һ������
1)Siamese network
�����������ݼ���˵�����ǵ����������еģ����Ƕ���ÿ�������˵������ֻ�м�����������ô�÷����㷨ȥ���Ļ�������ÿ����������̫�٣����Ǹ���ѵ������ʲô�õĽ��������ֻ��ȥ�Ҹ��µķ��������������ݼ�����ѵ�����Ӷ������siamese network��iamese�����������ȥѧϰһ�������Զ����������ѧϰ�����Ķ���ȥ�ȽϺ�ƥ���µ�δ֪������������������ܱ�Ӧ������Щ��������������ѵ������������֮ǰ����ѵ���ķ������⡣
2)channel-wise
ע��������attention�����������ͣ�spatial attention��channel-wise attention������channel-wise attention�Ƕ�������ͼ�е�ÿһ��ͨ����channel������ֵһ��Ȩ�أ�����õ�һ��������ͨ������CHW��feature map��spatial attention��HWƽ��Ȩ�ز�ͬ��CȨ����ͬ��channel attention��CȨ�ز�ͬ��HWƽ��Ȩ����ͬ��Channel attention��ע����ʲô����spatial attention��ע�����Ķ�����
��μ���Ȩ��һ���Ϊ�������裺
���һ����ֺ��������ÿ��attention�����������һ��score ���Ĵ�����ݾ��Ǻ�attention����ע�Ķ���ʵ����һ������������س̶ȣ�Խ��أ�����ֵԽ��
�����õ���K��score Si��ͨ��softmax�������õ�����Ȩ�ء�
channel-wise�Ĺ������£�

3)Ŀ������㷨
Ŀ���Ӿ�����(Visual Object Tracking)����ұȽϹ��Ϸ�Ϊ�����ࣺ����(generative)ģ�ͷ������б�(discriminative)ģ�ͷ�����Ŀǰ�Ƚ����е����б������Ҳ�м�����tracking-by-detection��
��1������������ڵ�ǰ֡��Ŀ������ģ����һ֡Ѱ����ģ�������Ƶ��������Ԥ��λ�ã��Ƚ��������п������˲��������˲���mean-shift�ȡ�
��2���б������CV�еľ�����·ͼ������+����ѧϰ����ǰ֡��Ŀ������Ϊ����������������Ϊ������������ѧϰ����ѵ������������һ֡��ѵ���õķ���������������
��3������˲���������CF��CSK, KCF/DCF, CN��
��4�����ѧϰ�����SiamFC��SiamFC-R��
������(generative)�����������Զ����������б���(discriminative)�����л���ѧϰ�����ķ�����ʡ�������ָ����Է�ӳ����˲�����ĸ������Ŷȣ�ǰ������������Ӧֵ����û��������Ӧģʽ��
���ڣ�������������������㷨�����˺ܶ��˵�ע�⣬��Ϊ������������Ժ���Ч�ԡ������������SiamFC������һ��������ȫ�������磨Siamese fully convolutional network����SiamRPN������ regional recommendation network������˷���ͻع顣
��Щ������������������㷨���ǰ�VOT�������һ����������⣨ cross-correlation problem����ѧϰһ������ͼ���о�������ʾ����������֮��Ļ�����ԡ�
��������Ŀ���ѧϰ�ɿ����������������ѧϰ���������ѧϰһ������f(x,z) ���Ƚ�����ͼ�� z ������ͼ�� x �������ԡ��������ͼ����������ͬһ��Ŀ�꣬�ظ߷֣����صͷ֡������������������ģ�⺯�� f������Ⱦ���������������ѧϰ����͵ľ��������ṹ��
4)SiamFC
��ν�����ṹ������˼�壬��Ϊ�ɶԵĽṹ��������˵���Ǹýṹ���������룬һ������Ϊ����ģ�壬��һ������Ҫѡ��ĺ�ѡ���������ڵ�Ŀ����������У���Ϊ����ģ����������Ҫ���ٵĶ���ͨ��ѡȡ������Ƶ���е�һ֡�е�Ŀ�������ѡ��������֮��ÿһ֡�е�ͼ����������search image��������������Ҫ���ľ����ҵ�֮��ÿһ֡�����һ֡�еķ��������Ƶĺ�ѡ����Ϊ��һ֡�е�Ŀ�꣬�������ǾͿ���ʵ�ֶ�һ��Ŀ��ĸ��١� SiamFC��������ṹ���£�
