile)# 建立空字典
result = {
}
i=0
for item in reader:if reader.line_num==1:continueresult[i]=itemi=i+1# 建立空字典
j=0
xx={
}
yy={
}
for i in list(range(29)):xx[j]=result[i][1:-1]yy[j]=result[i][-1]# print(x[j])# print(y[j])j=j+1csvFile.close()##字典转换成list
X=[]
Y=[]
for i in xx.values():X.append(i)for j in xx.values():X.append(j) #4. 创建一个会话来运行TensorFlow程序。
with tf.Session() as sess:init_op = tf.global_variables_initializer()sess.run(init_op)# 输出目前(未经训练)的参数取值。print("w1:", sess.run(weight[0]))print("w2:", sess.run(weight[1]))print("\n")STEPS = 4for i in range(STEPS):start = (i*batch_size) % 29end = min((i*batch_size) % 29 + batch_size,29)sess.run(train_step, feed_dict={
x: X[start:end], y_: Y[start:end]})total_loss = sess.run(loss, feed_dict={
x: X, y_: Y})print("After %d training step(s), loss on all data is %g" % (i, total_loss)) # 输出训练后的参数取值。print("\n")print("w1:", sess.run(weight[0]))print("w2:", sess.run(weight[1]))运行结果:
w1: [-0.90025067]
w2: [-0.61561918]After 0 training step(s), loss on all data is 0.0724032
After 1 training step(s), loss on all data is 0.0720561
After 2 training step(s), loss on all data is 0.0717106
After 3 training step(s), loss on all data is 0.0713668w1: [-0.89163929]
w2: [-0.60973048]
现在对于29*6维的x,采用了两层神经网络,效果不是很好。
后来,采用了127个样本,并且把训练的次数提高到1000,效果明显:
修改部分的代码:
#4. 创建一个会话来运行TensorFlow程序。
with tf.Session() as sess:init_op = tf.global_variables_initializer()sess.run(init_op)# 输出目前(未经训练)的参数取值。print("w1:", sess.run(weight[0]))print("w2:", sess.run(weight[1]))print("\n")STEPS = 1000for i in range(STEPS):start = (i*batch_size) % data_sizeend = min((i*batch_size) % data_size + batch_size,data_size)sess.run(train_step, feed_dict={
x: X[start:end], y_: Y[start:end]})if i%200==0:total_loss = sess.run(loss, feed_dict={
x: X, y_: Y})print("After %d training step(s), loss on all data is %g" % (i, total_loss)) # 输出训练后的参数取值。print("\n")print("w1:", sess.run(weight[0]))print("w2:", sess.run(weight[1]))
运行的结果,只给出两个权重:
w1: [-0.38975346]
w2: [ 0.13079379]After 0 training step(s), loss on all data is 0.0602596
After 200 training step(s), loss on all data is 0.023503
After 400 training step(s), loss on all data is 0.00986995
After 600 training step(s), loss on all data is 0.00443687
After 800 training step(s), loss on all data is 0.00212367w1: [-0.05206319]
w2: [ 0.01747141]
采用了5000个steps,基本上是收敛了:
w1: [ 1.00491798]
w2: [ 0.45586446]After 0 training step(s), loss on all data is 0.0393548
After 1000 training step(s), loss on all data is 0.000703361
After 2000 training step(s), loss on all data is 4.84807e-05
After 3000 training step(s), loss on all data is 8.19349e-06
After 4000 training step(s), loss on all data is 2.51321e-06w1: [ 0.00541062]
w2: [ 0.00245444]
7. 关于神经网络模型不收敛
- 把learning rate设小;
- 数据归一化。
最近开通了个公众号,主要分享深度学习相关内容,推荐系统,风控等算法相关的内容,感兴趣的伙伴可以关注下。

公众号相关的学习资料会上传到QQ群596506387,欢迎关注。
参考:
- 神经网络playground;
- TensorFlow实现前向传播过程_知乎专栏;
- 3种激活函数;
- 4种损失函数;
- TensorFlow损失函数
- 机器学习-损失函数(很全);
- 反向传播优化算法;
- TensorFlow神经网络模型不收敛的处理