最近通读了inception的四篇论文,在此做一下笔记。
先给出这四篇论文的地址:
Going deeper with convolutions:https://arxiv.org/pdf/1409.4842.pdf
Batch Normalization: https://arxiv.org/pdf/1502.03167.pdf
Rethinking the Inception Architecture for Computer Vision:https://arxiv.org/pdf/1512.00567.pdf
Inception-v4, Inception-ResNet: https://arxiv.org/pdf/1602.07261.pdf
Inception-v1
在这篇轮文之前,卷积神经网络的性能提高都是依赖于提高网络的深度和宽度,而这篇论文是从网络结构上入手,改变了网络结构,所以个人认为,这篇论文价值很大。
该论文的主要贡献:提出了inception的卷积网络结构。
从以下三个方面简单介绍这篇论文:为什么提出Inception,Inception结构,Inception作用
为什么提出Inception
提高网络最简单粗暴的方法就是提高网络的深度和宽度,即增加隐层和以及各层神经元数目。但这种简单粗暴的方法存在一些问题:
- 会导致更大的参数空间,更容易过拟合
- 需要更多的计算资源
- 网络越深,梯度容易消失,优化困难(这时还没有提出BN时,网络的优化极其困难)
基于此,我们的目标就是,提高网络计算资源的利用率,在计算量不变的情况下,提高网络的宽度和深度。
作者认为,解决这种困难的方法就是,把全连接改成稀疏连接,卷积层也是稀疏连接,但是不对称的稀疏数据数值计算效率低下,因为硬件全是针对密集矩阵优化的,所以,我们要找到卷积网络可以近似的最优局部稀疏结构,并且该结构下可以用现有的密度矩阵计算硬件实现,产生的结果就是Inception。
Inception结构
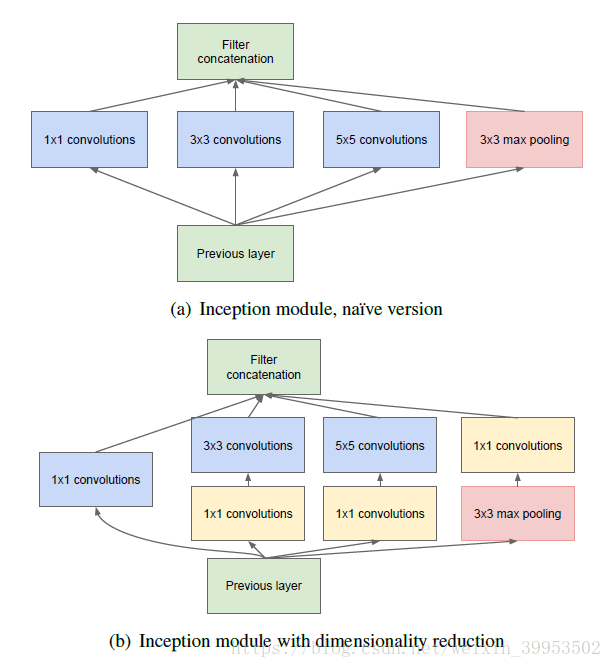
首先看第一个结构,有四个通道,有1*1、3*3、5*5卷积核,该结构有几个特点:
- 使用这些大小卷积核,没有什么特殊含义,主要方便对齐,只要padding = 0、1、2,就可以得到相同大小的特征图,可以顺利concat。
- 采用大小不同的卷积核,意味着感受野的大小不同,就可以得到不同尺度的特征。
- 采用比较大的卷积核即5*5,因为有些相关性可能隔的比较远,用大的卷积核才能学到此特征。
但是这个结构有个缺点,5*5的卷积核的计算量太大。那么作者想到了第二个结构,用1*1的卷积核进行降维。
- 降低维度,减少计算瓶颈
- 增加网络层数,提高网络的表达能力
那么在具体的卷积神经网络中,Inception应该放在哪里,作者的建议,在底层保持传统卷积不变,在高层使用Inception结构。
