1 ��ͼ
��ͼ��һ������ı�����ͬ��ֱ�Ӳ������ݱ�����ͼ������SELECT����������ģ��������������ܣ������Բ�����ͼʱ����ݴ�����ͼ��SELECT�������һ���������Ȼ�����������������SQL������
ͼƬ��Դ����sql�����̵̳�2�桷
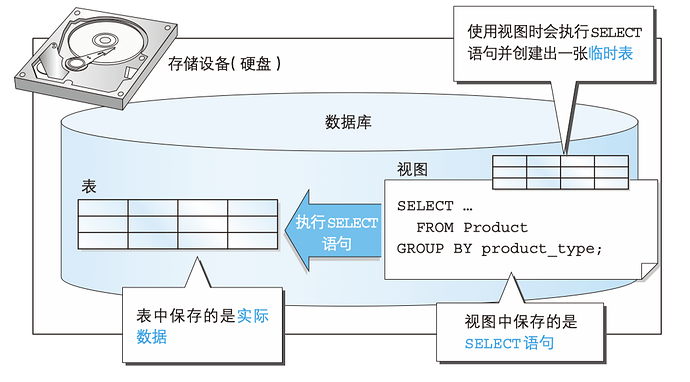
��ͼ���ŵ�
- ���Խ�Ƶ��ʹ�õ�SELECT��䱣�������Ч�ʡ�
- ����ʹ�û����������ݸ���������
- ���Բ���������ݱ�ȫ���ֶΣ���ǿ���ݵı����ԡ�
- ���Խ������ݵ�����
������ͼ
CREATE VIEW productsum (product_type, cnt_product)
AS
SELECT product_type, COUNT(*)FROM productGROUP BY product_type;
��һ���DBMS�ж�����ͼʱ����ʹ��ORDER BY���,������Ϊ��ͼ�ͱ�һ���������ж���û��˳��ġ��� MySQL����ͼ�Ķ���������ʹ�� ORDER BY ���ģ����������ض���ͼ����ѡ������ͼʹ�����Լ��� ORDER BY ��䣬����ͼ�����е� ORDER BY �������ԡ�
����ͼ
��ͼ�������ݿ�����Ҫ��Ψһ�ģ�������������ͼ�ͱ�����
ALTER VIEW productSumASSELECT product_type, sale_priceFROM ProductWHERE regist_date > '2009-09-11';
������ͼ
��ͼ��һ������������Զ���ͼ�IJ������ǶԵײ�������IJ�������������ʱֻ������ײ�������Ķ�����ܳɹ��ġ�
����һ����ͼ��˵������������½ṹ������һ�ֶ��Dz����Ա����µģ�
- �ۺϺ��� SUM()��MIN()��MAX()��COUNT() �ȡ�
- DISTINCT �ؼ��֡�
- GROUP BY �Ӿ䡣
- HAVING �Ӿ䡣
- UNION �� UNION ALL �������
- FROM �Ӿ��а��������
UPDATE productsumSET sale_price = '5000'WHERE product_type = '�칫��Ʒ';
ע�⣺������Ȼ�ijɹ��ˣ����Dz����Ƽ�����ʹ�÷�ʽ�����������ڴ�����ͼʱҲ����ʹ�����Ʋ�����ͨ����ͼ���ı�
ɾ����ͼ
DROP VIEW productSum;
2 �Ӳ�ѯ
- �Ӳ�ѯָһ����ѯ���Ƕ������һ����ѯ����ڲ��IJ�ѯ��������Դ� MySQL 4.1 ��ʼ���룬�� SELECT
�Ӿ����ȼ����Ӳ�ѯ���Ӳ�ѯ�����Ϊ�����һ����ѯ�Ĺ�����������ѯ���Ի���һ�������߶������- �Ӳ�ѯ��һ���Եģ������Ӳ�ѯ��������ͼ���������ڴ洢�����У� ������ SELECT ���ִ��֮�����ʧ�ˡ�
SELECT stu_name
FROM (SELECT stu_name, COUNT(*) AS stu_cntFROM students_infoGROUP BY stu_age) AS studentSum;
Ƕ���Ӳ�ѯ
SELECT product_type, cnt_product
FROM (SELECT *FROM (SELECT product_type, COUNT(*) AS cnt_productFROM product GROUP BY product_type) AS productsumWHERE cnt_product = 4) AS productsum2;
