Ŀ¼�ṹ
-
- һ�����˼�ʻ����
- ����Դ������
- �����������
- �ġ�����
- �塢modules�������
- ������Apollo 3.0�ĸ���
- �ߡ��ϰ���ʶ��
-
- camera���ֽ���
-
-
- (1)���̽���
- (2)������
- (3)2D-to-3D��ת��
- (4)������
- (5)����
- (6)appģ��
-
- �ˡ�������ʶ��
- �š����̵Ƹ�֪
- ʮ����֪�㷨�������
-
- 1)Lidar��֪
- 2)�Ӿ���֪
-
- (1)����
- (2) CNN���
- (3) CNN�ָ�
- ʮһ����֪�еĻ���ѧϰ
- ʮ������ȫ����
- ʮ�����߾���ͼ������
- ʮ�����ο�����
- ʮ�ġ�д�ں���
һ�����˼�ʻ����
���˼�ʻ��һ�����ӵ�ϵͳ����ͼ1��ʾ��ϵͳ��Ҫ����������ɣ��㷨����Client�����ƶ��������㷨�˰������С���֪�;��ߵȹؼ�������㷨��Client�˰��������˲���ϵͳ�Լ�Ӳ��ƽ̨���ƶ���������ݴ洢��ģ�⡢�߾��ȵ�ͼ�����Լ����ѧϰģ��ѵ����
�㷨��ϵͳ�Ӵ�����ԭʼ��������ȡ���������Ϣ���˽����������������ݻ����仯�������ߡ�Client��ϵͳ�ں϶����㷨������ʵʱ����ɿ��Ե�Ҫ������˵����������60HZ���ٶȲ���ԭʼ���ݣ�Client��ϵͳ��Ҫ��֤�����ˮ�ߴ�������Ҳ����16ms����ɡ���ƽ̨Ϊ���˳��ṩ�������Լ��洢���ܡ�ͨ����ƽ̨�������ܹ������µ��㷨�����¸߾��ȵ�ͼ��ѵ��������Ч��ʶ���١�����ģ�͡�
����Դ������
�ٶȵ��Զ���ʻ��ĿApollo�кü����汾����Ŀǰ��ѧϰ����5.0�汾��Դ���Ǵ�Github���ҵģ�����ΪapolloԴ�롣����������Ŀʵ������Щ�������ҷ�ǽ��ȥ����Ҳһֱ��ʾ����ʧ�ܡ�������ֻ�����������е�perceptionҲ���Ǹ�֪ģ���Ƚ���ѧϰ������Github������ֻ������������Ŀ�ģ�Ҳ������ķ�����DownGit���������ֱ�Ӱ���Ŀ����Ҫ���ص��ļ�����copy��DownGit�Ŀ���У����Download�Ϳ���������Ҫ���ļ��ˡ�
��֪ģ������������ͼ�����ݣ�front_6mm��front_12mm��,128ͨ����Lidar���ݣ�velodyne 128����16ͨ����Lidar���ݣ�lidar_front, lidar_rear_left, lidar_rear_right����Radar���ݣ�radar_front, radar_rear����radarУ���ݣ�����YAML�ļ�����front cameraУ���ݣ�����YAML�ļ������������ٶȺͽ��ٶ�
��֪ģ��������
(1���������
1)3D������
2)����ٶȺͷ���
3)���ͣ�CIPV��PIHP������
4)���ࣺ���������������г�������
5)Drops������Ĺ켣
��2�����������
1)���ߺ�/�����ʽ����
2)�������Ͱ�λ�ã�L1�����³����ߣ���L0�����ߣ���R0���ҳ����ߣ���R1�����³����ߣ�
��3�����̵����
Ŀǰ��û�����̵Ʋ��֣����������ⲿ���ٲ���
�����������
RTOS��ʵʱ����ϵͳ��RTOS����ָ������¼������ݲ���ʱ���ܹ����ܲ����㹻����ٶ����Դ������䴦���Ľ�������ڹ涨��ʱ��֮���������������̻�Դ���ϵͳ����������Ӧ������һ�п����õ���Դ���ʵʱ������������ʵʱ����Э��һ�����еIJ���ϵͳ���ṩ��ʱ��Ӧ�߿ɿ���������Ҫ�ص㡣ʹ��apollo-kernel��֤ϵͳ��ʵʱ�ԣ�2.0�汾����
**��ROS�ĸĶ���**ȥ���Ļ���ʹ��FAST RTPS���������ڴ��������ڵ��Ĵ���Ч�ʣ�ͨ��socket���н����ͨ�ţ���ԭ��֧�� Protobuf����Google��Protobuf��ROS��ȼ��ɣ��Ӷ�������ݵİ汾�����ԡ����������ڵ�ģ��ӿ������Ժ�ͨѶ������Ҳ��������ݡ���һ���ô��DZ�����Զ���ʻ����ʷ������ģ��������Ҳ����һֱ��ʹ�á�https://blog.csdn.net/heyc861221/article/details/80123570����ʹ���� PREEMPT_RT �ں�����ǿ�� ROS ���ڵ� linux ������ʵʱ��
CIPV�� CIPV�ǵ�ǰ��������ӽ��ij�����������3D�߽���ʾ������ϵ�����ͼ��2DͶӰ������λ�ڵ����ϡ�Ȼ���ÿ�������Ƿ��ڵ�ǰ�����С��ڵ�ǰ�����Ķ����У���ӽ���һ������ѡΪCIPV��
protobuf�ļ���
ʹ�� protobuf ���滻 ROS �е� Message ����Ϊ��Ϣ����ĸ�ʽ��protobuf ���������õļ�����֧�֣�ֻ��Ҫ��ʹ���ж���� required �ֶΣ��������� optional �ֶβ��������Ϣ�Ľ������Ӱ�졣
#include "modules/perception/proto/perception_obstacle.pb.h"//������ǵ���protobuf�ļ�
#ʹ�õ�protobuf�������汾Ϊv2
syntax = "proto2";
#������һ��������������C++�е�namespace
package apollo.perception.camera.yolo;
#message��protobuf�еĽṹ�����ݣ�������C++z�е��࣬���������ж���Ҫ����������
#protobuf���������ֶΣ�required��ֵ����Ҫ���ã���optional���ֶο�����0������1������repeated�����ֶο����ظ������Σ�����0�Σ���������C++�е�list�����飩
message YoloParam {
optional ModelParam model_param = 1;optional NetworkParam net_param = 2;optional NMSParam nms_param = 3;
}ProtoBufCodeGen��proto�ļ��ı����������Խ�proto�ļ������**.pas����**�ļ��������ʽ���£�
procedure PrintHelp;
begin
Writeln('Usage:');
Writeln('ProtoCodeGen <input .proto file> [ <options> ]');
Writeln('<options>');
Writeln(' --proto_path=<import path for .proto files>');
Writeln(' -I same as as --proto_path');
Writeln(' --pas_out=<output path for .pas files>');
Writeln(' -O same as --pas_out');
Writeln(' --help');
end;
IMU��IMUȫ���ǹ��Բ�����Ԫ����Ҫ���ڶ�λ��
�ġ�����
���ݷ�Ϊ���¼��ࣺ
**ԭʼ���ݣ�**���ִ���������������ʻԱ��Ϊ�ȡ���������࣬ά�Ȳ�ͬ�����������Ҵ���Ƿǽṹ�����ݣ����ڴ洢�����䡢��������dz������ս��
**��ע���ݣ�**�Ӿ���2D�ϰ������ݡ����̵����ݡ�3D�������ݵȡ�
**�����ݣ�**����������֪�������ij����Լ���������ѧģ�͵ȡ�
**�������ݣ�**��������ģ�������ݡ���ά�ؽ����ݵȡ�
Apollo����������ѵ�����ݣ�
2D���̵�������ʶ��·�ں��̵����ݣ���������ѵ�������Ժ���֤��
2D�ϰ��������糵�������ˡ����г�����������δ֪����ͼ�����ݡ�
3D�ϰ�������ʵ�Ǽ����״���ơ�
�˵��˵��������ṩ�ʺ�end-to-endģ������ݡ�
�������������ؼ��������ע�����糵������������ָͨʾ�ơ��ϰ���ȣ��������������廷����ʶ��
�ϰ���Ԥ��������ѵ��Ԥ���㷨�����ݼ���
���⣬Apollo��������һ����Apollo Scape��ѧ������Ŀ��Apollo Scape���ŵ����������������ӳ̶Ⱥ;��ȷ��涼��ҵ��������Kitty��citi scapes��һ����������Ŀ�����ƶ������Զ���ʻ��ҵ�ķ�չ��
�塢modules�������
�����ͼ����Apollo5.0�汾�ģ�������3.0�汾������Ŀǰ����5.0�汾���Ϻ��٣������汾�����к֮ܶͨ���ģ�������Ҳ�����������
 ������Apollo5.0�еĸ�֪ģ��ṹ��֧���ο������Ӹ�����ĩ��
������Apollo5.0�еĸ�֪ģ��ṹ��֧���ο������Ӹ�����ĩ��
������ base // ������
������ BUILD // ����testdata�����ڲ���
������ camera // ����ͷ �� ��ģ������
������ common // ����Ŀ¼
������ data
������ fusion // �ں�
������ inference // ���ѧϰ�������
������ lib // lib��
������ lidar // �״� �� ��ģ������
������ map // ��ͼ
������ onboard // ������ģ������ �� ��ģ�����
������ production // Cyber����ģ����� �� Cyber�������
������ proto // ���ݸ�ʽ��protobuf
������ radar // ���ײ� �� ��ģ������
������ README.md
������ testdata // ��������ģ��IJ������ݣ�����ѵ���õ�ģ��
��֪ģ��������productionĿ¼��ͨ��lanuch���ض�Ӧ��dag��������֪ģ�顣���Կ�����֪�����˶����ģ�飬��������ͬ�Ĵ�������Ϣ��Lidar,Radar,Camera����������ģ��������onboardĿ¼�У�������ģ��ᶩ�IJ�ͬ�Ĵ�����Topic��Ȼ�����ͳһ����ˮ��(Pipeline)��ҵ��ÿ����ģ�����ˮ����ҵ�ֱ��ڲ�ͬ���ļ�����(camera, lidar, radar)������Ǹ�֪ģ�������Ŀ¼�ṹ������������20�������ģʽ����ȥѧϰһ�£�
inferenceĿ¼ - ���ѧϰ������صĿ⣬��Ҫʵ���˼��ش���caffe���ѧϰģ�ͣ�TensorRT���ѧϰ�Ż����ȡ�
libĿ¼ - �ṩע������̳߳ء�
����kitti�����ӣ���camera���������̵�ʶ�������Ҫ���ţ����������������ͨ��ͬʱҲ������������ӽ������ܵ��š�
��֪����LiDAR�������ݺ����ԭʼ���ݡ�������Щ��������������֮�⣬��ͨ�Ƽ��������λ�Լ�HD-Map������ʵʱad-hoc��ͨ�Ƽ���ڼ������Dz����еģ���˽�ͨ�Ƽ����Ҫ������λȷ����ʱ�εؿ�ʼͨ����������ͼ���⽻ͨ�ơ�
������Apollo 3.0�ĸ���
CIPV���/β�� - �ڵ����������ƶ���
ȫ��֧�� - ����֧�֣���ʵ��Զ�̾�ȷ�ȡ������װ�иߵ����ֲ�ͬ�İ�װ��ʽ��
�첽�������ں� �C ��Ϊ��ͬ��������֡���ʲ��졪���״�Ϊ10ms�����Ϊ33s��LiDARΪ100ms�������첽�ں�LiDAR���״��������ݣ�����ȡ������Ϣ���õ����ݵ�Ĺ��ܷdz���Ҫ��
������̬���� - �ڳ��ֵ�����б��ʱȷ�������Ƕȱ仯����ȷ���������������ƶ��ҽǶ�/��̬��Ӧ�ر仯��
�Ӿ���λ �C ����������Ӿ���λ�������ڲ����С�
������������ �C ��Ϊ��ȫ���ϴ���������Guardianһ�������Զ������ƶ���ͣ����
�ߡ��ϰ���ʶ��
camera���ֽ���
camera�õ�����ͼ��ͼ�������������ѵģ����Ʒ�����Լ�
��������ϰ�������λ�ã��ߴ�ͳ���
һ���������ͷ��һ������������ͷ
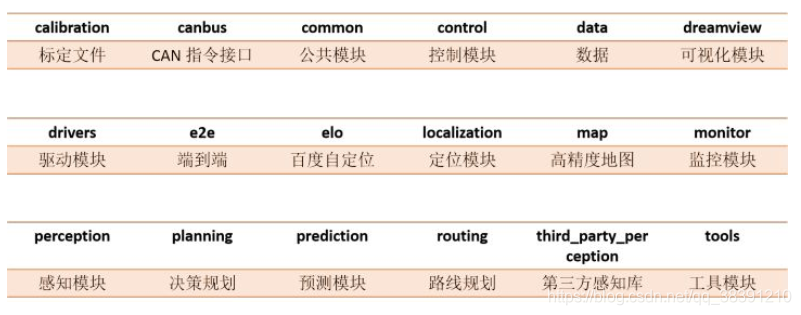