Inception作用
- 显著增加了每一步的单元数目,计算复杂度不会不受限制,尺度较大的块卷积之前先降维
- 视觉信息在不同尺度上进行处理聚合,这样下一步可以从不同尺度提取特征
但是具体,为什么Inception会起作用,我一直想不明白,作者后面实验也证明了GoogLeNet的有效性,但为什么也没有具体介绍。深度学习也是一个实践先行的学科,实践领先于理论,实践证明了它的有效性。后来看到一个博客,解开了我的谜团。在此贴出他的回答。
Inception的作用就是替代了人工确定卷积层中过滤器的类型或者是否创建卷积层和池化层,让网络自己学习它具体需要什么参数。
Inception-v2
这篇论文主要思想在于提出了Batch Normalization,其次就是稍微改进了一下Inception。Batch Normalization
这个算法太牛了,使得训练深度神经网络成为了可能。从一下几个方面来介绍。
- 为了解决什么问题提出的BN
- BN的来源
- BN的本质
为了解决什么问题提出的BN
训练深度神经网络时,作者提出一个问题,叫做“Internal Covariate Shift”。
这个问题是由于在训练过程中,网络参数变化所引起的。具体来说,对于一个神经网络,第n层的输入就是第n-1层的输出,在训练过程中,每训练一轮参数就会发生变化,对于一个网络相同的输入,但n-1层的输出却不一样,这就导致第n层的输入也不一样,这个问题就叫做“Internal Covariate Shift”。
