简介
蛮力匹配法(brute force string matching)是字符串匹配算法中最基本的一种,也是最简单的一种。它确实有自己的优点,比如它并不需要对文本串(text)或模式串(pattern)进行预处理。然而它最大的问题就是运行速度太慢,所以在很多场合下蛮力字符串匹配算法并不是那么有用。我们需要一些更快的方法来完成字符串的匹配工作,然而在此之前,我们还是回过头来再看一遍蛮力匹配法,以便更好地理解其他子串匹配算法。
如下图所示,在蛮力字符串匹配里,我们将文本中的每一个字符和模式串的第一个字符进行比对。一旦我们找到了一个匹配,我们就将文本中下一个字符取出来和模式串的第二个字符进行比较。
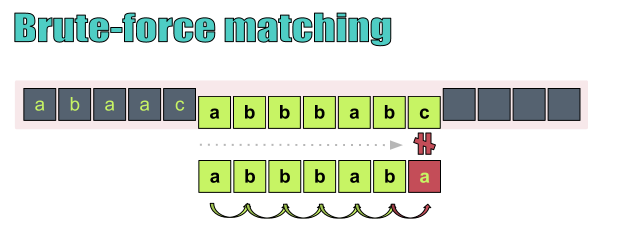
蛮力字符串匹配之所以慢,是因为它需要比对文本和模式串的每个字符
该算法运行速度慢的主要原因有二:
一方面,我们需要对文本中的每个字符都进行比对;
另一方面,即使我们发现模式串首字符和文本中的某个字符相匹配,我们仍然需要对模式串中剩下的所有符号(字符)挨个进行比对,才知道它们是不是出现在接下来的文本中。那么,是否有别的方法可以用来判断文本是否包含模式串呢?
答案是肯定的,确实存在一种更快的方法。为了避免挨个字符对文本和模式串进行比较,我们可以尝试一次性判断两者是否相等。因此,我们需要一个好的哈希函数(hash function)。通过哈希函数,我们可以算出模式串的哈希值,然后将它和文本中的子串的哈希值进行比较。这里有一个问题,我们必须保证该哈希函数能够对一个较长的字符串返回较短的哈希值。然而,我们又不能指望较长的模式串能得到较短的哈希值。但除此之外,这个新方法在速度上应该能比暴力法有显著提升。
这种更快的方法就是Rabin-Karp算法。
概述
Michael O. Rabin和Richard M. Karp在1987年提出一个想法,即可以对模式串进行哈希运算并将其哈希值与文本中子串的哈希值进行比对。总的来说这一想法非常浅显,唯一的问题在于我们需要找到一个哈希函数 ,它需要能够对不同的字符串返回不同的哈希值。例如,该哈希函数可能会对每个字符的ASCII码进行算,但同时我们也需要仔细考虑对多语种文本的支持
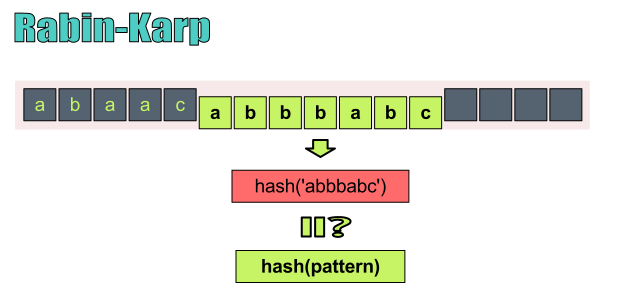
Rabin-Karp算法对模式串和文本中的子串分别进行哈希运算,以便对它们进行快速比对
哈希算法可以有很多种不同的形式,它可能包含ASCII码字符以便对数字进行转化,但也可能是别的形式。我们唯一需要的就是将一个字符串(模式串)转化成为能够快速进行比较的哈希值。以”hello world”为例,假设它的哈希值hash(‘hello world’)=12345。那么如果hash(‘he’)=1,那么我们就可以说模式串”he”包含在文本”hello world”中。由此,我们可以每次从文本中取出长度为m(m为模式串的长度)的子串,然后将该子串进行哈希,并将其哈希值与模式串的哈希值进行比较。
*实现
我们已经看了一些关于Rabin-Karp算法的图解,现在让我们来关注一下它的实现。以下的PHP代码展示了通过一个简单的哈希表来将字符转化成整数的实例。它非常简单,仅仅只是为了用来阐明Rabin-Karp算法的基本原理。
function hash_string($str, $len)
{$hash = '';$hash_table = array('h' => 1,'e' => 2,'l' => 3,'o' => 4,'w' => 5,'r' => 6,'d' => 7,);for ($i = 0; $i < $len; $i++) {$hash .= $hash_table[$str{$i}];}return (int)$hash;
