1. 异常检测是什么
异常检测(Outlier Detection),就是识别出来与正常或者说大多数数据差异较大的数据。
如识别信用卡欺诈,工业生产异常,网络流里的异常等。

- 点异常(离群)
指的是少数个体是异常的,大多数是正常的,例如正常人与病人的健康指标 - 上下文异常(特殊场景离群)
指的是在特定情境下个体是异常的,在其他情境下都是正常的,例如在特定时间下的温度突然上升或下降 - 群体异常(一堆坏人里的好人)
指的是在群体集合中的个体实例出现异常的情况,而该个体自身可能并不是异常
例如社交网络中虚假账号形成的集合作为群体异常子集,但子集中的个体节点可能与真实账号一样正常。
异常检测场景主要有:
- 故障检测
- 物联网异常检测
- 欺诈检测
- 工业异常检测
- 时间序列异常检测
- 视频异常检测
- 日志异常检测
- 医疗日常检测
- 网络入侵检测
2.怎么进行异常检测
2.1传统方法
统计学
基于统计学的方法一般是假定正常的数据对象由一个统计模型产生,而不遵守该模型的数据是异常点。
线性模型
典型的如PCA方法,即主成分分析。它的应用场景是对数据集进行降维。
降维后的数据能够最大程度地保留原始数据的特征(以数据协方差为衡量标准)。
pca如何进行异常检测???
基于相似度的方法
这类算法适用于数据点的聚集程度高、离群点较少的情况,不太适用于数据量大、维度高的数据(因为相似度算法通常需要对每一个数据分别进行相应计算,所以这类算法通常计算量大)
- 1.基于集群(簇)的检测
如DBSCAN等聚类算法
聚类的主要目的通常是为了寻找成簇的数据,而将异常值和噪声一同作为无价值的数据而忽略或丢弃,在专门的异常点检测中使用较少。 - 2.基于距离的度量
如k近邻算法
k近邻算法的基本思路是对每一个点,计算其与最近k个相邻点的距离,通过距离的大小来判断它是否为离群点。 - 3.基于密度的度量
局部离群因子(LOF)算法与k近邻类似,不同的是它以相对于其邻居的局部密度偏差而不是距离来进行度量。它将相邻点之间的距离进一步转化为“邻域”,从而得到邻域中点的数量(即密度),认为密度远低于其邻居的样本为异常值。
2.2集成方法
集成是提高数据挖掘算法精度的常用方法。集成方法将多个算法或多个基检测器的输出结合起来。其基
本思想是一些算法在某些子集上表现很好,一些算法在其他子集上表现很好,然后集成起来使得输出更
加鲁棒。
常用的集成方法有Feature bagging,孤立森林等。
2.3机器学习
在有标签的情况下,可以使用树模型(gbdt,xgboost等)进行分类,缺点是异常检测场景下数据标签是
不均衡的,但是利用机器学习算法的好处是可以构造不同特征。
3.异常检测常用开源库
- Scikit-learn
一个Python语言的开源机器学习库。它具有各种分类,回归和聚类算法。也包含了一些
异常检测算法,例如LOF和孤立森林。
官网:https://scikit-learn.org/stable/
- PyOD
Python Outlier Detection(PyOD)是当下最流行的Python异常检测工具库,其主要亮点包括:
- 包括近20种常见的异常检测算法,比如经典的LOF/LOCI/ABOD以及最新的深度学习如对抗生
成模型(GAN)和集成异常检测(outlier ensemble)- 支持不同版本的Python:包括2.7和3.5+;支持多种操作系统:windows,macOS和Linux
- 简单易用且一致的API,只需要几行代码就可以完成异常检测,方便评估大量算法
- 使用JIT和并行化(parallelization)进行优化,加速算法运行及扩展性(scalability),可以
处理大量数据
――https://zhuanlan.zhihu.com/p/5831352
4.练习
- 学习pyod库基本操作
(如何生成toy example,了解训练以及预测的api)
| 生成样例数据 |
|---|

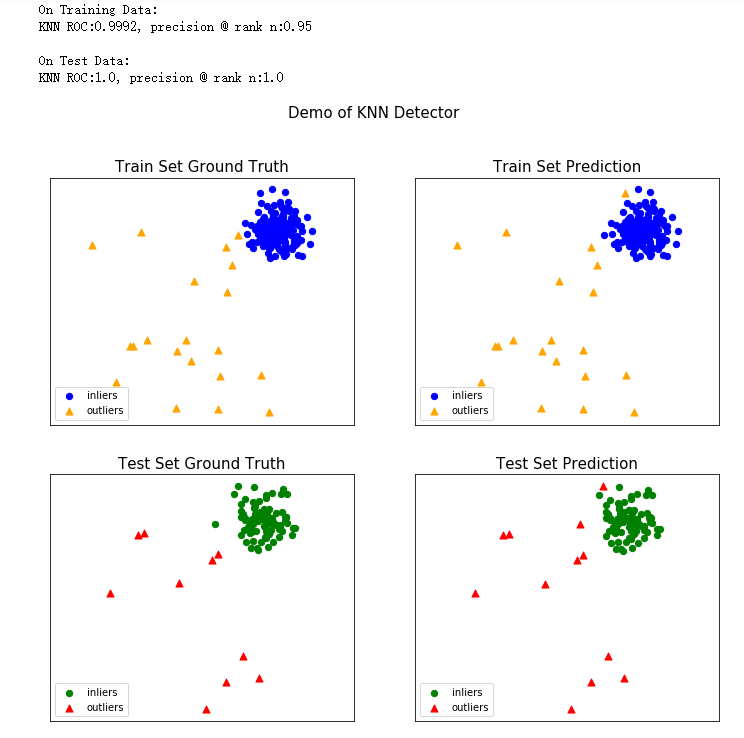
可以看到输入的x是二维,输出的y是一维

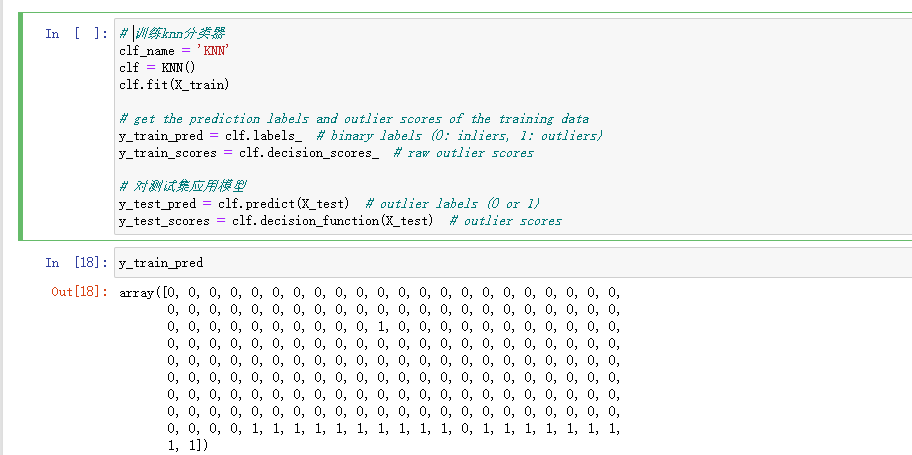
| 训练分类器 |
|---|
| 评估分类器 |
|---|