Transformer和Bert
-
- 前沿
- Transformer
-
- Transformer 模型结构图
- Transformer的编码器解码器
- 输入层
- 位置向量
- Bert (Bidirectional Encoder Representations from Transformers)
-
- Bert总体框架
- Bert输入
- 任务定制model
- 参考文章
前沿
??谷歌在2017年发表了一篇论文名字教Attention Is All You Need,提出了一个只基于attention的结构来处理序列模型相关的问题,比如机器翻译。传统的神经机器翻译大都是利用RNN或者CNN来作为encoder-decoder的模型基础,而谷歌最新的只基于Attention的Transformer模型摒弃了固有的定式,并没有用任何CNN或者RNN的结构。该模型可以高度并行地工作,所以在提升翻译性能的同时训练速度也特别快。
Transformer
Transformer 模型结构图
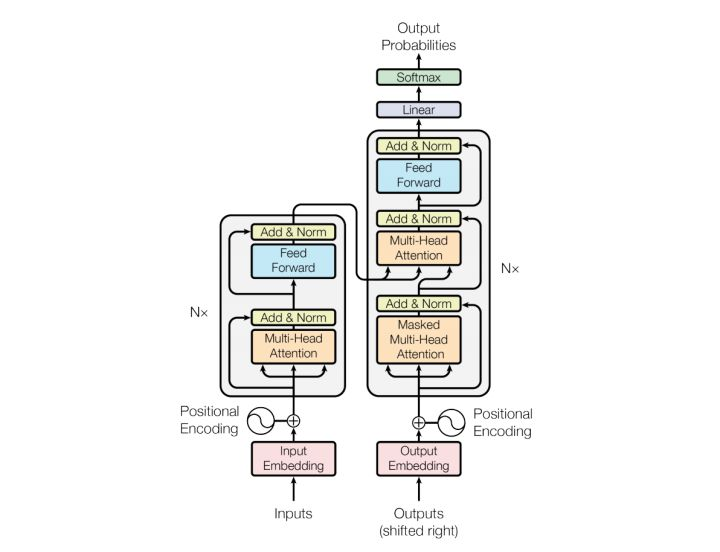
Transformer的编码器解码器
模型分为编码器和解码器两个部分。
编码器由6个相同的层堆叠在一起,每一层又有两个支层。第一个支层是一个多头的自注意机制,第二个支层是一个简单的全连接前馈网络。在两个支层外面都添加了一个residual的连接,然后进行了layer nomalization的操作。模型所有的支层以及embedding层的输出维度都是dmodel。解码器也是堆叠了六个相同的层。不过每层除了编码器中那两个支层,解码器还加入了第三个支层,如图中所示同样也用了residual以及layer normalization。
输入层
??编码器和解码器的输入就是利用学习好的embeddings将tokens(一般应该是词或者字符)转化为d维向量。对解码器来说,利用线性变换以及softmax函数将解码的输出转化为一个预测下一个token的概率。
位置向量
??由于模型没有任何循环或者卷积,为了使用序列的顺序信息,需要将tokens的相对以及绝对位置信息注入到模型中去。论文在输入embeddings的基础上加了一个“位置编码”。位置编码和embeddings由同样的维度都是dmodel所以两者可以直接相加。有很多位置编码的选择,既有学习到的也有固定不变的。
