ǰ��
normalization�����Ѿ��㷺Ӧ�������ģ���У����ҷ�������Ҫ���ã������Ƕ�normalization������һЩ�ܽᡣ
normalization
����������һ����ͨ��ԪΪ��������������
x = ( x 1 , x 2 , ? , x n ) (1) x = (x_1,x_2,\cdots,x_n) \tag{1} x=(x1?,x2?,?,xn?)(1)
ͨ�����������Ϊ��
h = f ( x ) (2) h = f(x) \tag{2} h=f(x)(2)
ʵ������£�x�ķֲ��������ܴ������϶���ͬ�ֲ��ļ��裬normalization�Ļ���˼����ǣ��ڶ�x��������֮ǰ���Ƚ���ƽ�ƺ������任������ʹx�ķֲ��淶����ij���̶�����ı��ֲ�������
h = f ( �� ? x ? �� �� + �� ) (3) h = f(\gamma \cdot \frac{x - \mu}{\sigma} + \beta) \tag{3} h=f(��?��x?��?+��)(3)
���У� �� \mu �� Ϊƽ�Ʋ�����shift parameter���� �� \sigma �� Ϊ���Ų�����scale parameter����ͨ����������������ƽ�ƺ����ű任������ʹ����x���Ͼ�ֵΪ0������Ϊ1�ı��ֲ���֮�� �� \gamma �� Ϊ�����Ų�����re-scale parameter���� �� \beta �� Ϊ��ƽ�Ʋ�����re-shift parameter�������������ձ任Ϊ��ֵΪ �� \beta �� ������Ϊ �� \gamma �� �ķֲ���
normalization����ѧϰ������ʧ���� l l l ʹ����ʽ����
�� x ^ i \hat{x}_i x^i? ��
? l ? x ^ i = ? l ? y i ? �� (4) \frac{\partial l}{\partial \hat{x}_i} = \frac{\partial l}{\partial y_i} \cdot \gamma \tag{4} ?x^i??l?=?yi??l??��(4)
�� �� 2 \sigma^2 ��2 ��
? l ? �� 2 = �� i = 1 m ? l ? x ^ i ? ( x i ? �� ) ? ? 1 2 ( �� 2 + ? ) ? 3 2 (5) \frac{\partial l}{\partial \sigma^2} = \sum_{i=1}^{m} \frac{\partial l}{\partial \hat{x}_i} \cdot (x_i - \mu) \cdot \frac{-1}{2} (\sigma^2 + \epsilon)^{-\frac{3}{2}} \tag{5} ?��2?l?=i=1��m??x^i??l??(xi??��)?2?1?(��2+?)?23?(5)
�� �� \mu �� ��
? l ? �� = �� i = 1 m ? l ? x ^ i ? ? 1 �� 2 + ? (6) \frac{\partial l}{\partial \mu} = \sum_{i=1}^{m} \frac{\partial l}{\partial \hat{x}_i} \cdot \frac{-1}{\sqrt{\sigma^2 + \epsilon}} \tag{6} ?��?l?=i=1��m??x^i??l??��2+???1?(6)
�� x i x_i xi? ��
? l ? x i = ? l ? x ^ i ? 1 �� 2 + ? + ? l ? �� 2 ? 2 ( x i ? �� ) m + ? l ? �� ? 1 m (7) \frac{\partial l}{\partial x_i} = \frac{\partial l}{\partial \hat{x}_i} \cdot \frac{1}{\sqrt{\sigma^2 + \epsilon}} + \frac{\partial l}{\partial \sigma^2} \cdot \frac{2(x_i - \mu)}{m} + \frac{\partial l}{\partial \mu} \cdot \frac{1}{m} \tag{7} ?xi??l?=?x^i??l??��2+??1?+?��2?l??m2(xi??��)?+?��?l??m1?(7)
�� �� \gamma �� ��
? l ? �� = �� i = 1 m ? l ? y i ? x ^ i (8) \frac{\partial l}{\partial \gamma} = \sum_{i=1}^{m} \frac{\partial l}{\partial y_i} \cdot \hat{x}_i \tag{8} ?��?l?=i=1��m??yi??l??x^i?(8)
�� �� \beta �� ��
? l ? �� = �� i = 1 m ? l ? y i (9) \frac{\partial l}{\partial \beta} = \sum_{i=1}^{m} \frac{\partial l}{\partial y_i} \tag{9} ?��?l?=i=1��m??yi??l?(9)
batch normalization
batch normalization������淶������Ե�����Ԫ���У���������ѵ��ʱÿ��batch���������������Ԫ x i x_i xi? �ľ�ֵ�ͷ���Ӷ�ʵ�ֶ����ݵĹ淶��������
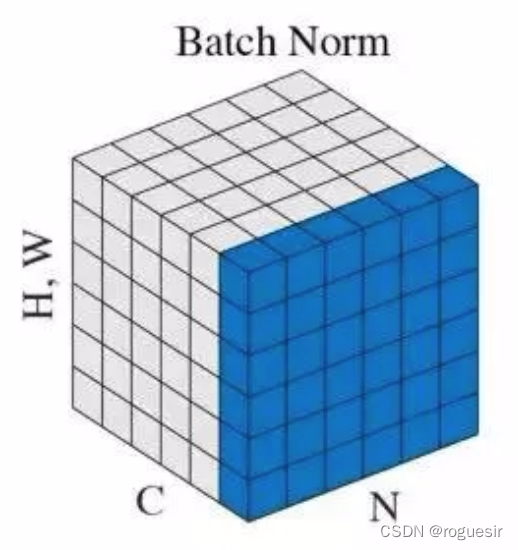
����batch�ľ�ֵ��
�� = 1 m �� i = 1 m x i (10) \mu = \frac{1}{m} \sum_{i=1}^{m}x_i \tag{10} ��=m1?i=1��m?xi?(10)
����batch�ķ��
�� 2 = 1 m �� i = 1 m ( x i ? �� ) 2 (11) \sigma^2 = \frac{1}{m}\sum_{i=1}^{m}(x_i-\mu)^2 \tag{11} ��2=m1?i=1��m?(xi??��)2(11)
���������ݽ��й淶��������ʹ��ת��Ϊ��ֵΪ0������Ϊ1�ı��ֲ���
x ^ i = x i ? �� �� 2 + ? (12) \hat{x}_i = \frac{x_i-\mu}{\sqrt{\sigma^2 + \epsilon}} \tag{12} x^i?=��2+??xi??��?(12)
�ٶ����ݽ�����ƽ�ƺ������Ų�����ʹ���ݷֲ�������һ����Χ�ڣ�
y i = �� x ^ i + �� (13) y_i = \gamma \hat{x}_i + \beta \tag{13} yi?=��x^i?+��(13)
BN�IJ�����һ��batch�µľ�ֵ�ͷ���ͳ�ƣ����Ҫ��ÿ��batch�ķֲ����������ݽ���ͬ�ֲ������batch֮������ݷֲ������С�����Կ����ǹ淶������������������С��������������ģ�͵ķ������������ģ�͵�³���ԣ������batch֮������ݷֲ�����ϴ���BN֮��ӳ��Ĺ淶���ռ�Ҳ�Dz�ͬ�ģ��ͻ�����ģ�͵�ѵ���Ѷȡ�
��ˣ���ʹ��BNʱ����Ҫע�����¼��㣺���ȣ�batch size����̫С��batch size̫С�ᵼ�¾�ֵ�ͷ���IJ��������Σ���������������shuffle��������������������ͬһ��batch�ж����ֲַ������������
��Ҫע����ǣ�������ѵ���Σ�BNÿ��ֻ��Ҫ����ÿ��batch�ľ�ֵ�ͷ����������Ԥ��Σ�����������ǵ����ģ����ģ����ѵ��ʱ���¼ÿ��batch����Ľ������ָ���ƶ�ƽ������Ϊ����Ԥ��ľ�ֵ�ͷ��
��ԭ�����и�����BN��Ч�Ľ����ǣ�BN���Է�ֹ�ڲ�Э����ת�ƣ�ͨ����Ԫ��Ȩ�����ʹ��BN���Խ����ݵķֲ�������һ��������Χ�ڡ�����MIT������֤�ý����Ǵ��ģ�BN����������ƽ������ʧ���棬ʹ��ģ��ѵ��ʱ���Ը�����������ʹ�ýϴ��ѧϰ��Ҳ��������⣨BN��ÿһ��batch�ж�������ֵ�ͷ��ʵ������������ģ�͵ļ���������Ӧ������ģ�͵�ѵ��ʱ����������BN��ʹģ�����������������·��ʵ���ϻ����ģ�͵�ѵ��ʱ�䣩��
���⣬����BN�Ƕ�ÿ����Ԫ������淶�������������Ƽ�ϵͳ��ͼ�����⣬�����кܺõ�Ч��������NLP����ʹ��BN��Ч���������룬��NLP����Ҫʹ��layer normalization��������н��ܡ�
layer normalization
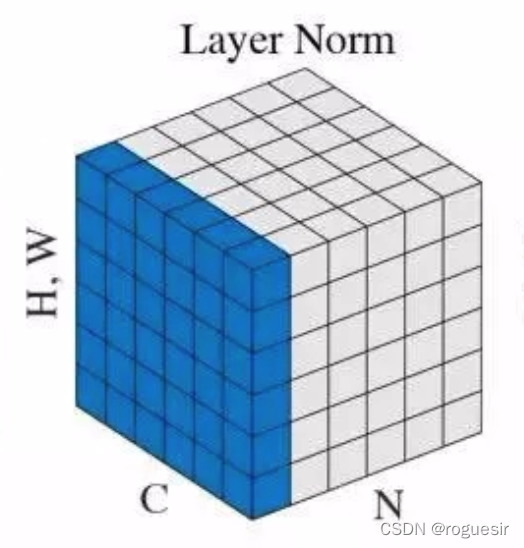
�����BN��LN�㷺ʹ����NLPģ���У���һ�ֺ���Ĺ淶��������LN�ῼ����һ������ά�ȵ����룬�������ò�ľ�ֵ�ͷ��Ȼ�����һ����������ݽ��й淶������������������£�
�� = 1 H �� i = 1 H x i �� = 1 H �� i = 1 H ( x i ? �� ) 2 (14) \mu = \frac{1}{H} \sum_{i=1}^{H} x_i \ \ \ \ \ \ \sigma = \sqrt{\frac{1}{H} \sum_{i=1}^{H} (x_i - \mu)^2} \tag{14} ��=H1?i=1��H?xi? ��=H1?i=1��H?(xi??��)2?(14)
���У� H H H Ϊ�ò�������ڵ������� �� \mu �� Ϊ�ò�ľ�ֵ�� �� \sigma �� Ϊ�ò�ķ����һ����ֵΪ��
x ^ = x ? �� �� 2 + ? (15) \hat{x} = \frac{x - \mu}{\sqrt{\sigma ^2 + \epsilon}} \tag{15} x^=��2+??x?��?(15)
������ʽ��13����Ϊ�淶�������
����Ҳ���ᵽ��BN���Ƽ�ϵͳ��ͼ�������Ч�����ܺã�����NLPģ���б��ֺܲ��ʵ�����������ݱ����IJ��졣���Ƽ�ϵͳ�У�ÿһά������ʾij������ֵ��������ֵ�ĸ߽�ӳ�䣻��ͼ���ϣ�ÿһά������ʾij�����ص�������ص�ĸ߽�ӳ�䣬�����߶���ʵ�ʴ��ڵģ�����������������ͬ����ơ�����NLP����ÿһά��һ�����ʵ�ӳ�䣬���ӳ������Ϊ����ģ�����������䳤�̲�һ����������������Ҳ��һ����ʱ��ȥ����Ŀ���ÿ�����ʵ���Ϣ��ȡ���������Ŀ���ÿ�����ӵ�������Ϣ���ٸ������ӣ������� ���� �� �á��͡��� �� д ���͡����������ӣ��������BN��������Ӧ���ǡ����졻�͡��ҡ����б���������Ȼ��������
���⣬LN������������һ����Ԫ�����룬����Ҫ����batchά�ȣ����Ҳ�Ͳ���Ҫ�洢��ֵ�ͷ����ʡ�˶���Ĵ洢�ռ䡣
instance normalization
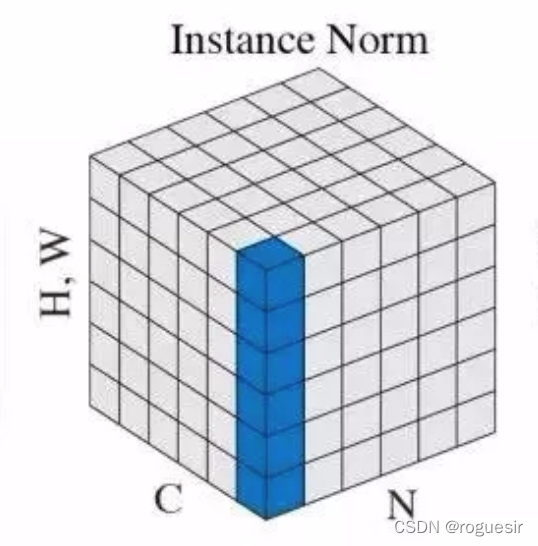
Instance Norm�ļ��������£�
�� t i = 1 H W �� l = 1 W �� m = 1 H x t i l m �� t i 2 = 1 H W �� l = 1 W �� m = 1 H ( x t i l m ? �� t i ) 2 (16) \mu_{ti} = \frac{1}{HW} \sum_{l=1}^{W} \sum_{m=1}^{H} x_{tilm} \ \ \ \ \ \ \sigma_{ti}^2 = \frac{1}{HW} \sum_{l=1}^{W} \sum_{m=1}^{H} (x_{tilm} - \mu_{ti})^2 \tag{16} ��ti?=HW1?l=1��W?m=1��H?xtilm? ��ti2?=HW1?l=1��W?m=1��H?(xtilm??��ti?)2(16)
Instance Norm�淶����
x ^ t i l m = x t i l m ? �� t i �� t i 2 + ? (17) \hat{x}_{tilm} = \frac{x_{tilm} - \mu_{ti}}{\sqrt{\sigma_{ti}^2 + \epsilon}} \tag{17} x^tilm?=��ti2?+??xtilm??��ti??(17)
������ʽ��13����Ϊ�淶�������
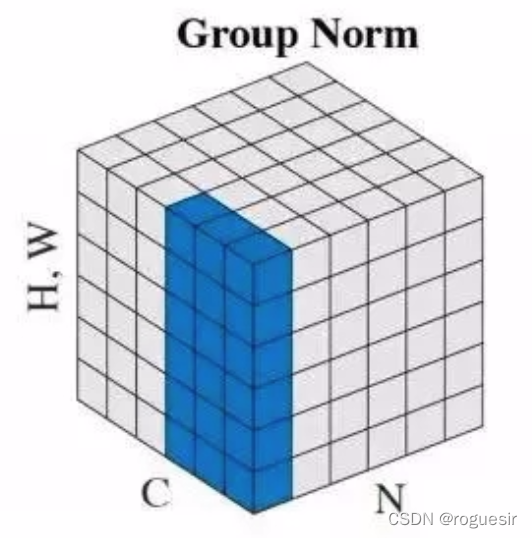
group normalization
group normalization����layer normalization��instance normalization֮�䣬����ʽ��Ҫ���峬����G��Ϊgroup������
weighted normalization
�ص���Ԫ����Ļ������ϣ�
f ( x ) = W ? x + b (18) f(x)=W \cdot x + b \tag{18} f(x)=W?x+b(18)
������ܵĸ��ֱ�����ʵ���϶��Ƕ����� x x x ���б任���������е�WN�����Ƕ� W W W ���й淶�������巽���ǣ���Ȩ������ W W W �ֽ�Ϊ�������� v ^ \hat{v} v^ �� ����ģ g g g ��
f w ( x ) = W N ( W x ) = g ? v ^ ? x = g ? v �O �O v �O �O ? x = v ? g ? x �O �O v �O �O = f v ( g ? x �O �O v �O �O ) (19) \begin{aligned} f_w(x) &= WN(Wx)\\ &= g \cdot \hat{v} \cdot x \\ &= g \cdot \frac{v}{||v||} \cdot x \\ &= v \cdot g \cdot \frac{x}{||v||} \\ &= f_v (g \cdot \frac{x}{||v||}) \end{aligned} \tag{19} fw?(x)?=WN(Wx)=g?v^?x=g?�O�Ov�O�Ov??x=v?g?�O�Ov�O�Ox?=fv?(g?�O�Ov�O�Ox?)?(19)