�ȼ����Ӳ�ѯ���Ӳ�ѯ�����Ϊ�����һ����ѯ�Ĺ����������������ڲ���Ӳ�ѯ���ǽ�������ΪproductSum������������product_type���鲢��ѯ�������ڶ����ѯ�н�����Ϊ4����Ʒ��ѯ������������ѯproduct_type��cnt_product���С�
��ȻǶ���Ӳ�ѯ���Բ�ѯ����������������Ӳ�ѯǶ�IJ����ĵ��ӣ�SQL��䲻���������������ִ��Ч��Ҳ��ܲ����Ҫ��������������ʹ�á�
�����Ӳ�ѯ
��ν�����Ӳ�ѯ�������Ӳ�ѯ�᷵��һ��ֵ����Ϊ���IJ���ʹ�á�
SELECT product_id, product_name, sale_priceFROM productWHERE sale_price > (SELECT AVG(sale_price) FROM product);
���������������Ⱥ�벿�ֲ�ѯ��product���е�ƽ���ۼۣ�ǰ���sql����ڸ���WHERE������ѡ�����ʵ���Ʒ��
���ڱ����Ӳ�ѯ�����ԣ����±����Ӳ�ѯ������������ WHERE �Ӿ��У�ͨ���κο���ʹ�õ�һֵ��λ�ö�����ʹ�á� �ܹ�ʹ�ó������������ĵط��������� SELECT �Ӿ䡢GROUP BY �Ӿ䡢HAVING �Ӿ䣬���� ORDER BY �Ӿ䣬�������еĵط�������ʹ�á�
SELECT product_id,product_name,sale_price,(SELECT AVG(sale_price)FROM product) AS avg_priceFROM product;
�����Ӳ�ѯ
��ѯ�����۵��۸���ƽ�����۵��۵���Ʒʱ������ôд����ʵ���������Ӳ�ѯ����
SELECT product_id, product_name, sale_priceFROM productWHERE sale_price > (SELECT AVG(sale_price) FROM product);
�����������ѡȡ������Ʒ�����и��ڸ���Ʒ�����ƽ�����۵��۵���ƷʱӦ����ôд�أ����°벿�ֽ�������here��

��������������select���ִ������Ӧ�ô�WHERE�־��е������ڵ��Ӳ�ѯ��ʼ���Ӳ�ѯҲ��һ��SELECT��䣬Ӧ��������ʼִ�У�
1.FROM Product AS P2 ��ָ����Product��ȡ���ݡ�
2.WHERE P1.product_type = P2.product_type
�����P1��P2����ָ��Product�����������ı���������P1.product_type �� P2.product_type��Ȼ����ȵģ��������WHERE�־��Ƿϻ���
����ɾ����ͻᱨ����ԭ����sale_price��һ�����ݣ��Ӳ�ѯ�Ľ����3�����ݣ������бȽϡ������õ�������Ҫ�ġ�ѡȡ������Ʒ�����и��ڸ���Ʒ�����ƽ�����۵��۵���Ʒ������������
ʵ���ϣ���WHERE P1.product_type = P2.product_type���������ǹ����Ӳ�ѯ�������Ӳ�ѯ��ִ������������SELECT���ִ������ȫ��ͬ����������Ĺ���֮���ˣ���֪���涨����������ô��ģ�����ô���ӵ�������
- 1.��ִ������ѯ