为了解决这个问题,提出了BN。
BN的来源
在训练中的每个mini-batch上做正则化:

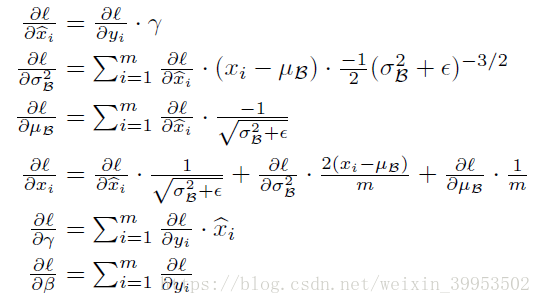
BN的本质
我的理解BN的主要作用就是:
- 加速网络训练
- 防止梯度消失
如果激活函数是sigmoid,对于每个神经元,可以把逐渐向非线性映射的两端饱和区靠拢的输入分布,强行拉回到0均值单位方差的标准正态分布,即激活函数的兴奋区,在sigmoid兴奋区梯度大,即加速网络训练,还防止了梯度消失。
基于此,BN对于sigmoid函数作用大。
sigmoid函数在区间[-1, 1]中,近似于线性函数。如果没有这个公式:
就会降低了模型的表达能力,使得网络近似于一个线性映射,因此加入了scale 和shift。
它们的主要作用就是找到一个线性和非线性的平衡点,既能享受非线性较强的表达能力,有可以避免非线性饱和导致网络收敛变慢问题。
Inception
- 保持相同感受野的同时减少参数
- 加强非线性的表达能力
Inception-v3
这篇论文两个思路:
- 提出神经网络结构的设计和优化思路
- 改进Inception
设计准则
- 避免网络表达瓶颈,尤其在网络的前端。feature map急剧减小,这样对层的压缩过大,会损失大量信息,模型训练困难
