�����ѧϰpytorch��ģ��ѵ�����̣�ע���moduleģ����train��eval����������train��������ģ��ѵ��֮ǰ����ʾ����ѵ��ģʽ�����ģ������BN���Dropout�㣬��������eval����ģ�Ͳ��Ժ���֤ʱ����ʾ����ģʽ��������ģ���е�BN���Dropout�㡣�������������DZȽϺ�����ģ�Dropout������Ҳ�Ƚ���Ϥ������NLP������BN��Batch Normalization���㲻�Ǻܳ�����ͨ������ʹ��layer nomalization�����Ծ�ѧϰ��һ�¡�
Batch Normalization
BN��������˵��һ����һ���㣬��һ��������������Ӧ�ù㷺��Ϊʲô��Ҫ�й�һ�����أ�������ѵ��ǰ��ÿ��batch�����ݷֲ������кܴ������ģ�Ͱ���ÿ��ģ�͵���ʵ���ݷֲ�����ѧϰ�͵�������ô���ܻ��������ٶȡ�����ѵ�����ݺͲ������ݵķֲ�Ҳ���ܲ�ͬ������������ѵ��ǰ������һ��Ԥ�����������ģ�͵�ѵ���ٶȺͷ��������������ѵ�������У����ݾ���������ǰ������ܻᷢ��һЩϸ�ı仯��������仯����������Ĵ��������ܻ�Խ��Խ��ɢ��ѵ�����ݵķֲ�һֱ�ڱ仯�Ļ���ģ�͵�ÿһ�㶼Ҫ����ѧϰ�͵���������Ҳ��Ӱ�쵽ģ��ѵ���ٶȣ��������ͽ�Ư�ơ�
BN������þ������������е�ÿ��֮ǰ�����һ���㣬����������ݽ��й�һ����������ÿһ��batch�����в���������������һ��batch�����ݣ��������������������ߡ����أ�����10�����ݡ���ôBN������batch�����������������ţ�������ߵľ�ֵ�ͷ��Ȼ���10���������ݽ������ţ�����ͬ�����൱�ڶ�batch��ÿ�����ݷֱ�������š�
��������BN�㰴�������ص㣬ʹ�䲻��ӦNLP������NLP�У�ÿ��batch�����ݸ�ʽ����Ϊ����batch_size��seq_len��dim��������������ţ�Ҳ�ͳ��˶�ÿ���������һ���ֵ����ݽ������ţ����߶������̶�λ�õ����ݽ������ţ�������������Ȼ���ԵĹ��ɣ���Ȼ����ϰ������һ�о�����Ϊһ����Ԫ��������Layer Normalization�����ֳ����������ˡ�
Layer Normalization
LN��BN��ͬ���ǣ�BN���н������ţ���LN�ǰ��н������š������������Ǹ�batch�������У�BN��������������ݽ������ţ���LN�Ƕ�ÿ��(���ߣ����أ����ݽ������ţ����������������ٲ�ͬ��LN�Ľ������ȫ���ˣ�����LN���н������ŷdz��ʺ�NLP�������⡣��NLP��һ��batch�У����ݰ���batch_size��seq_len��dim���������У�LN��Ե���ά�������ţ�Ҳ�������������ߴ�����������һά�ȣ������ֻ�ʵ�������ͬ������û���κ����⡣����ͼ��ʾ��
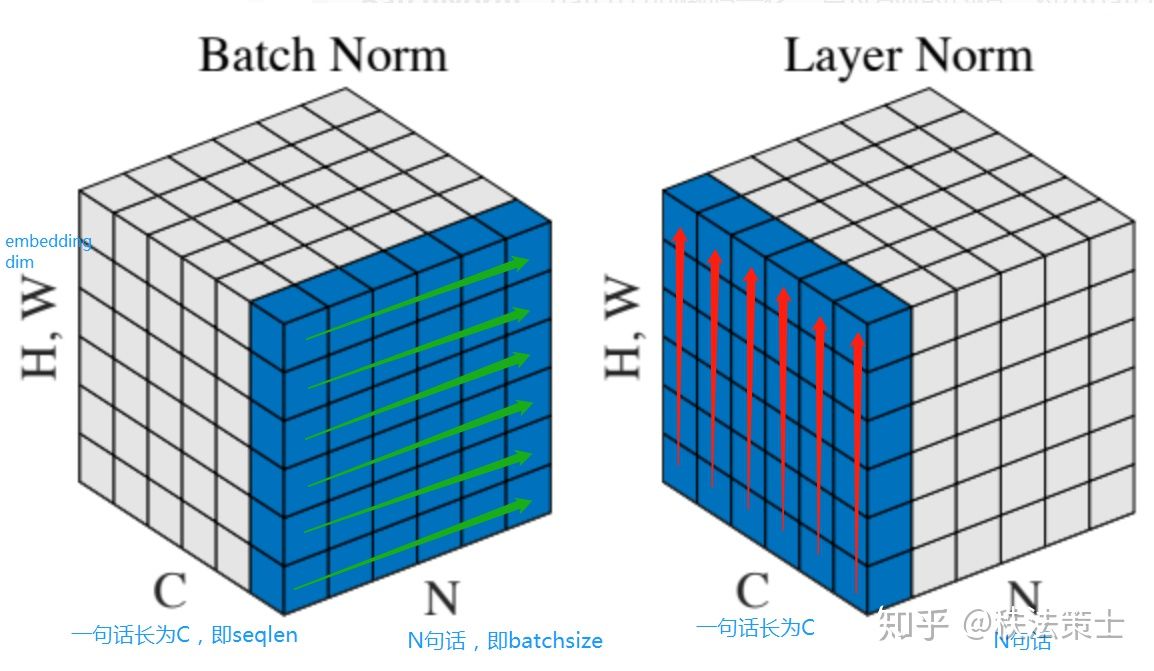
ÿ�����������һ��batch�����ݣ��ߣ�H���Ǵ�������ά�ȣ�C��ÿ�仰�ij��ȣ�N�Ǿ���������
BN��ѡȡÿ�����ӵĵ�һ��λ�õ����ݣ�ÿ��ȡһ����ɫ��ͷ�������ݽ������š�Ҳ���ǽ��������ݵĵ�һ���ֽ������š�
LN��ѡȡһ������ÿ��λ�õ����ݣ�ÿ��ȡһ����ɫ��ͷ��������ݽ������ţ�Ҳ���ǽ�һ�����ӵ�����λ�õ����ݽ������š�
���£�
������¿���һЩBN��LN��֪ʶ����������˵����Щ���⣬BN����NLP�в����Ƕ�ÿ�仰�ĵ�һ���ֽ��й�һ�������Ƕ�ÿ�仰�������������ϵ�һ��ά�ȵ�������һ����