SELECT product _type , product_name, sale_price
FROM Product AS P1
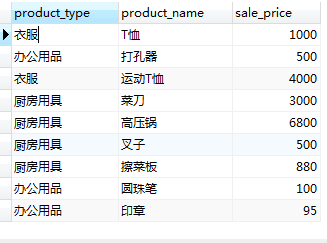
- 2.������ѯ��product _type��ȡ��һ��ֵ=���·�����ͨ��WHERE P1.product_type = P2.product_type�����Ӳ�ѯ���Ӳ�ѯ���
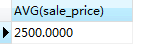
- 3.���Ӳ�ѯ�õ��Ľ��AVG(sale_price)=2500����������ѯ��
SELECT product_type , product_name, sale_price
FROM Product AS P1
WHERE sale_price > 2500 AND product_type = ���·���
��һ���������Ľ����

- 4.Ȼ��product _typeȡ�ڶ���ֵ���õ��������ĵڶ�������������ƣ���product _typeȫȡֵһ�飬�͵õ����������Ľ������������£�
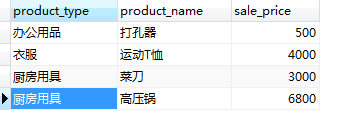
��ʵ�ϣ����й����Ӳ�ѯ��ִ�й��̶�������Ĺ���һ����
3 ����
�������� ������������ֵ����ĺ�����
�ַ������� �����������ַ��������ĺ�����
���ں��� �������������ڲ����ĺ�����
ת������ ������ת���������ͺ�ֵ�ĺ�����
�ۺϺ��� �������������ݾۺϵĺ�����
��������
+ - * /��������- ABS( ��ֵ ) �C ����ֵ����
- MOD( ������������ )�C ������
- ROUND( ������ֵ������С����λ�� )�C ��������
�ַ�������
-
CONCAT �C ƴ��
���CONCAT(str1, str2, str3) -
LENGTH �C �ַ�������
���LENGTH( �ַ��� ) -
LOWER �C Сдת��
-
UPPER�C ��дת��
-
REPLACE �C �ַ������滻
���REPLACE( �����ַ������滻ǰ���ַ������滻����ַ��� ) -
SUBSTRING �C �ַ����Ľ�ȡ
���SUBSTRING �������ַ��� FROM ��ȡ����ʼλ�� FOR ��ȡ���ַ�����������ֵ��ʼΪ1�� -
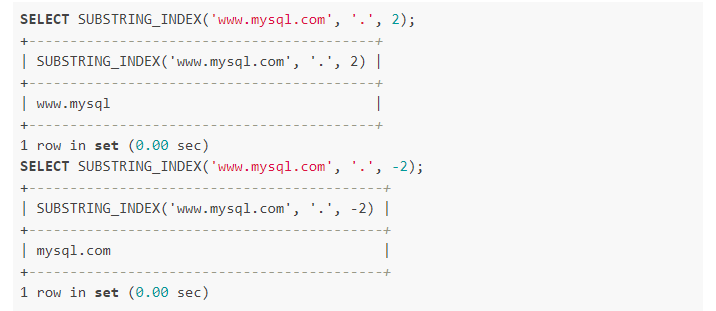
SUBSTRING_INDEX �C �ַ�����������ȡ
���SUBSTRING_INDEX (ԭʼ�ַ����� �ָ�����n)
ԭʼ�ַ������շָ����ָ�� n ���ָ���֮ǰ����֮�����ַ�����֧������ͷ���������������ʼֵ�ֱ�Ϊ 1 �� -1��
���ں���
��ͬDBMS�����ں�������в�ͬ��������һЩ���� SQL ���ϵĿ���Ӧ���ھ������ DBMS �ĺ������ض�DBMS�����ں��������ĵ����ɡ�
- CURRENT_DATE �C ��ȡ��ǰ����

- CURRENT_TIME �C ��ǰʱ��

- CURRENT_TIMESTAMP �C ��ǰ���ں�ʱ��

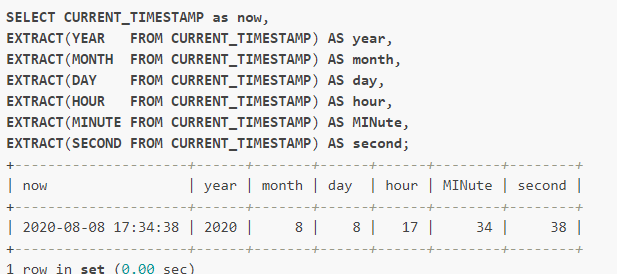
- EXTRACT �C ��ȡ����Ԫ��
���EXTRACT(����Ԫ�� FROM ����)
ʹ�� EXTRACT �������Խ�ȡ�����������е�һ���֣����硰�ꡱ