�ϰ����ʶ������camera��lidar��radarһ����ɵġ�camera���ֵ�����Ϊ��������->2D��3D��ת��->camera�����١�
������Ժ������Ĺ������״�������������Ĺ�����
(1)���̽���
�ο����ӣ�https://blog.csdn.net/xiangxianghehe/article/details/82222857
��ԭ���ӣ�https://github.com/ApolloAuto/apollo/blob/r5.0.0/docs/specs/perception_apollo_3.0.md��
(2)������
YOLO����������ͳ������Ļ����������ö�����г������������ﳵ�˺�������𣬲��ɱ�ʾ�ɾ��з�����Ϣ��2-D�߽��YOLO������壬ͼ��ָ�����ߣ�ͬ��Ҳ��ʹ��YOLO��
��̬���壺�����ߺͽ�ͨ�źŵ�
��̬���壺���ij��ó��������������г��ߣ����˻��κ��������壬������������岿λ��
(3)2D-to-3D��ת��
����һ��2D���ӣ���3D��С���������ģ�������������ϵͳ�е�3Dλ�ã���ʹ�ø�2D���ӵĿ��ȣ��߶Ȼ�2D������ƾ�ȷ��3D���롣�˲�����CNN���������Ϊ�˼����˹���Ԥ��
(4)������
��������ͨ����Ч���������������Ϊ����������ݹ��������ṩ·���ͼ��Ķ���֮�������ȷ�������Ӷ����ÿ���������ȷID�������˲�����CNN���������Ϊ�˼����˹���Ԥ��
�ٲ���Kalman�˲������ٱ������������������ٶ�Ҫ�죨��Ϊǰ���Detectionģ���Ѿ��ķѺܶ�ʱ���ˣ�����Detection��model������������һ��feature map��feature map�����Ƕ�ͼ��߲�����Ŀ̻�����feature map��һЩroi pooling���õ��ϰ��V���feature����ʱ�õ����ϰ��V���feature���������٣����������Ѵ�ͳ�ĸ���ģ��ļ������ܴ������������һ���ָ������ˡ�Ҫ�������CNN��������������ȣ������Կ�����������Metric learning����ר�����instance��feature������������Metric learningҲ�Ǻ��ƾõģ�
(5)����
һ��������ϵͳ�������ѧϰģ�ͣ�����Ҫ��һЩ������������ֱ���������ģ�飬�Ժ�����Ӱ��Ƚ�ֱ�ӡ����Ӿ���֪�У�������Ҫ��Ϊ�������֣�
��һ��2D-to-3D�ļ��μ�������Ҫ���ǵ����ذ��������pose��Ӱ�죬�ӵص㣬�ȶ��ԡ��ڶ���ʱ����Ϣ��������Ҫ����Ը��ٴ�������Ҫע�����¼��㣺�����֡�ʺ���ʱ��Ҫ��Ҫ����ٱ�����һ����������ģ�飬��Ϊ����Ѿ�ռ�ݴ�ʱ�䣬������ü��ģ�͵������Ϣ�����������ȣ����и��٣����Կ���������Metric Learning��������������Ļ����ں���������־����ںϲ��ԣ�Ҫ������Ұ�ص� �����������ɹ�ʽ��ʾ�ļ��μ������⡣

(6)appģ��
���е�.cc�ļ���Linux�µĺ����൱��.cpp��
�ˡ�������ʶ��
�ָSegmentation����detection�ڱ�������һ���ģ��Ƕ�һ��Ŀ��IJ�ͬ���ȵĿ̻����ָ���һ�ָ�ϸ���ȿ̻�����߽���Ϣ�ļ�ⷽ���������ǻ����ǽ��б�Ե�ָ�ڸ�֪�У����ڲ��������壬������Ҫ���зָ�������糡���ָ�Ϳ���ʻ�����֪�������ָ�������ڶഫ�����ںϣ��������ֲ���зָ���LiDAR���ƣ��Ϳ��Բ����ֲ�����;��롣����ʻ��������Զ�һЩ�ǽṹ����·��·���滮�ṩ֧�֡��ڳ����߸�֪�У�Ӧ�Ӿ������ʹ�÷ָ����ⷽ����
�������������͵ij����ߣ�������Ƕκ����������ߡ�
������Ƕ������Ӿ���λ����������������ʹ���������ڳ����ڡ�
��ͨ�������ɶ������߱�ʾ��������һ�������ߣ�����ߣ��Ҳ��ߺ���һ���Ҳ��ߡ�
���������������ij�������ͼ��ͨ����ֵ�����ɷֶεĶ�����ͼ��
�÷��������ҵ����ӵ����������ڲ�������
Ȼ�����������ҳ�������ϵ�ĵ���ռ��е�������Ե���ɳ�����ǵ㡣
֮��������Щ��������������Ӧ����Կռ䣨���磬��L0�����ң�R0��������L1�����£��ң���L2���ȣ���ǩ�����ɳ����߶����������
������ʶ��Ĺ��̣�CNN�ָ���Ƚ���CNN�ָ�ٽ��к���������������ϣ�������ϳ�һ�����ߣ������Ͷ�䵽3D�ϡ���Apollo���������
�����ڳ��Բ���CNN���Գ����߽���ʶ��
�š����̵Ƹ�֪
���̵Ƹ�֪���������ھ���ֹͣ��50��-2�ķ�Χ�ھ�ʶ����̵�����״̬�������ѵ����ڼ�⾫��Ҫ��dz��ߣ�����ﵽ�����ţ�99.9%�����������ִ���ƣ�Υ�����������������ٻ�Ҳ����̫�ͣ�����һֱ���̵ƣ�����һ��ֻ�ٻ�һ֡�̵ƣ���������Ϊ��ʶ����ĺ�ƣ���ͨ����·�ڣ�Ӱ��ͨ���ʺ����顣�ڶ��Ǻ��̵Ƹ�֪��ҪӦ�Ը��ֻ����������������ա�����Ǻ��̵Ƶ���ʽ�dz��࣬�������롢�߶ȡ����ݡ��ź�״̬�ȣ����̵Ƹ�֪����Ҫʶ��
�Զ���ʻ��ʹ�����ѧϰ���к��̵Ƹ�֪ģ��Ĺ�������Ҫ��Ϊ���¼�����
��һ�����ѡ��Ͱ�װ���ڶ��Ǹ߾���ͼ�Ľ��������ʹ�����ѧϰʶ�����ɫ�ı仯����Ҫ��Ϊ������ɫ����������
ʮ����֪�㷨�������
1)Lidar��֪
��1��Lidar��֪������ʽ����Ncut��DL����CNNSeg
��2���Ӿ���֪��DL���ͷָ���٣�2d-to-3d��������ںϣ����̵ƣ���֪�͵�ͼ������
2)�Ӿ���֪
(1)����
 ���������֤��ȫ��ģ�ͻ���goodcase��badcase
���������֤��ȫ��ģ�ͻ���goodcase��badcase
2D��3D��֪������ ���˼�ʻ�е�detection��������������Ҫ��3D��Ϣ���ϰ���ijߴ磬����ǰ֡�ļ��Ҫ������ʷ֡Ҳ���Ǿֲ�end-to-end����������Ҫ����Ϣ���ϰ������Ե�ʶ��β�ƺͳ��ţ�������ͳ����2D�ģ�ֻ���bounding box�����
��ⲿ�ֿ��Բο���������������ⷽ��ġ�
��ͳֻ��Ҫǰ����������Ҫ���ӡ�Ŀǰ�����Ķ��ǻ���cv��������ȫӦ����ad��autonomous driving��
�Ӿ���֪�����ṹ��ͼ��ʾ��
(2) CNN���

(3) CNN�ָ�
CNN�ָ��CNN��Ȿ������һ���ġ����ڸ����糵��ʹ��CNN��⣬�������һЩ����������ʹ��CNN�ָ��Ϊ�������CNN�����ס�ܹ�������Ϣ�������ڳ����ߣ�����ʻ����ȶ�����CNN�ָ
ʮһ����֪�еĻ���ѧϰ

ʮ������ȫ����
�Ӿ���֪Ҫ��֤�ȶ��ԣ�������һ֡����10m����һ֡����20m��
ʮ�����߾���ͼ������
��1���������˳��ļ����������������һ�����̵ƣ�����Ҫ���˳��Լ����㣬ͨ���߾���ͼ���Կ�����
��2��������ǰ֪��ǰ�����ʲô���Ҹ��˾����������ͼ�����
ʮ�����ο�����
��1������ϸ�Ľ����˸�֪ģ��
��֪ģ������ĵ�
��2���ٷ�Github�ĵ�
Apollo��Github�ٷ��ĵ�
��3����֪ģ��ṹ
��֪ģ���ܽṹ
ʮ�ġ�д�ں���
������������Զ���ʻ��Ŀ���DZȽ��ѵģ�ÿ�ܶ�Ҫ���ܶ�ʱ��ѧϰ��ÿ�ν��Լ��ҵ��������Լ��Լ��������˼��д�ڲ����ϣ����ں���IJ鿴�������Ѿ��Ѹ�֪ģ��Ĵ���ܹ���camera�����õ����㷨��ʵ�����̶�������ˣ���һ����һ��˼����ô�������и�֪ģ�飬����cameraģ��鿴�����һ��ʵ������������֮���������������Ŀ��ÿһ������ѧ��˼�ڲ����С