之前我们沿着NLP主线发展一直学习到了BERT,BERT之后的模型我的博客里没有相关的学习笔记,主要是BERT是一个时代的开始,基于Transformer的预训练+微调的时代,后面的好多模型的主体思想和BERT一致,大多只是一些深入研究之后的变体和优化,今天我们用概览的形式一起看一下BERT之后的兄弟姐妹们:
在进入正文之前需要说明在BERT之后出了一个BERT-WMM,采用全词mask机制,在之前的文章BERT!BERT!BERT!中我们已经说过,这里不在赘述。
XLNet
先说XLNet的野心,就是融合自回归模型(如RNN系列、GPT)和自编码模型(如BERT)的优点,先看一下两种模型:
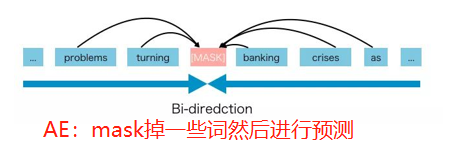
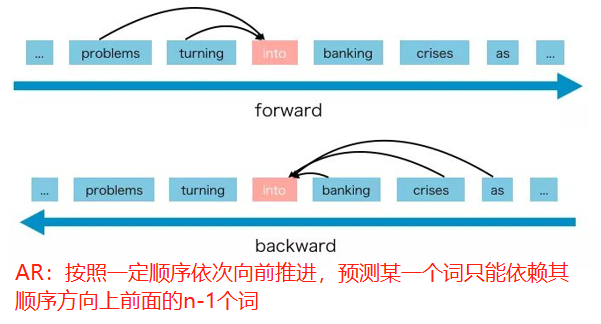
AR可以完成生成类的任务,但是苦于不能充分利用上下文信息;AE是可以双向,但是由于mask在fine-tuning阶段没有,导致AE在fine-tuning阶段的会出现类似数据分布不一致的蒙蔽状态。于是XLNET就想把两者的精髓结合一下,那他具体是怎么做的呢?
两个重要的点:
- Permutation Language Model
- Two-Stream Self-Attention
Permutation Language Model是这样:
先把输入全排列,然后预测某一个固定的词,且只能根据当前排列中排在他之前的词来预测,如下:
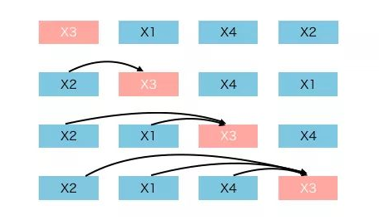
看起来很像AR的感觉,但实际这个被选定的x3又有一种mask的感觉,因为你看放在一个正常的序列中:
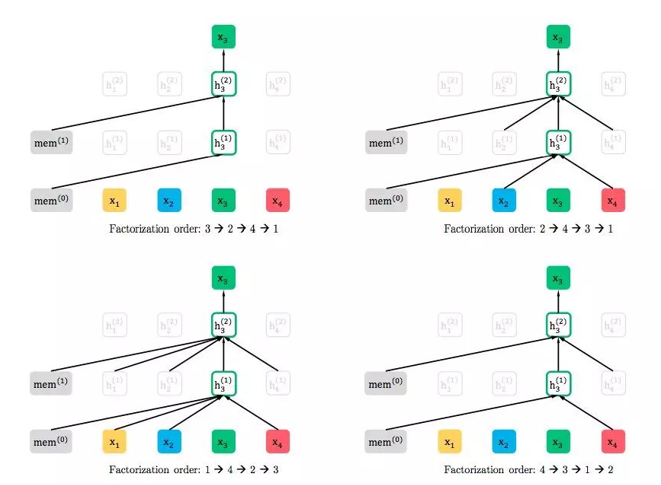
这不就跟mask差不多了嘛,他就是通过这种伪排列的方式进行代替mask的操作的,即利用了上文也利用了下文。
Two-Stream Self-Attention -双流自注意力机制:计算KV的时候,x3能看到自己,但是在计算Q的时候,x3看不到自己。达到mask的效果。同时也是一种AR机制的体现(只能根据前面的词预测当前的词)。
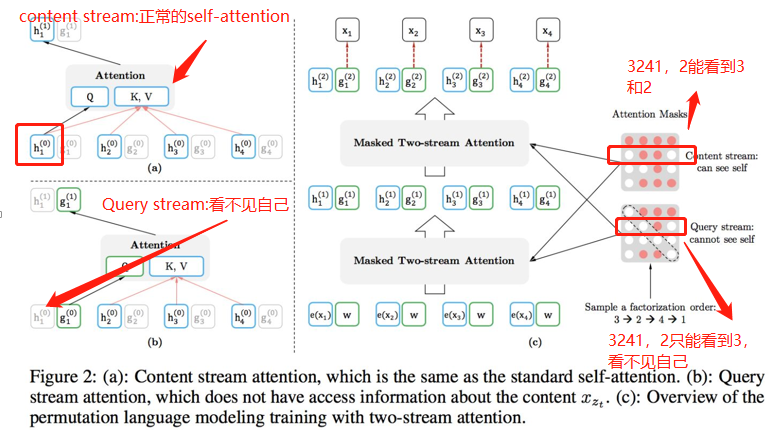
如果还有疑惑,可以查看其他博主的详细解释,看完你会发现上面的图已经说明了一切。哈哈。或者咱看一下原文:
XLNet: Generalized Autoregressive Pretraining for Language Understanding
RoBERTa
RoBERTa其实是BERT PLUS,是BERT的优化版本,整体结构基本不变,具体改进如下:
- 更长的训练时间、更多数据
- 在更长的句子上进行训练(full-sentence的形式:如果输入的最大长度为512,那么就是尽量选择512长度的连续句子。如果跨document了,就在中间加上一个特殊分隔符。)
- 去掉Next Sentence Prediction任务(loss也只算MLM的)
- 使用动态MASK(Roberta是把数据复制10份,每一份中采用不同的静态Mask操作,使得预训练的每条数据有了10种不同的Mask数据。)
- 文本编码(使用的是byte而不是unicode characters作为subword的单位)
ALBERT
轻量级BERT,瘦身依然牛。主要改进:
- 两种减少参数的方法:
- 矩阵分解(研究者对词嵌入参数进行了因式分解,将它们分解为两个小矩阵。研究者不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,而是先将它们映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从 O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显。)
- 参数共享(三种:共享 attention 相关参数、只共享 FFN 相关参数、共享所有参数)
- SOP替代NSP(调换两个句子的顺序预测是不是被调换了)
- n-gram MASK(包含更完整的语义信息,n取1,2,3的概率分别为6/11,3/11,2/11)
ELECTRA
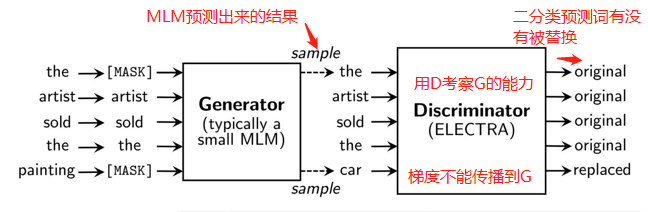
ELECTRA的优化主要是训练上的优化,采用类似GAN的训练方法,在下游fine-tune一个Discriminator模型,用来预测原先的单词有没有被替换。G和D分开训练,D的梯度无法传到G(因为generator的sampling的步骤导致)[GAN的梯度可以从D传到G]。
参考文章
XLNet:运行机制及和Bert的异同比较
XLNet: Generalized Autoregressive Pretraining for Language Understanding
BERT之后的模型有哪些?