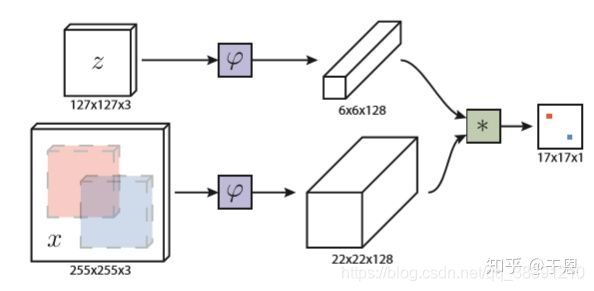
�ýṹ����zΪ����ķ���������һ֡ͼ���е�Ŀ���СΪ127x127x3��xΪ���������ͼ��СΪ255x255x3�����Ŷ���������ֱ���б任�����߲�����AlexNet������ṹ������Ϊ������ȡ����\varphi������������ȡ�����ֱ�������6x6x128��22x22x128������ͼ��feature map������ȡ������֮���ٶ���ȡ���������л���ز����������������������Ӧͼ(heatmap)��
����ز����Ĺ�ʽΪ��f(z,x)=g(��(z),��(x))f(z,x)=g(\varphi(z),\varphi(x))f(z,x)=g(��(z),��(x))
5)�Կ�������Adversarial example��
�Կ�������ͨ���㷨������ɾ���������صĶԿ���������������ֱ���ڸɾ������������������Ŷ���pixel perturbation�������ɣ�Ҳ���������ӶԿ�������adversarial patch�������������ӵ������Ŷ���
6)���
������֪��ģ����ص����ж���������ģ�͵Ľṹ��ģ�͵IJ�����ģ�͵ĸ�����ѵ��Ȩ�ء������ǻ��ڰй�����
7)one-pass evaluation (OPE)
1�� Precision plot
**���㷨���Ƶ�Ŀ��λ�ã�bounding box�������ĵ����˹���ע��ground-truth����Ŀ������ĵ㣬�����ߵľ���С�ڸ�����ֵ����Ƶ֡�İٷֱȡ�**��ͬ����ֵ���õ��İٷֱȲ�һ������˿��Ի��һ�����ߡ�һ����ֵ�趨Ϊ20�����ص㡣������������ȱ�㣺����ӳĿ�������С��߶ȵı仯��
2) Success plot
���ȶ����غ��ʵ÷֣�overlap score��OS�������㷨�õ���bounding box����Ϊa������ground-truth����box����Ϊb�����غ��ʶ���Ϊ��OS = |a��b|/|a��b|��overlap score��ʵ���ǽ����ȡ���ijһ֡��OS�����趨����ֵʱ�����֡����Ϊ�ɹ��ģ�Success�����ܵijɹ���֡ռ����֡�İٷֱȼ�Ϊ�ɹ��ʣ�Success rate����OS��ȡֵ��ΧΪ0~1����˿��Ի��Ƴ�һ�����ߡ�һ����ֵ�趨Ϊ0.5��
����ժҪ
�ڼ�����Ӿ������У��������еĶԿ�������������֪��ÿ�������ʵ�����ģ������Ϳ���ͨ�������ţ��Ӷ�ʵ������ѵ�������Ƕ����Ӿ������٣�visual
object tracking�����ԣ����ٵ��������������Dz�֪���ġ�Ȼ�������㷨�����Ǵ��ڱ�������DZ�ڷ��յģ������Ϳ���������ƭ���ϵͳ��Ϊ�˶�DZ�ڵ�Σ��������������Ĺ�ע��attention���������о��������㷨�ĶԿ���������ƪ���������һ�����͵�one-shot���͵ĶԿ�����������������ģ�͵ļ��������㷨��free-model single object tracking�������Կ���������ʵ������Ŀ�������ϼ���ϸ���Ŷ����Ӷ��������������ļ�֡�϶���ʧ���塣������ԣ������������̰����������֣�����ͨ��˫��ע����������ʵ�֡���һ��������ͨ��confidence attentionע�����������Ż�batch confidence���ڶ���������ͨ��channel attentionע�����������Ż�feature loss����3��benchmark������ʵ�飬ʵ��������IJ��õķ��������ںܴ�̶��Ͻ��ʹֻ���������������㷨����ȷ�ȡ�
��������
�Ӿ������٣�VOT����������ϵͳ��ʵ����ȫ�豸�в����˺ܴ�����á�������꣬�Ӿ��������㷨�о����˺ܶ�ͻ���ԵĽ�չ���������������SiamRPN++������OTB100���benchmark�ϴﵽ��91%��ȷ�ʡ�Ȼ�����������ѧϰ���������㷨�Ƿ������ôǿ�����������ֵ������˼���ġ�
�������ѧϰģ�͵ĶԿ������ǽ������ܹ�ע��һ�������кܶ�����������ĶԿ��������Գɹ�����ƭͼ����������������������磬Szegedy���о���������ͼƬ����һЩϸ���Ŷ��Ϳ����������Բ��������Ӿ�ϵͳ��ʶ�𣬴Ӷ�������ƭģ�ͣ���������ࡣ�������е���Щ���������ǻ�����ģ�͵ģ���������֪������������������ ��ʵ�ϣ���ijһ���ض�֡��һ����ģ�͵�Ŀ�����������ӶԿ����Ż��������������ļ�֡�϶���ʧ���塣��ˣ��о������Ӿ����㷨�ĶԿ������Ǻ����õģ����Ե�������DZ��Σ�ա����ǣ����ߵ��Ӿ����Ǻ�����ǰ֪�����ٵ���������ġ���Σ����Ǻ���ͨ���Ż������Կ���������Ϊ�����ٵĹ����Dz�ͬ�ڶ���������������ֻ��Ҫ���ij��ֵ����ʵ������ÿһ��֡�����Ǹ�����������һ���ģ���ʵ���ǰ����еĺ�ѡ��鵽����������Ĺ鵽����������ķ�����������������˺ܶ����ѣ���ΪҪʹһ����ѡ��ѡ��������������Ŷȣ�confidence����
���ĵĹ���������Siamese network�����źܸߵ���ȷ�Ժ�Ч�ʡ����Ķ���һ����Ƶ�е�һ����ʶ֡������ֵ����С���Ŷ����Ӷ�ʵ�ֽ�������֡������������������ͨ��˫��ע���������������Կ��Ŷ��� ���������������֣�ÿһ��loss����ע����Ȩ�أ�attention weigh�����ϡ���Ҫ��������ĺ�ѡ��ͬʱ�̼��еȵĺ�ѡ�� Ϊ�˸��õ���������ĺ�ѡ���ھ����ע�������Ʊ��������������ѡ��ľ��롣ͬʱ��������ɾ���ͼƬ����Ӧ�ĶԿ�����֮��ľ��롣
���еĶԿ����������������⣺
��1�����еĶ������ѧϰ���㷨�Ĺ����ǻ����Ѿ���ǰ֪�������������Բ�����free-model��
��2�����еĶ������㷨�Ĺ����Dz�ͬ�ڶ�����㷨�����ģ���Ϊ���ڶ����Ĺ�����ֻ��Ҫ��ڶ���confidence���Ŀ����ԾͿ����ˡ������ĵĻ���������������㷨�Dz��ܵ���ʹ�����ַ����ġ�
�ġ�contribution
��1����һ���о���VOT�ϵ�one-shot�Կ�������
��2��ͨ��ʹ��˫��ע�����������Ż������Կ��Ŷ���
��3��������benchmark���нϺõ�Ч��
�塢����
1)���ⶨ��
VOT����Ϊ��Ҫѧϰ�õ�һ������ͼ���������ͼ��similarity map����ͨ������������ʾ����������Ļ�����ԣ�correlation���õ��ġ��������ƺ�����siamese similarity function����Ŀ��ģ�壨target template ���ڵ�һ֡���Ǹ����Ĺ̶���ֵ��
one-shot��˵ֻ����Ƶ�ĵ�һ֡ͼƬ���м�С�������Ŷ���
�����о��Ļ����ٵĹ������⣬�������кܴ�����ģ���������:
��1������������֪���������ģ����������ߵ�ѵ��һ����ģ�͡�
��2����ʧ�ܵĶ����Dz�ͬ�������ģ��ٵ�Ŀ����Ҫ��ڶ������Ŷȵ����Ŀ����ԣ��������䳬����ȷ���Ŀ����ԡ�
��3�����IJ��ø�˹���ڣ�Gaussian window���������������е�box������Ŷȡ����磬Ϊ���ù�������ǿ����������ѡ����Ŀ�����������Զ��box����Ϊ��õ�Ŀ�꣬��������Զ�����box���������ױ���˹������ѹ�������Ը�����������ʧ�ܡ�
���Ĺ�������Ҫ�������£�
��1��ֻ�ڳ�ʼ֡�Ϸ��öԿ��ţ�Ҳ����one-shot������
��2)���ĵĶԿ���������Ҫ�ܹ�ͬʱ�Ժܶ��box����в�������������������Ĺ����ɹ��ʡ�������ԣ����Ĺ���������ߺܶ��������box������Ŷȣ�ͬʱ���ͺܶ������box������Ŷȣ��Ӷ�����������������������Ԥ��box��
��3�����IJ�������loss������һ����batch confidence����һ���Ƕ������к�ѡ����й�����feature loss������������loss����������Ҫ����ע�������ơ�
2)����ʵ��
��1��loss����
ʵ��Ŀ����ֻ�ڵ�һ֡�ϼ�����?z������ʹ�������ٽ��ƫ��ԭʼ��ground truth��
z?=arg?min?�Ozk?z?k�O�ܦ�L(z,z?)z^*=\argmin_{|z_k-{z^*}_k|\le\varepsilon}L(z,z^*)z?=�Ozk??z?k?�O����argmin?L(z,z?)
