本文总结了卷积神经网络发展过程中比较有代表性的网络结构。
1、LeNet
《Gradient-based learning applied to document recognition》
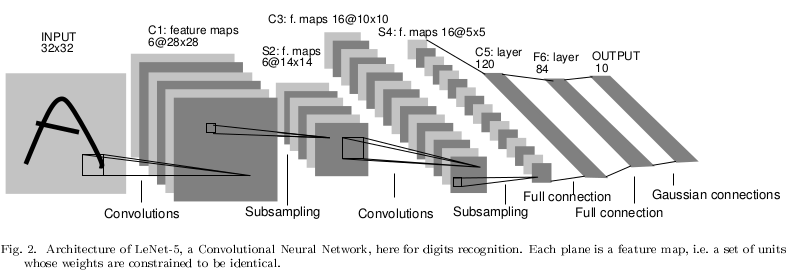
LeNet是最早的卷积神经网络之一,结构如下图所示。
2、AlexNet
AlexNet(《ImageNet Classification with Deep Convolutional Neural Networks》,作者是Alex Krizhevsky,I Sutskever,G Hinton)是深度学习发展史上的一个重要里程碑,在2012 ILSVRC test set上top1错误率37.5%,top5错误率17.0%。
创新点:
1) 使用ReLUs激活函数
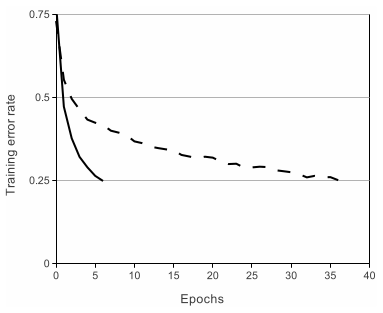
ReLUs(Rectified Linear Units)相比起以前的激活函数,训练收敛速度更快。下图中实线条是使用ReLUs对应的训练曲线,虚线是使用tanh的曲线,同样是到达训练错误率25%,使用tanh消耗的时间是使用ReLUs消耗时间的6倍。
2) 局部响应归一化LRN(Local Response Normalization)
LRN的灵感来源是神经元的侧抑制,具体公式如下:
其中N是该层卷积核的个数,是第
个卷积核输出的特征图上
位置,经过了ReLUs激活之后的值。论文中使用的参数是k=2,n=5,
,
。
3) Overlapping Pooling
传统的池化是步长和池化窗口宽度一样大,这篇文章中作者使用的池化窗口宽度为3,步长为2。
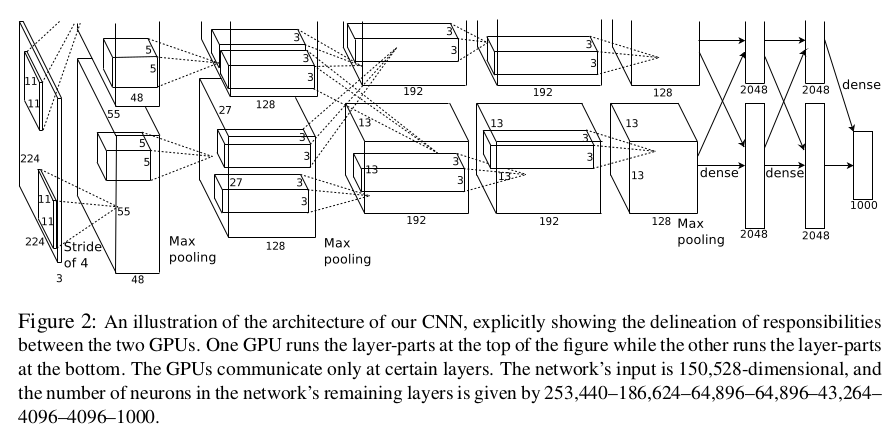
4) 网络的总体架构如下图所示。总共8层,5个卷积层,3个全连接层,实际最后1000个节点后面实际上还有一个softmax层。第2个,第4个和第5个卷积层只和同一个GPU上前一个卷积层相连,第3个卷积层和第2个卷积层所有的神经元互相连接,第1层和第2层后面有LRN,第1,第2和第5层后面有最大池化,激活函数全部使用ReLUs。
5) 论文中使用了数据增强和dropout两种方法来抑制过拟合
数据增强有两种方式,第一种是在256*256的图中随机抽取224*224的区域,这样可以增加1024倍的数据量,再加上水平翻转,数据量增加了2048倍,当然这样产生的训练集数据中存在highly interdependent,因为有的图片之间只有左右最外侧像素不同。在test的时候,取图像的四个角和中心patch,以及水平翻转共10个patches,将这10个patches输出的softmax求均值,作为最终的预测结果。数据增强的第二种方法稍微复杂一点,基本思想是物体的同一性对照明强度和颜色具有不变性。
将多个不同的模型输出组合在一起,可以降低test errors,然而这样做的成本比较高。dropout方法指的是以概率q使得神经元输出值为0,在测试阶段,给神经元的输出乘以1-q。使用dropout的收敛速度几乎是不使用dropout的两倍。
还有一种Inverted Dropout,是在训练过程中给神经元的输出乘以1/p,其中p=1-q,p就是tensorflow中的keep_prob参数,这种方法的好处是测试的时候神经元输出值不用乘以参数。
6) 模型训练
Our network maximizes the multinomial logistic regression objective, which is equivalent to maximizing the average across training cases of the log-probability of the correct label under the prediction distribution.