- 高维特征的局部处理更困难
- 在较低维度空间聚合,不会损失表达能力。
- 平衡网络的宽度和深度
改进Inception
改进有三个方面
分解卷积核尺寸
这个也有两个办法
- 分解为对称的小的卷积核
- 分解为不对称的卷积核
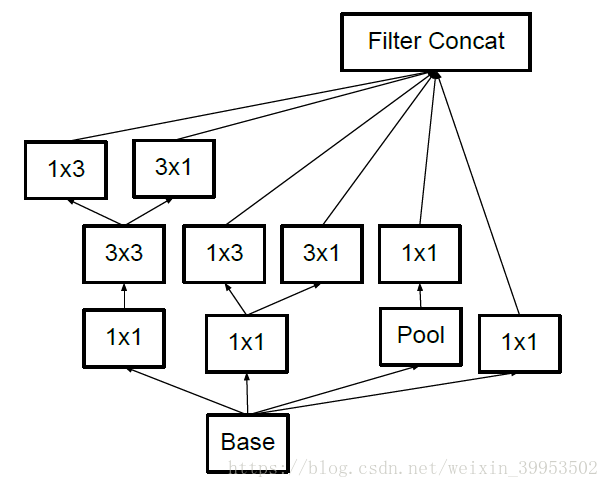
其实第一种方法,我觉得就是VGG中的思想,将5*5的卷积核替换成2个3*3的卷积核
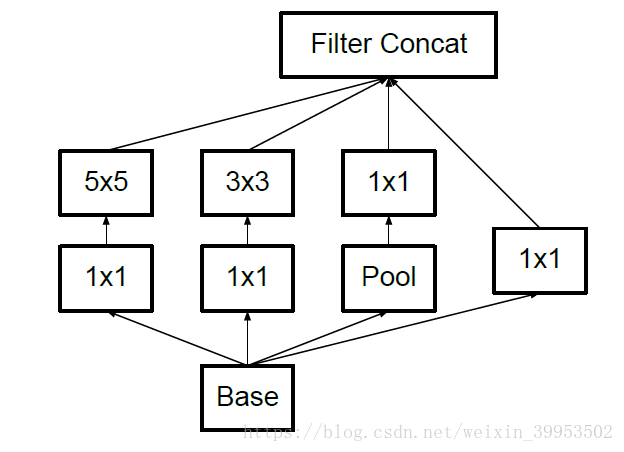
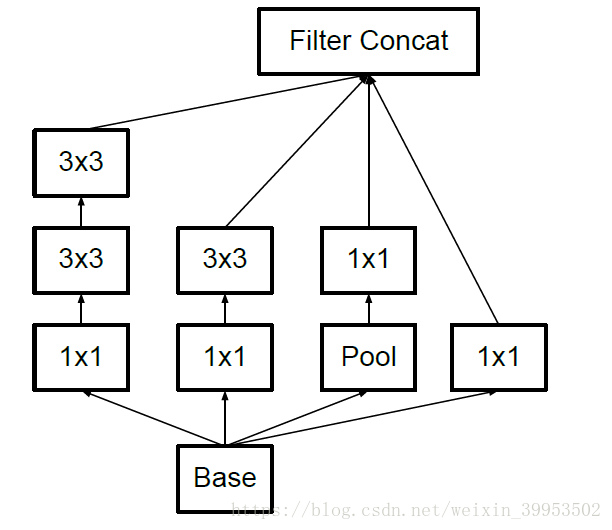
上图左边是原来的Inception,右图是改进的Inception。
第二种方法就是将n*n的卷积核替换成 1*n 和 n*1 的卷积核堆叠,计算量又会降低。
但是第二种分解方法在大维度的特征图上表现不好,在特征图12-20维度上表现好。
不对称分解方法有几个优点:
- 节约了大量的参数
- 增加一层非线性,提高模型的表达能力
- 可以处理更丰富的空间特征,增加特征的多样性
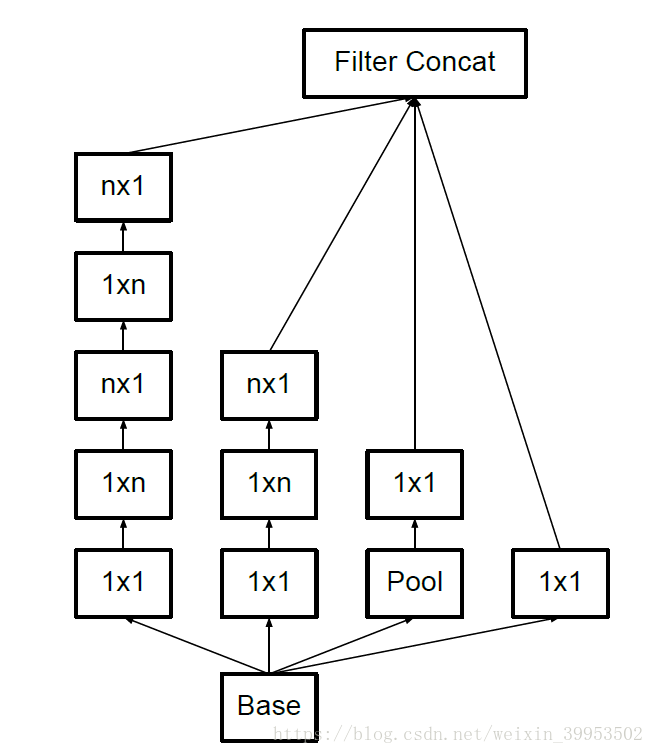
上图是不对称分解的两种方式。
使用辅助分类器
其实在第一篇论文中GoogLeNet中就使用了辅助分类器,使用了2个,那么它的优势就是
- 把梯度有效的传递回去,不会有梯度消失问题,加快了训练