st �Ozk?zk?�O�ܦ�|z_k-z^*_k|\le\varepsilon�Ozk??zk??�O����
����z?k{z^*}_kz?k?��ʾ����Ⱦ�˵�ͼ������أ�zkz_kzk?��ʾ�ɾ�ͼ������ء�����֮��IJ�ֵ����ҪС����\varepsilon����
����loss�����ľ������£�
��1��batch confidence��ʧֵ
L1=��R1:pf(z?,xi)?��Rq:rf(z?,xi)L_1=\sum_{R_{1:p}}f(z^*,x_i)-\sum_{R_{q:r}}f(z^*,x_i)L1?=��R1:p??f(z?,xi?)?��Rq:r??f(z?,xi?)
st �Ozk?zk?�O�ܦ�|z_k-z^*_k|\le\varepsilon�Ozk??zk??�O����
����f(z?,xi)f(z^*,x_i)f(z?,xi?)�������ÿһ����ѡ���confidenceֵ��
����R1:pR_{1:p}R1:p?ָ�����ź����ǰ��p��confidence���ĺ�ѡ��Rq:rR_{q:r}Rq:r?ָ���Ǻ���q-r�ĺ�ѡ��
������Ϊ�����Ƹ�confidence�ĺ�ѡ��ͬʱ�̼���confidence�ĺ�ѡ����Ȼ������û��˵����������Ӧ�þ�����С�����loss�����ɡ�
��2��feature;��ʧֵ
L2=?��j=1:C�O�O��j(z?)?��j(z)�O�O2L_2=-\sum_{j=1:C}||\varPhi_j(z^*)-\varPhi_j(z)||_2L2?=?��j=1:C?�O�O��j?(z?)?��j?(z)�O�O2?
st �Ozk?zk?�O�ܦ�|z_k-z^*_k|\le\varepsilon�Ozk??zk??�O����
����Cָ��������ֵ����ĿΪC������j\varPhi_j��j?��������ٵĽ��������z?z^*z?��ʾ����Ⱦ�˵�ͼ��z��ʾ�ɾ�ͼ�������Ҫ��С��L2L_2L2?,Ҳ�������������֮���2-��ʽ������ֵ��
��2��˫��ע��������
��loss�����м���ע����������Ϊ�˸��õ���߹�����Ч��������ע����������ʵ������loss�����м�����ƺõ�attentionȨ�أ�weight����
��1��Con?dence Attention
L1?=��R1:pwi?f(z?,xi)?��Rq:rf(z?,xi)L^*_1=\sum_{R_{1:p}}w_i�� f(z^*,x_i)-\sum_{R_{q:r}}f(z^*,x_i)L1??=��R1:p??wi??f(z?,xi?)?��Rq:r??f(z?,xi?)