���¡������ߡ�Сʱ�����롱�ȡ��ú����ķ���ֵ�������������Ͷ�����ֵ������
ת������
�� SQL ����Ҫ��������˼��
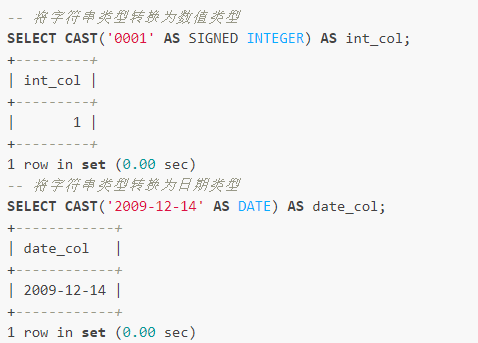
һ���������͵�ת�������Ϊ����ת������Ӣ���г�Ϊcast��
��һ����˼��ֵ��ת����
- CAST �C ����ת��
���CAST��ת��ǰ��ֵ AS ��Ҫת�����������ͣ�
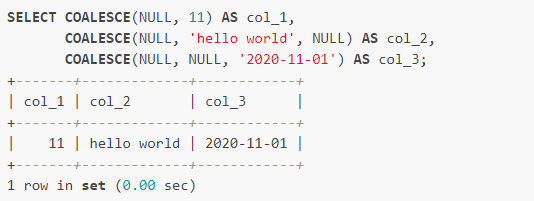
- COALESCE �C ��NULLת��Ϊ����ֵ
���COALESCE(����1������2������3����)
COALESCE �� SQL ���еĺ������ú����᷵�ؿɱ���� A ����ʼ�� 1������NULL��ֵ���� SQL ����н� NULL ת��Ϊ����ֵʱ�ͻ��õ�ת������
4 �
ν�ʾ��Ƿ���ֵΪ��ֵ�ĺ���������TRUE / FALSE / UNKNOWN��
ν����Ҫ�����¼���
- LIKE
- BETWEEN
- IS NULL��IS NOT NULL
- IN
- EXISTS
LIKE�C �����ַ���ƥ���ѯ
ͨ����%��_���ʹ��
%�Ǵ���������������ַ������������
_�»���ƥ������ 1 ���ַ�- ������ѯ�������ַ�����ʼ������
ddd��
SELECT *
FROM samplelike
WHERE strcol LIKE 'ddd%';
LIKE 'ddd%'������ddd��ͷ�������ַ�����β��Ҳ���Ծ�ddd�����ַ�
LIKE '%ddd%������ddd���м䣬�����������ַ�����Ҳ���Ծ�ddd�����ַ�
LIKE '%ddd������ddd��ĩβ�������ַ�����ͷ��Ҳ���Ծ�ddd�����ַ�
LIKE "ddd__"������ddd��ͷ������2���ַ�����β��2���»��ߣ�
BETWEEN �C ���ڷ�Χ��ѯ
-- ѡȡ���۵���Ϊ100�� 1000Ԫ����Ʒ
SELECT product_name, sale_price
FROM product
WHERE sale_price BETWEEN 100 AND 1000;
BETWEEN ���ص���ǽ���л���� 100 �� 1000 �������ٽ�ֵ��Ҳ������������
��������ý���а����ٽ�ֵ���Ǿͱ���ʹ�� < �� >
IS NULL�� IS NOT NULL �C �����ж��Ƿ�ΪNULL
Ϊ��ѡȡ��ijЩֵΪ NULL ���е����ݣ�����ʹ�� =����ֻ��ʹ���ض���ν��IS NULL
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IS NULL;
����෴����Ҫѡȡ NULL ���������ʱ����Ҫʹ��IS NOT NULL��
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IS NOT NULL;
IN�C OR�ļ����÷�
�����ѯ����ȡ����ʱ����ѡ��ʹ��or��䡣
-- ͨ��ORָ������������۽��в�ѯ
SELECT product_name, purchase_price
FROM product
WHERE purchase_price = 320
OR purchase_price = 500
OR purchase_price = 5000;