- 中间层的特征也有意义,空间位置特征比较丰富,有利于提成模型的判别力
改变降低特征图尺寸的方式
设计准则的第一条,就是避免表达瓶颈。那么传统的卷积神经网络的做法,当有pooling时(pooling层会大量的损失信息),会在之前增加特征图的厚度(就是双倍增加滤波器的个数),通过这种方式来保持网络的表达能力,但是计算量会大大增加。
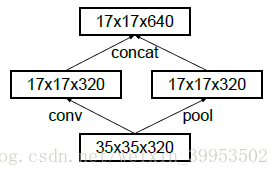
上图就是作者的改进方式。有两个通道,一个是卷积层,一个是pooling层,两个通道生成的特征图大小一样,concat在一起即可。
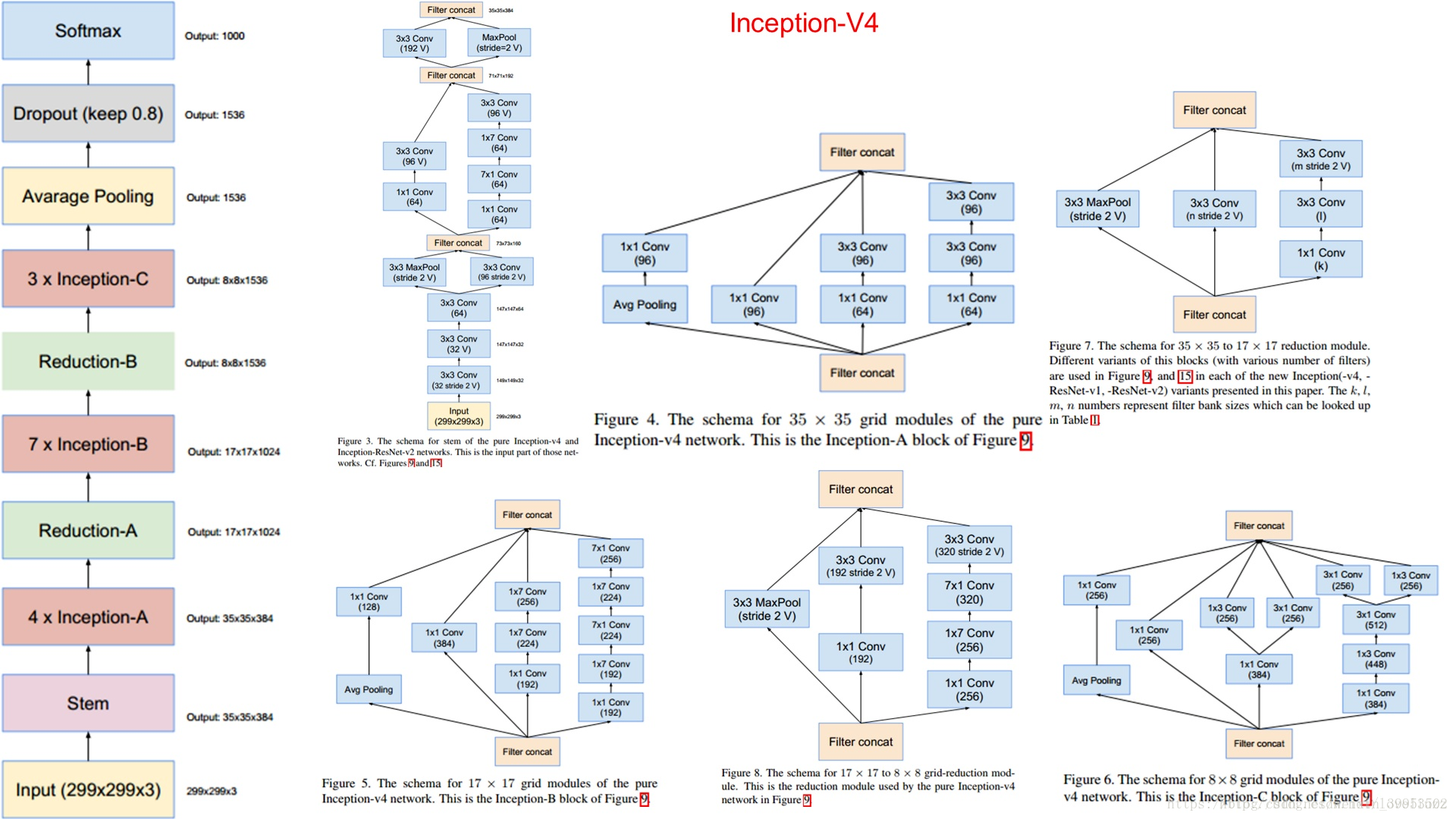
Inception-v4
这篇论文,没有公式,全篇都是画图,就是网络结构。
主要思想很简单:Inception表现很好,很火的ResNet表现也很好,那就想办法把他们结合起来呗。
Inception v4
Inception-ResNet v1
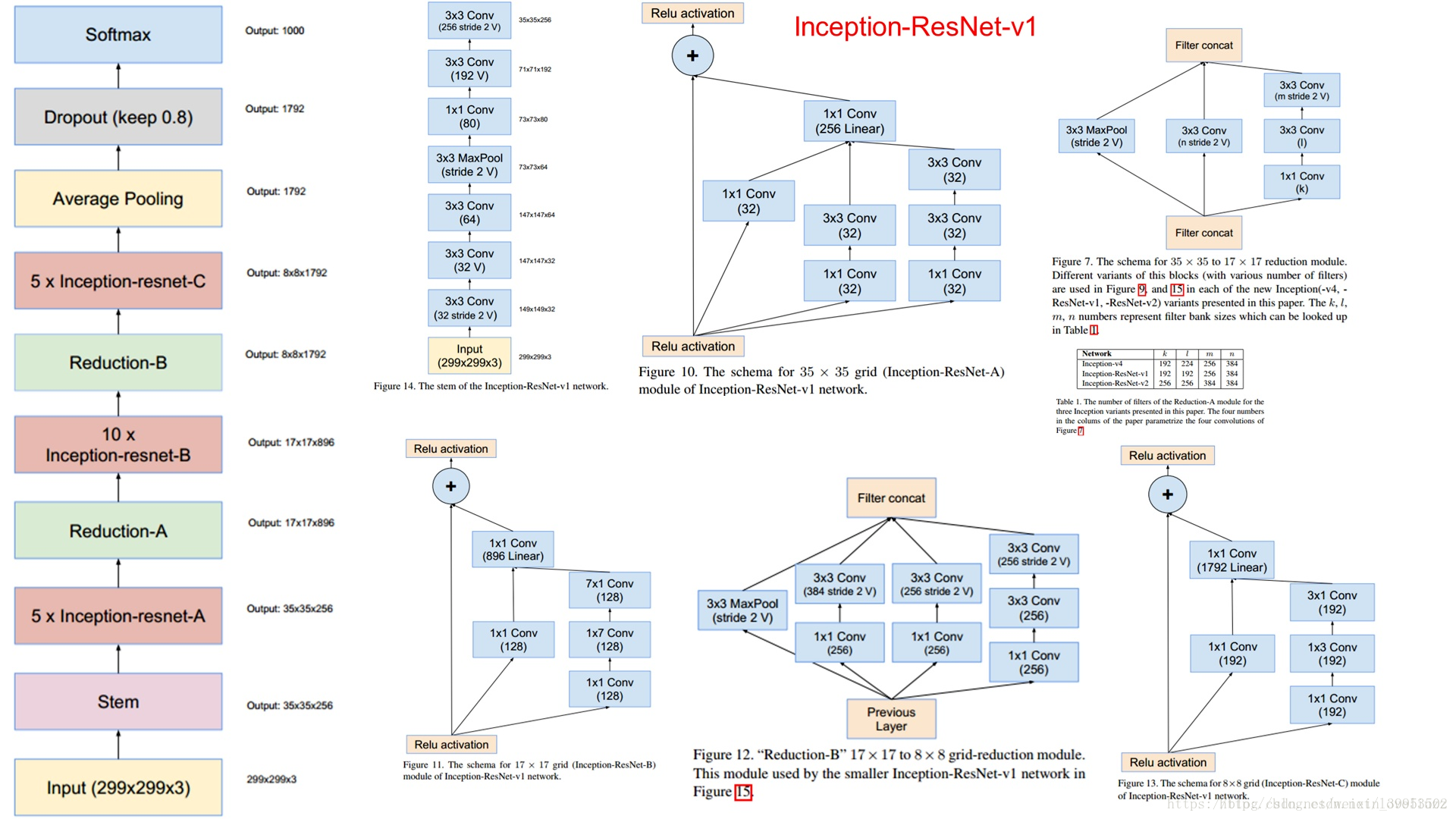
Inception-ResNet v2
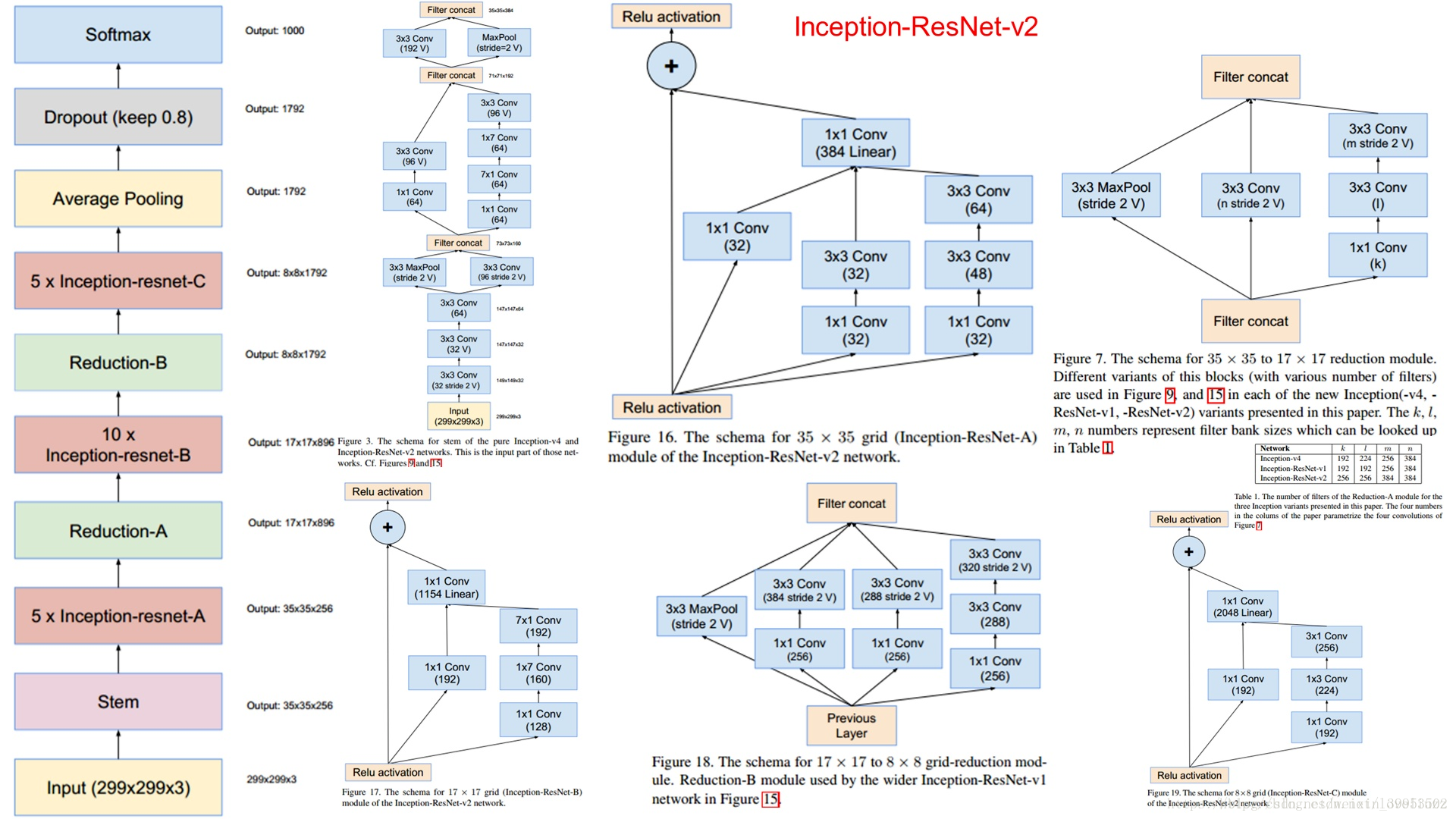
还有几个作者通过实验总结的几个知识点:
1、Residual Connection