使用stochastic gradient descent进行训练,batch size为128,momentum为0.9,weight decay为0.0005。初始化所有参数为均值0,标准差0.01的随机数。第2,第4和第5个卷积层,以及所有的全连接层biases设置为1,这样做的目的是在训练的早期给ReLUs提供正值输入,其余层biases设置为0。初始学习率为0.01,当validation error rate不改善的时候,给学习率除以10,学习率下降三次之后停止训练。
3、VGGNet
vgg最早出现在论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》,作者 Karen Simonyan, Andrew Zisserman,在2014 ILSVRC上和GooLeNet同台竞技。
1) 输入为224*224*3,卷积核为3*3,步长1。总共5个最大池化层,不是每一层卷积后面都有池化,池化窗口为2*2,步长2。3个全连接层,前两个全连接层各有4096个通道,最后一个全连接层有1000个通道,对应1000类输出。在全连接层后面是softmax层。激活函数使用的ReLU。卷积层通道数量开始是64,每次池化之后乘以2,直到512个通道为止。论文中定义了6种网络架构,如下图所示,不同的架构主要的区别在于网络深度。
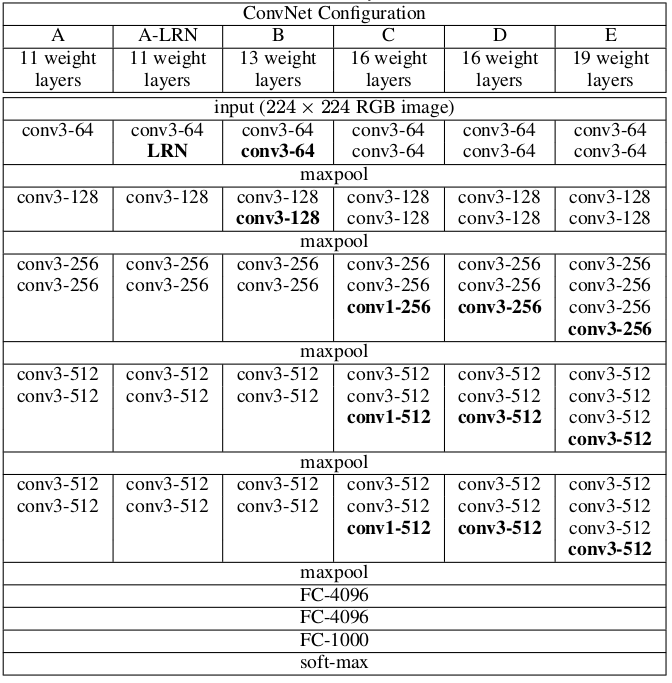
2) 证明了局部响应归一化(LRN,Local Response Normalisation)并不能提升ILSVRC数据集上的准确度,反而会增加内存消耗和时间消耗。
3) 在没有池化的情况下,2层3*3的卷积和一层5*5的卷积感受野一样大,3层3*3的卷积和一层7*7的卷积感受野一样大。使用多个3*3卷积具有两点优势:1、引入了3个非线性激活函数,使得决策函数分辨能力更强。2、网络参数大大降低,例如3层3*3的卷积层,每层有C个通道,那么包含的参数个数为,而1层7*7的卷积参数数量为
。相比而言,1层7*7卷积比3层3*3卷积参数多了81%以上。
4) 1*1卷积是一种不影响卷积层的感受野的情况下,增加决策函数非线性的方法。
5) 网络训练过程中,目标函数multinomial logistic regression objective,优化方法mini-batch gradient descent with momentum,batch size为256,momentum为0.9。正则化使用了weight decay(L2 惩罚乘子设置为5*10^-4),前两个全连接层使用dropout(dropout ratio为0.5)。学习率初始值为0.01,当validation set的准确率不变的时候,给学习率除以10(decreased by a factor of 10)。权值初始化值来自均值为0方差为0.01的正态分布,biases初始化为0。
4、ResNet
Our ensemble has 3.57% top-5 error on the ImageNet test set, and won the 1st place in the ILSVRC 2015 classification competition.
Kaiming He等人2015年在论文《Deep Residual Learning for Image Recognition》中提出了ResNet。根据以往的研究,似乎网络更深,训练效果就会更好,作者在论文的开始提出了这样一个问题。
Is learning better networks as easy as stacking more layers?