st �Ozk?zk?�O�ܦ�|z_k-z^*_k|\le\varepsilon�Ozk??zk??�O����
���е�wi=1a+b?tanh(c?(d(xi)?d(x1)))w_i=\dfrac{1}{a + b �� tanh(c �� (d(x_i) ? d(x_1))) }wi?=a+b?tanh(c?(d(xi?)?d(x1?)))1?, d(xi)d(x_i)d(xi?)ָ�����ź�������Ŷ��б��еľ��루���ﲻ���⣩������a��b��c��������������
Ϊ�˸��õ�����������ĺ�ѡ��ʹ�û��ھ����ע�������ƣ� distance-oriented attention mechanism����������õļ�����ѡ��֮��ľ��롣
�Ҿ��������Ȩ�ؼ���ĺ����������ģ�û�м�Ȩ�ص�ʱ��ǰ��p����ѡ���confidence�����Ƴ̶���һ���ģ�����Ȩ�ص�Ŀ������Խ����Ҳ����Խ��ǰ�ĺ�ѡ�����Ƶij̶ȸ��Ӷ����õ���������ĺ�ѡ���ǡ�
��2��Feature Attention
ʹ��channel-wise���������ֲ�ͬͨ������Ҫ�ԡ�
L2?=?��j=1:C�O�Owj{��j(z?)?��j(z)}�O�O2L^*_2=-\sum_{j=1:C}||w_j\{\varPhi_j(z^*)-\varPhi_j(z)\}||_2L2??=?��j=1:C?�O�Owj?{
��j?(z?)?��j?(z)}�O�O2?
st �Ozk?zk?�O�ܦ�|z_k-z^*_k|\le\varepsilon�Ozk??zk??�O����
���е�wj=1a+b?tanh((m(��j(z))?m(��j(z))min))w_j=\dfrac{1}{a + b �� tanh((m(��_j(z)) ? m(��_j(z))_{min})) }wj?=a+b?tanh((m(��j?(z))?m(��j?(z))min?))1?
����m(��j(z)m(��_j(z)m(��j?(z)�ǵ�j��ͨ��������ͼ��ƽ��ֵ��m(��j(z))minm(��_j(z))_{min}m(��j?(z))min?������ͼ��ƽ��ֵ����Сֵ�������wjw_jwj?���ǵ�j��ͨ���ϵ�Ȩ�أ��������Ȩ��������Ҫ��һ���������Ȩ�صļ��������ʵ��attention���Ƶ�һ��Ȩ�ؼ�����������Ƶġ�
(3��Dual Attention Loss
L=��L1?+��L2?L = ��L^*_1 + ��L^*_ 2L=��L1??+��L2??
��Ҫ��С��L�����ʧ�����������ʧ�����ǽ���������L2?L^*_2L2??��L1?L^*_1L1??��������ʧ������
��3����������
���룺��Ƶ�еĵ�һ��ͼ��֡z�Լ�������f
������Կ�����z?z^*z?
��ʼ��������������=0��z?=zz^*=zz?=z
���裺���ȵõ�con?dence map f(z,xi)f(z, x_i)f(z,xi?).����zָ����ԭʼ��ͼƬ��xix_ixi?ָ�������������ڵõ�con?dence map�����������õ���ʼ������rank��R0[1:n]R_0[1 : n]R0?[1:n].
ѭ�����й���������<100��ʱ�������й��������������ı�־�У���=100������R0[1:n]R_0[1 : n]R0?[1:n]�еĵ�һ����ѡ���Ѿ�����p�������������
����evaluation
1��ʵ���������
��1��ָ��
������benchmark�Ͻ�����ʵ�飬 OTB100 , LaSOT��GOT10K��ʵ�����������SiamFC, SiamRPN , SiamRPN++�� SiamMask��SiamRPN++�����ֲ�ͬ������ṹ��ResNet-50��MobileNet-v2����
���õ�����ָ�����£�
(1)one-pass evaluation (OPE)
- Precision plot
- Success plot
�������ֳ�����������ʽһ�㶼����ground-truth��Ŀ���λ�ó�ʼ����һ֡��Ȼ�����и����㷨�õ�ƽ�����Ⱥͳɹ��ʡ����ַ�������Ϊone-pass evaluation (OPE)�����ַ�����2��ȱ�㡣һ��һ�������㷨���ܶԵ�һ֡�����ij�ʼλ�ñȽ����У��ڲ�ͬλ�û���֡��ʼ����ɱȽϴ��Ӱ�졣���Ǵ�����㷨��������ʧ�ܺ�û�����³�ʼ���Ļ��ơ�
ʵ����ϸ��������ʾ��
ͨ��pytorchʵ�֣���������NVIDIA Tesla V100 GPU�ϡ���ÿ����Ƶ֡����ʹ��Adam�Ż������Ż�����öԿ��Ŷ������õ�������Ϊ100�Σ�ѧϰ��Ϊ0.01��
��2����������
Adam�Ż����Ķ������£�
Adam ���������Դ������Ӧ�ع��ƣ�Adaptive Moment Estimation����Ҳ���ݶ��½��㷨��һ�ֱ��Σ�����ÿ�ε���������ѧϰ�ʶ���һ���ķ�Χ��������Ϊ�ݶȺܴ������ѧϰ�ʣ�������Ҳ��úܴ�����ֵ��ԱȽ��ȶ���dam �㷨�����ݶȵ�һ�ع��ƺͶ��ع��ƶ�̬����ÿ��������ѧϰ�ʣ�����ƫ��У����ÿһ�ε���ѧϰ�ʶ��и�ȷ����Χ��ʹ�ò����Ƚ�ƽ�ȡ�
���ڲ�ͬ��ע����ģ�飬���в�ͬ�ij���������confidence attentionΪ��������a=0.5��b=1.5��c=0.2.����feature attention������a=2��b=-1��c=20.�� = 1������0.2-0.8֮�䡣p=45��q=90��r=135.