作者认为残差连接并不是深度网络所必须的(PS:ResNet的作者说残差连接时深度网络的标配),没有残差连接的网络训练起来并不困难,因为有好的初始化以及Batch Normalization,但是它确实可以大大的提升网路训练的速度。
2、Residual Inception Block
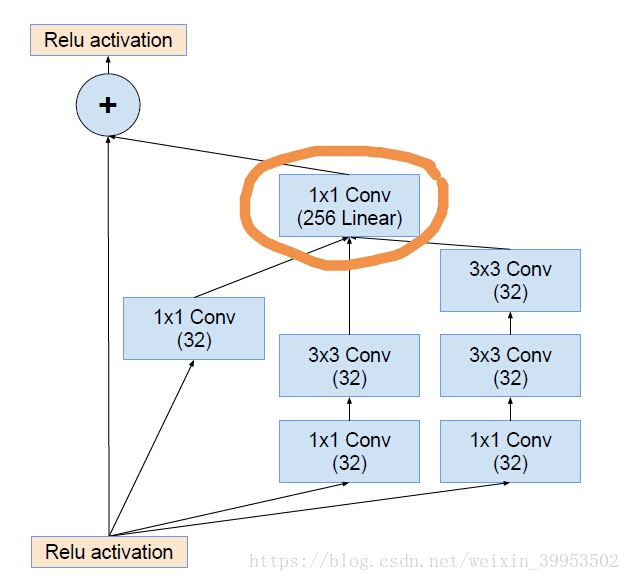
可以看到我画圈的部分,那个1*1的卷积层并没有激活函数,这个作用主要是维度对齐。
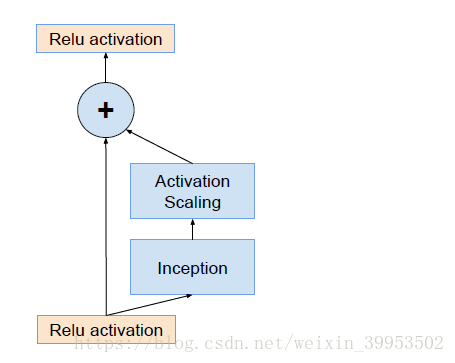
3、Scaling of the Residual
当过滤器的数目超过1000个的时候,会出现问题,网络会“坏死”,即在average pooling层前都变成0。即使降低学习率,增加BN层都没有用。这时候就在激活前缩小残差可以保持稳定。即下图
4、网络精度提高原因
残差连接只能加速网络收敛,真正提高网络精度的还是“更大的网络规模”。
参考
https://blog.csdn.net/loveliuzz/article/details/79135583
https://blog.csdn.net/kangroger/article/details/69218625
https://blog.csdn.net/wspba/article/details/68065564
还有一些其他的,我看到一两个点,但是忘记收藏网站了,如看到会加上,如看到请@我谢谢!