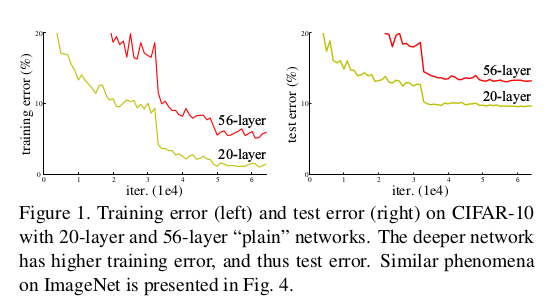
上述这个问题主要的困难在于梯度消失和梯度爆炸,对于tens of layers的网络,normalized initialization和增加BN层能够很大程度的解决梯度消失和爆炸,使用SGD就能使网络收敛。但是随着网络深度的增加,出现了退化的现象:随着网路加深,准确率出现饱和(accuracy gets saturated)。这个现象不是过拟合造成的,只要给一个深度适当的网络增加新的层就会导致训练准确率下降。如下图所示,更深的层并没有带来更好的训练效果。
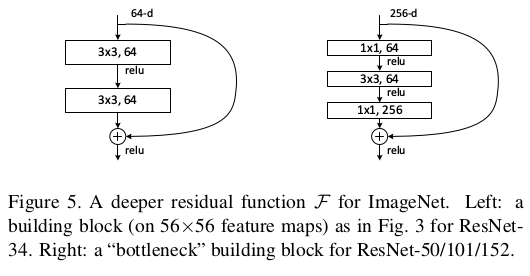
论文提出了一种残差结构,如下图所示。在神经网络中实际上学习的是输入和输出之间潜在的映射函数,将这个函数记为,残差结构目的是学习另外一种映射:
,论文里假设残差
比
更好训练。

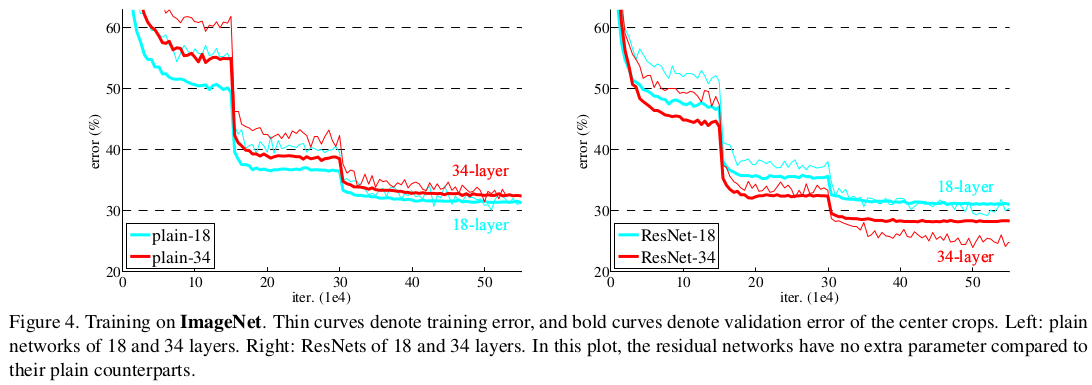
论文里训练了18层和34层的plain网络(类似于vgg网络的结构)和对应的残差网络,训练和验证的结果如下图。可以看出18层的plain网络训练和验证错误率均小于34层plain网络,说明plain结构中增加网络层数发生了退化现象。而34层的残差网络训练和验证错误率均小于18层的残差网络,说明残差网络解决了退化的问题。
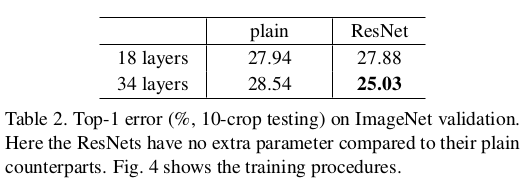
具体的准确率如下所示,可以看出18层plain网络和18层残差网络最终到达的测试误差率相差不大,说明SGD在较浅层的网络上也能得到较好的收敛,但是结合上面的图可以看出,残差网络收敛速度更快,残差网络在层数较少时仍然占有优势。
残差网络为什么能在加深网络的情况下获得更好的效果呢?论文中给出了这样的解释(这也是残差网络更好训练的原因)。
如果增加的新层可以构造为identity mappings,一个更深的模型的错误率应该不大于对应的浅层模型。退化问题表明了网络中多个非线性层拟合identity mappings是有困难的。在残差网络中,如果identity mappings是最优的,优化过程中多个非线性层的权值将趋向于0,以此来实现identity mappings。
论文后面给出了一种Bottleneck Architectures,比前面给出的2层卷积组成的残差结构参数更少(这是选择这种结构主要的出发点),前面2层卷积的残差结构也可以通过加深网络层数达到较好的效果。 Bottleneck Architectures如下图所示,去掉了一个3*3卷积层,加入了两个1*1卷积层。