��Ȼ��������û�����⣬�����Ǵ���һ�㲻��֮�����Ǿ�������ϣ��ѡȡ�Ķ���Խ��Խ�࣬ SQL ���Ҳ��Խ��Խ������ʱ�� ���ǾͿ���ʹ��IN ν��IN(ֵ1, ֵ2, ֵ3, ��)���滻���� SQL ��䡣
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IN (320, 500, 5000);
��֮��ϣ��ѡȡ�����������۲��� 320 Ԫ�� 500 Ԫ�� 5000 Ԫ������Ʒʱ������ʹ�÷���ʽNOT IN��ʵ�֡�
SELECT product_name, purchase_price
FROM product
WHERE purchase_price NOT IN (320, 500, 5000);
��Ҫע����ǣ���ʹ��IN �� NOT IN ʱ����ѡȡ��NULL���ݵġ�ֻҪin����not in ����null��������ǿռ���
ʵ�ʽ��Ҳ����ˣ������������ж���������������Ϊ NULL �IJ��Ӻ�Բ��ʡ� NULL ֻ��ʹ�� IS NULL �� IS NOT NULL �������жϡ�
EXIST
���þ����ж��Ƿ��������ij�������ļ�¼
������������ļ�¼�ͷ����棨TRUE������������ھͷ��ؼ٣�FALSE����EXIST�����ڣ�ν�ʵ������ǡ���¼����
EXISTS��NOT EXISTS��������IN��NOT IN�����ƣ�����EXISTS��NOT EXISTSֻ�����Ӳ�ѯ��ʹ�ã�
- ʹ�� EXIST ѡȡ�������ŵ�������Ʒ�����۵��ۣ�
SELECT product_name, sale_priceFROM product AS pWHERE EXISTS (SELECT *FROM shopproduct AS spWHERE sp.shop_id = '000C'AND sp.product_id = p.product_id);
EXIST ֻ���ļ�¼�Ƿ���ڣ���˷�����Щ�ж�û�й�ϵ�� EXIST ֻ���ж��Ƿ���������Ӳ�ѯ�� WHERE �Ӿ�ָ�����������̵��ţ�shop_id��Ϊ ��000C������Ʒ��product�������̵ꡣ
��Ʒ��shopproduct��������Ʒ��ţ�product_id����ͬ���ļ�¼��ֻ�д��������ļ�¼ʱ�ŷ����棨TRUE������ˣ�ʹ������IJ�ѯ��䣬��ѯ���Ҳ���ᷢ���仯
SELECT product_name, sale_priceFROM product AS pWHERE EXISTS (SELECT 1 -- ���������д�ʵ��ij���FROM shopproduct AS spWHERE sp.shop_id = '000C'AND sp.product_id = p.product_id);
���� EXIST ���������滻 IN һ���� NOT IN Ҳ������NOT EXIST���滻��
- ���ڴ����ŵ����۵���Ʒ�����۵��ۣ�
SELECT product_name, sale_priceFROM product AS pWHERE NOT EXISTS (SELECT *FROM shopproduct AS spWHERE sp.shop_id = '000A'AND sp.product_id = p.product_id);
5 CASE ����ʽ
CASE ����ʽ�Ǻ�����һ�֡��� SQL ����һ��������Ҫ���ܡ�
���
CASE WHEN <��ֵ����ʽ> THEN <����ʽ>WHEN <��ֵ����ʽ> THEN <����ʽ>WHEN <��ֵ����ʽ> THEN <����ʽ>...