�Ա�ʽ��3����֪��ֻ��� �� = 0 , �� = �O �O v �O �O , b = 0 \mu = 0 \ , \sigma = ||v|| \ , b=0 ��=0 ,��=�O�Ov�O�O ,b=0 ���ɡ�
cosin normalization
���ǻص���Ԫ�Ļ����任��ʽ��18���ϣ� W W W �� x x x ����������������Ϊ��Ԫ��������������ģ�������Ҳ�Ǽ����������������ƶȣ�����ʹ���������ƶ�����������������һ���ô����������ƶ����н�ġ�
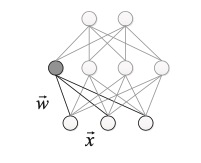
f w ( x ) = c o s �� = w ? x �O �O w �O �O ? �O �O x �O �O (20) f_w(x) = cos \theta = \frac{w \cdot x}{||w|| \cdot ||x||} \tag{20} fw?(x)=cos��=�O�Ow�O�O?�O�Ox�O�Ow?x?(20)
n e t n o r m = ( w ? �� w ) ? ( x ? �� x ) �O w ? �� w �O �O x ? �� x �O (21) net_{norm} = \frac{(w - \mu_w) \cdot (x - \mu_x)}{|w - \mu_w| |x - \mu_x |} \tag{21} netnorm?=�Ow?��w?�O�Ox?��x?�O(w?��w?)?(x?��x?)?(21)
���У� �� w \mu_w ��w? Ϊ���� w w w �ľ�ֵ�� �� x \mu_x ��x? Ϊ���� x x x �ľ�ֵ
����
�O w ? �� w �O = �� i ( w i ? �� w ) 2 (22) |w - \mu_w| = \sqrt{\sum_i (w_i - \mu_w)^2} \tag{22} �Ow?��w?�O=i��?(wi??��w?)2?(22) �O x ? �� x �O = �� i ( x i ? �� x ) 2 (23) |x - \mu_x| = \sqrt{\sum_i (x_i - \mu_x)^2} \tag{23} �Ox?��x?�O=i��?(xi??��x?)2?(23) �� w = 1 n �� i ( w i ? �� w ) 2 (24) \sigma_w = \sqrt{\frac{1}{n} \sum_i (w_i - \mu_w)^2} \tag{24} ��w?=n1?i��?(wi??��w?)2?(24) �� x = 1 n �� i ( x i ? �� x ) 2 (25) \sigma_x = \sqrt{\frac{1}{n} \sum_i (x_i - \mu_x)^2} \tag{25} ��x?=n1?i��?(xi??��x?)2?(25)
���ǣ�cosine normalizationת��Ϊ��
n e t n o r m = ( w ? �� w ) ? ( x ? �� x ) n �� w �� x (26) net_{norm} = \frac{(w - \mu_w) \cdot (x - \mu_x)}{ n \sigma_w \sigma_x} \tag{26} netnorm?=n��w?��x?(w?��w?)?(x?��x?)?(26)