Bert (Bidirectional Encoder Representations from Transformers)
Bert总体框架
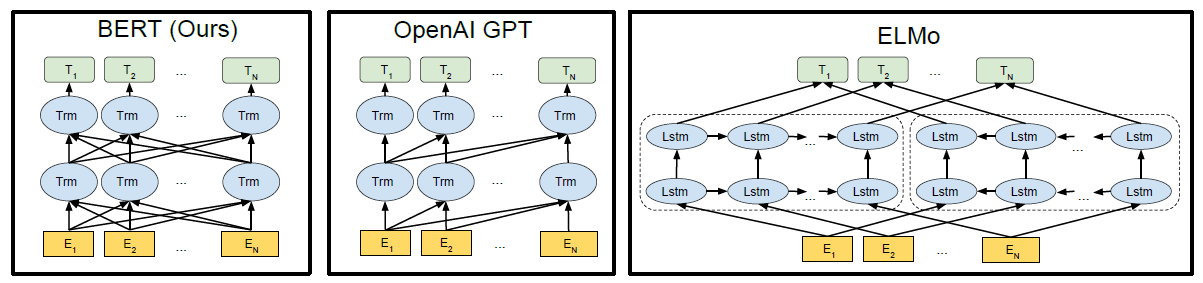
??上图显示了三种不同预训练模型架构的差异。 BERT使用了双向Transformer。 OpenAI GPT使用从左到右的Transformer。 ELMo使用经过独立训练的从左到右和从右到左LSTM的串联来生成下游任务的功能。 在三个中,只有BERT表示在所有层中共同依赖于左右上下文。
Bert输入
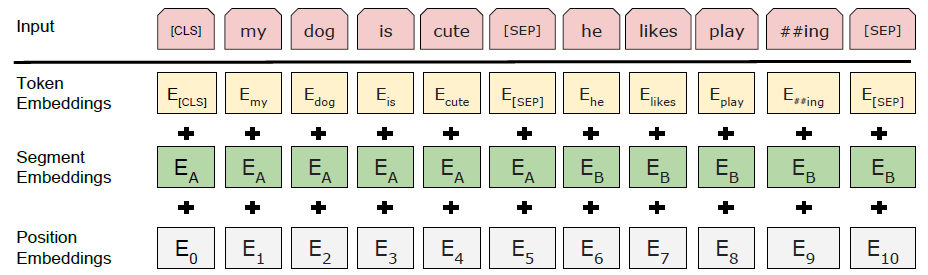
??针对不同的任务,模型能够明确的表达一个句子,或者句子对(比如[问题,答案])。对于每一个token, 它的表征由其对应的token embedding, 段表征(segment embedding)和位置表征(position embedding)相加产生。
任务定制model
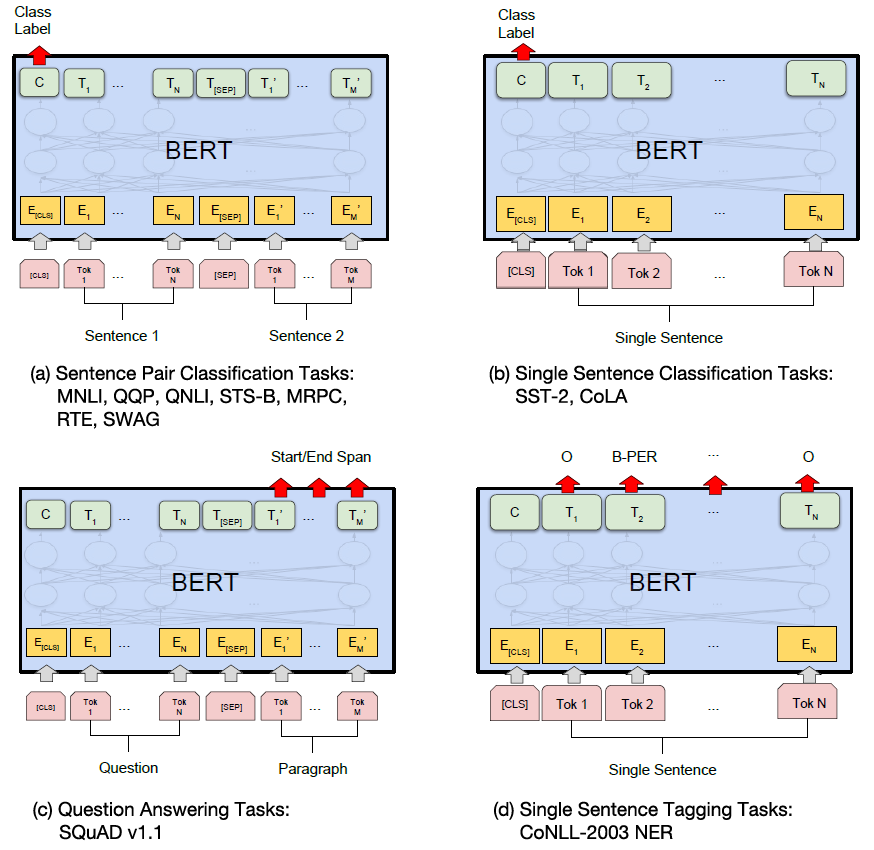
??我们的任务特定模型是通过将BERT与一个额外的输出层相结合而形成的,因此需要从头开始学习最少数量的参数。 在这些任务中,(a)和(b)是序列级任务,而(c)和(d)是token级任务。 在图中, E E E表示输入嵌入, T i T_i Ti?表示标记 i i i的上下文表示, [ C L S ] [CLS] [CLS]是分类输出的特殊符号, [ S E P ] [SEP] [SEP]是分隔非连续标记序列的特殊符号。
参考文章
[1] https://www.cnblogs.com/huangyc/p/9813907.html
[2] https://jalammar.github.io/illustrated-transformer/
[3] https://blog.csdn.net/yujianmin1990/article/details/85221271
[4] https://blog.csdn.net/triplemeng/article/details/83053419
[5] https://arxiv.org/pdf/1810.04805.pdf