}function rabin_karp($text, $pattern)
{$n = strlen($text);$m = strlen($pattern);$text_hash = hash_string(substr($text, 0, $m), $m);$pattern_hash = hash_string($pattern, $m);for ($i = 0; $i < $n-$m+1; $i++) {if ($text_hash == $pattern_hash) {return $i;}$text_hash = hash_string(substr($text, $i, $m), $m);}return -1;
}// 2
echo rabin_karp('hello world', 'ello');多模式匹配
Rabin-Karp算法非常适用于多模式匹配(multiple pattern match)。事实上,它天生就是能够支持此类的操作,这也是它相对于其他字符串查找算法的优势。
算法复杂度
Rabin-Karp算法的复杂度是O(nm),其中n和m分别是文本和模式串的长度。那么它到底比暴力匹配好在哪儿呢?暴力匹配法的算法复杂度同样是O(nm),这样看起来Rabin-Karp算法在性能上并没有多大提升。然后在实际使用过程中,Rabin-Karp的复杂度通常被认为是O(n+m)。这就使得它比暴力匹配法要快一些,具体见下图。
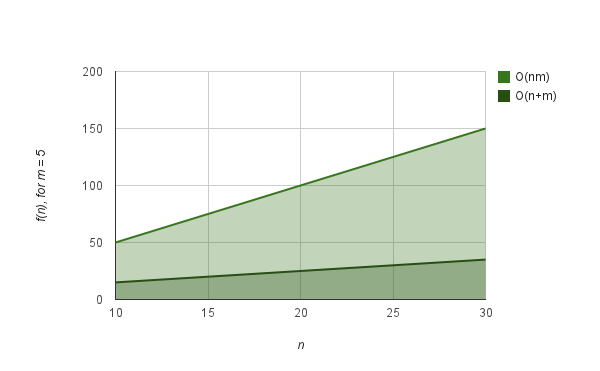
Rabin-Karp的复杂度理论上是O(nm),但在实际使用中通常是O(n+m)
需要注意的是Rabin-Karp算法需要O(m)的预处理时间。
译者注
事实上,由于哈希函数无法保证对不同的字符串产生不同的哈希值,有哈希冲突的现象存在,所以即使模式串的哈希值和文本子串的哈希值相等,也需要对这两个长度为m的字符串进行额外的比对(当然,如果不相等也就不用比对了,其实大部分的时间省在这上面),这时比对的开销是O(m)。最坏情况下,文本中所有长度为m的子串(一共n-m+1个)都和模式串匹配,所以算法复杂度为O((n-m+1)m)。然而实际情况下,需要进一步比对的子串个数总是有限的(假设为c个),那么算法的期望匹配时间就变成O((n-m+1)+cm)=O(n+m)。
应用
我们已经看到Rabin-Karp算法比暴力匹配法其实也快不了太多,那它的应用场景到底是哪里?
要回答这个问题,需要先了解Rabin-Karp算法被称道和诟病的原因。然后根据自己的具体应用需要来做判断。
Rabin-Karp算法被称道的三个原因:
(1)它可以用来检测抄袭,因为它能够处理多模式匹配;
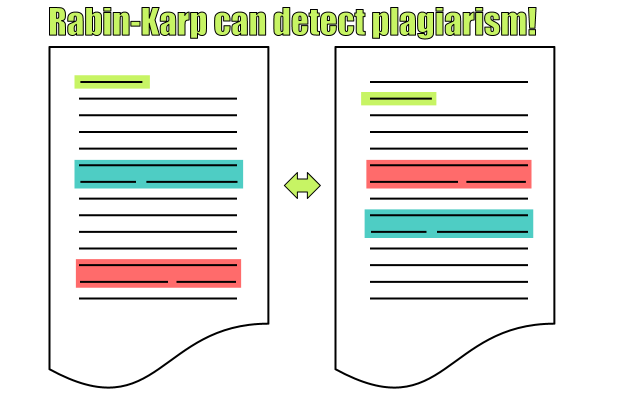
Rabin-Karp算法能够有效地检测抄袭
(2)虽然在理论上并不比暴力匹配法更优,但在实际应用中它的复杂度仅为O(n+m);
(3)如果能够选择一个好的哈希函数,它的效率将会很高,而且也易于实现。
Rabin-Karp算法被诟病的两个原因:
(1)有许多字符串匹配算法的复杂度小于O(n+m);
(2)有时候它和暴力匹配法一样慢,并且它需要额外空间。
结语
Rabin-Karp算法之所以出众最大的原因就是它可以对多模式进行匹配。这一特性使得它在检测抄袭方面(尤其是大篇幅文字)非常好用。
本文原文地址:https://blog.csdn.net/SunnyYoona/article/details/43536165