2���������
��1��OTB100
���ȼ���Precision������ֵ����Ϊ20���ټ���Success������ֵ����Ϊ0.5.��ͼ���Կ�����PrecisionԽ�ߣ�SuccessӦ����Խ�͵ġ���OTB100���ݼ��ϼ�����������ֵ���Ա�ԭʼ��ָ�꣬�����������ָ���Լ����ǹ������ָ�ꡣ���Կ��������ǹ����Ľ���ȼ��������Ľ���úܶࡣ���������� SiamFC,SiamRPN, SiamRPN++?, SiamRPN++(M)���ĸ��㷨ģ�͵�precisionֻ������ 3.1%, 4.5%, 6.4%�� 5.7%�������ǹ���������49.4%, 59.8%, 57.7%,��51.1%��
��OTB100���ݼ��ϣ��Ա���ԭʼ�Ľ���Լ�ͨ�����ǹ�����Ľ�������һ�����precision plot��success plot�����Կ������ڱ�������precision��success����������½���������������� SiamRPN�� SiamRPN++?�ϱ��ֵ���ã���precision���ָ����ԣ��½���46.2% ��44.4%��
��2��LaSOT
�ԣ�����ɼ�ԭ����
��3��GOT10K
�ԣ�����ɼ�ԭ����
��4������
ͨ���۲�ʵ�������֣�SiamFC��OTB100��LaSOT�϶��кܺõ�³���ԣ������ƶ�����Ϊ���IJ��õ��㷨Ƿ��ϵ��µġ�SiamFC���Կ�����ֻ��һ��anchor�� SiamRPN����̫�ٵ�anchor��ʹ��SiamFC����ȷ������target������Ҳʹ���������ױ����������ĵĹ��������� SiamRPN����õĹ���Ч������������Ϊ SiamRPN�IJ���̫��ʹ�������ѱ���ȫѵ������������� siamRPN++�õ��˽������Ϊ siamRPN++ʹ���˶༶�ܹ�ѧϰ��multi-stage learning���������и�����Ч�Ļ�����ԣ�cross-correlation����������Ϊ���������� siamRPN++�и��õ�³���ԣ����Ա����������ĵĹ����ֶ���SiamMask�ϵĹ���Ч�����������ΪSiamMask�Ƕ�����ѧϰ��multi-task learning������Ƚ�SiamRPN
��SiamRPN++��SiamMask���ӹ�ע�����ؼ���ʹ��ѧϰ�����������Ӿ���³���ԡ�
3�� Ablation Study
��ʧ����ֻ����L1L_1L1?��L1?L^?_1L1??��L2L_2L2?��L2?L^?_2L2??��L1?+L2?L^?_1+L^?_2L1??+L2??��L1+L2L_1+L_2L1?+L2?���ԱȲ鿴��������Է��֣�ͬʱ����˫��ע���������µ�������ʧ����L1?+L2?L^?_1+L^?_2L1??+L2??����õġ�
4�� Qualitative Evaluation�����Է�����
 ����Ƶ֡�Ͻ��в��ԣ����Կ���������������Կ�������������ĶԿ��Ŷ���ʵ���������ۿ��������ģ����������ٵĽ���кܴ�Ӱ�졣���У���SiamFC ��SiamRPN�Ĺ���Ч���������Եģ���SiamRPN++�Ĺ���Ч��û����ô���ԡ�
����Ƶ֡�Ͻ��в��ԣ����Կ���������������Կ�������������ĶԿ��Ŷ���ʵ���������ۿ��������ģ����������ٵĽ���кܴ�Ӱ�졣���У���SiamFC ��SiamRPN�Ĺ���Ч���������Եģ���SiamRPN++�Ĺ���Ч��û����ô���ԡ