ELSE <����ʽ>
END
�������ִ��ʱ�������ж� when ����ʽ�Ƿ�Ϊ��ֵ������ִ�� THEN �����䣬������е� when ����ʽ��Ϊ�٣���ִ�� ELSE �����䣬��ʵ����python��� if elif ... elseһ���Ĺ��ܺͽṹ��
����1�����ݲ�ͬ��֧�õ���ͬ��ֵ
SELECT product_name,CASE WHEN product_type = '�·�' THEN CONCAT('A �� ',product_type)WHEN product_type = '�칫��Ʒ' THEN CONCAT('B �� ',product_type)WHEN product_type = '�����þ�' THEN CONCAT('C �� ',product_type)ELSE NULLEND AS abc_product_typeFROM product;
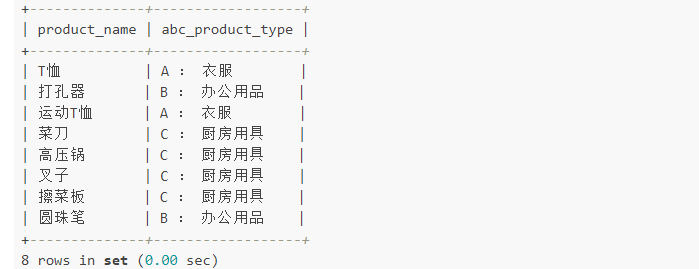
ELSE �Ӿ�Ҳ����ʡ�Բ�д����ʱ�ᱻĬ��Ϊ ELSE NULL������END����ʡ�ԡ�
����2�� ʵ���з����ϵľۺ�
ͨ������ʹ�����´���ʵ���еķ����ϲ�ͬ����ľۺϣ������� sum��
SELECT product_type,SUM(sale_price) AS sum_priceFROM productGROUP BY product_type;
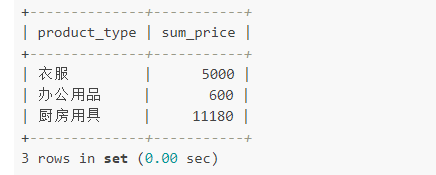
����Ҫ���еķ�����չʾ��ͬ�����ۺ�ֵ�������д�أ�

-- ������Ʒ�������������۵��ۺϼ�ֵ��������ת��
SELECT SUM(CASE WHEN product_type = '�·�' THEN sale_price ELSE 0 END) AS sum_price_clothes,SUM(CASE WHEN product_type = '�����þ�' THEN sale_price ELSE 0 END) AS sum_price_kitchen,SUM(CASE WHEN product_type = '�칫��Ʒ' THEN sale_price ELSE 0 END) AS sum_price_officeFROM product;
����3��ʵ����ת��
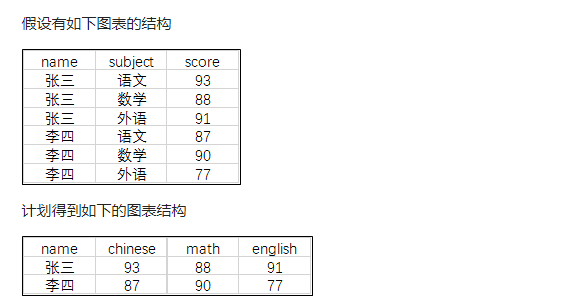
-- CASE WHEN ʵ�������� score ��ת��
SELECT name,SUM(CASE WHEN subject = '����' THEN score ELSE null END) as chinese,SUM(CASE WHEN subject = '��ѧ' THEN score ELSE null END) as math,SUM(CASE WHEN subject = '����' THEN score ELSE null END) as englishFROM scoreGROUP BY name;

Ҳ����ʵ���ı��� subject ����ת��
-- CASE WHEN ʵ���ı��� subject ��ת��
SELECT name,MAX(CASE WHEN subject = '����' THEN subject ELSE null END) as chinese,MAX(CASE WHEN subject = '��ѧ' THEN subject ELSE null END) as math,MIN(CASE WHEN subject = '����' THEN subject ELSE null END) as englishFROM scoreGROUP BY name;
- ����ת����Ϊ����ʱ������ʹ��SUM AVG MAX MIN�ȾۺϺ�����
- ����ת����Ϊ�ı�ʱ������ʹ��MAX MIN�ȾۺϺ���
6 ��ϰ��
- 3.1
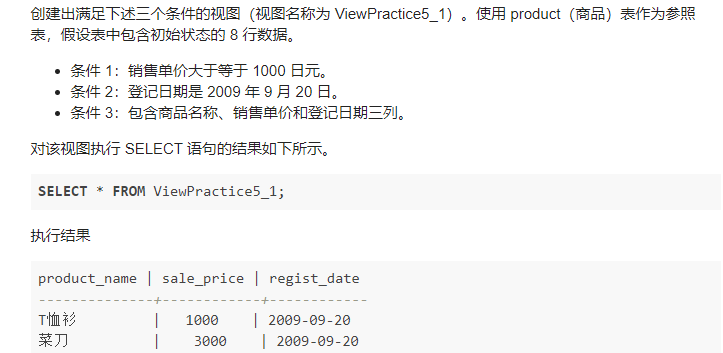
CREATE VIEW ViewPractice5_1 (product_name, sale_price,regist_date)
AS
SELECT product_name, sale_price,regist_date
FROM product
WHERE sale_price>=1000 AND regist_date='2009-09-20';
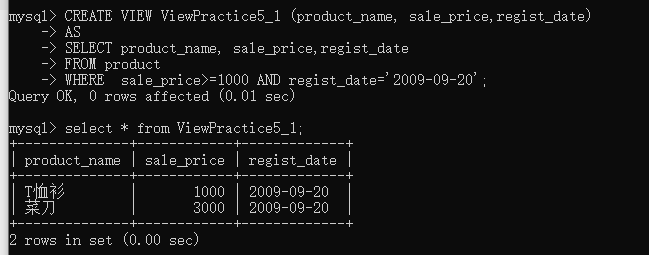
- 3.2


�ᱨ����Field of view 'datawhale.viewpractice5_1' underlying table doesn't have a default value
����update���³ɹ�����ͼ��ԭ���������˱仯
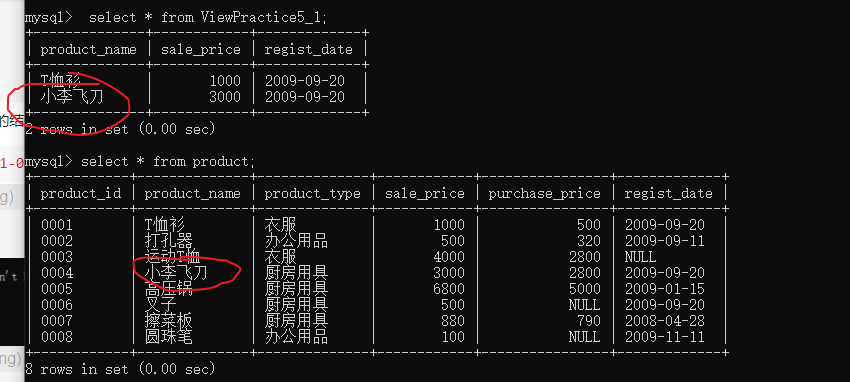
- 3.3
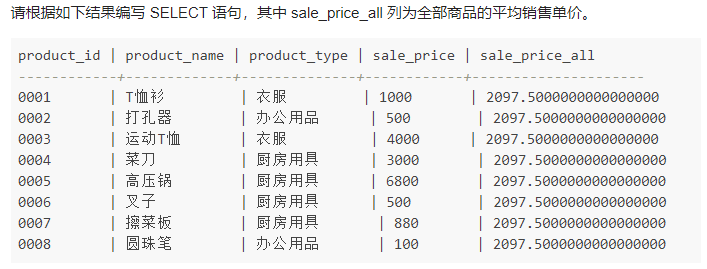
ʹ�ñ����Ӳ�ѯ����
SELECT p1.*,(SELECT AVG(sale_price) FROM product as p2) AS sale_price_all
FROM product AS p1;
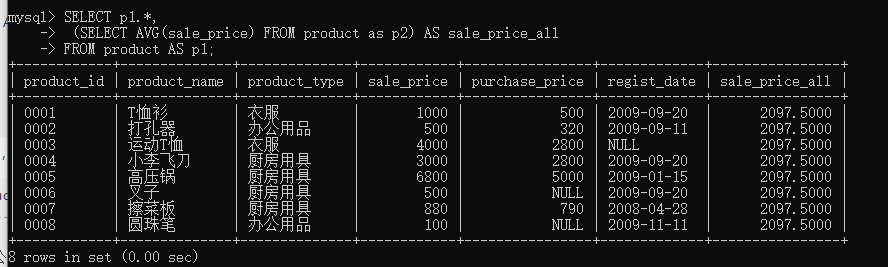
- 3.4
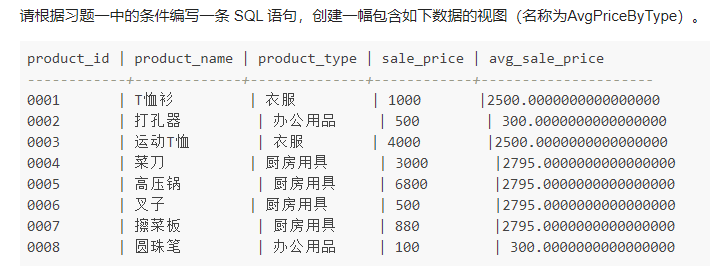
CREATE VIEW AvgPriceByType (product_id,product_name,product_type,sale_price,avg_sale_price)
AS
SELECT p1.*,
(SELECT AVG(p2.sale_price)
FROM product AS p2
WHERE p1.product_type=p2.product_type) AS avg_sale_price
FROM product AS p1;
- 3.5
������ߺ����к��� NULL ʱ�����ȫ�����ΪNULL �����ж��⣩
���ԣ��Ὣnull�ų�����
��count����ʱ��ֱ��count(����)�����null�����У���count(1)��count(*)��Ѱ���null����Ҳ�����ȥ
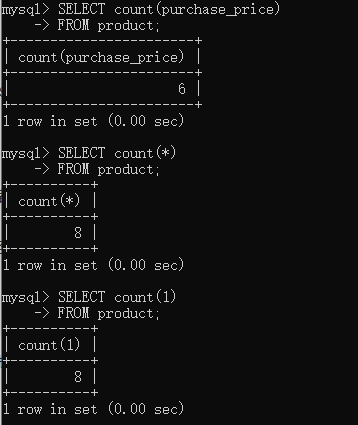
- 3.6

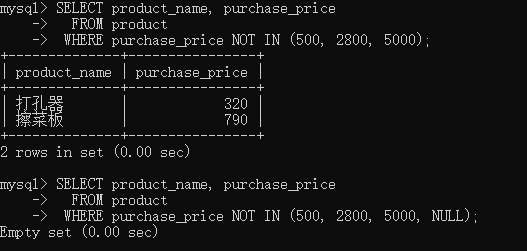
�ڶ�����䱾��Ӧ������ȡ����500,2800,5000��purchase_price�ǿյ����ݣ������Ϊ�ռ�����Ԥ�ڵIJ�һ��
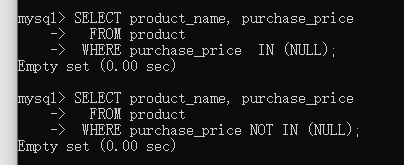
ʵ���ϣ�ֻҪin����not in ����null��������ǿռ�
ʹ��IN �� NOT IN ʱ��ѡȡ��NULL���ݣ�������is null ����is not null
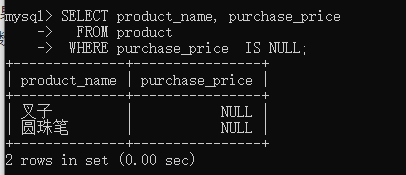
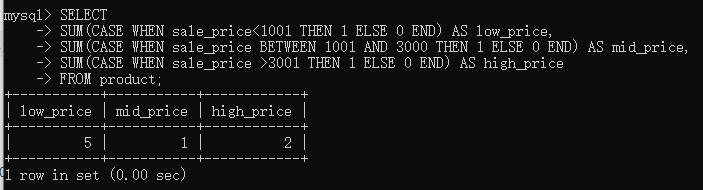
- 3.7

SELECT
SUM(CASE WHEN sale_price<1001 THEN 1 ELSE 0 END) AS low_price,
SUM(CASE WHEN sale_price BETWEEN 1001 AND 3000 THEN 1 ELSE 0 END) AS mid_price,
SUM(CASE WHEN sale_price >3001 THEN 1 ELSE 0 END) AS high_price
FROM product;
Task 03:����һ��IJ�ѯ