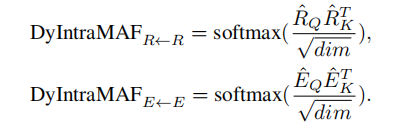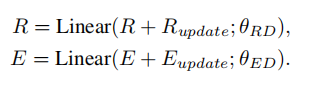论文链接:https://arxiv.org/abs/1812.05252
这篇论文提出了一种新的多模态特征融合方法——模式内与模式间注意流的动态融合的视觉问题回答,它可以在视觉和语言模式之间传递动态信息,它能够很好地捕捉语言和视觉领域之间的高层交互,从而显着地提高了视觉问题回答的性能。
近年来,视觉问答(VQA)的性能得到了很大的提高,原因主要有三点:
- 提取到了很好的视觉和语言特征表示;VGG,ResNet,FishNet以及最近的bottom-up & top-down的特征显著提高了VQA的性能。
- 不同类型的注意机制可以自适应地选择重要的特征,从而帮助深度学习获得更好的识别精度。
- 更好的多模态融合方法,如双线性融合、MCB和MUTAN。
将得到的区域视觉特征表示为R(共有个区域),第i个区域特征表示为(2048维)
得到问题特征E,第j个词的特征表示为,所有的问题都被填充或者截断到相同的长度14。
获得的视觉对象区域特征R和问题特征E可以表示为:

如下图所示,模式间注意流(InterMAF)模块首先学会捕捉每个视觉区域和单词特征之间的重要性。

根据学习的重要性权重和聚集特征在两种模态之间传递信息流以更新每个单词特征和图像区域特征。给定视觉区域和单词特征,我们首先计算每对视觉区域和单词之间的关联权重。每个可视区域和单词特征首先被转换为查询Q、键K和值特征V。
将变换后的区域特征表示为、
和
变换公式为:

其中Linear表示带参数的全连接层,
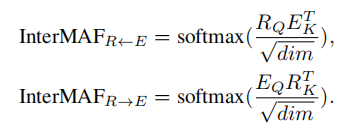
的每一行代表一个视觉区域和所有单词嵌入之间的注意权重。从所有单词嵌入到这一图像区域特征的信息可以被聚合为单词值特征EV的加权求和。更新过程如下所示:
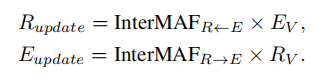
获取更新后的视觉和文字特征,然后将新的特征分别和原始特征相连接,
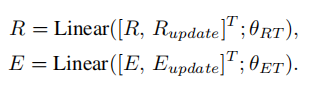
完成模态间操作之后,作者认为,模态内的关系是对跨模态关系的补充,应该考虑到这一点来提高VQA的准确性。朴素的IntraMAF模块只利用模态内的信息来估计区域对区域的重要性和逐字逐句的重要性。但是一些关系很重要,却只能根据来自其他模态的信息来识别。例如,即使对于相同的输入图像,不同的视觉区域对之间的关系也应该根据不同的问题进行不同的加权。
因此,我们提出了一个动态的模态内注意流模块,用于根据来自其他模态的信息来估计非模态关系重要性。如下图:

该图只显示了以问题为条件的视觉模态内注意流
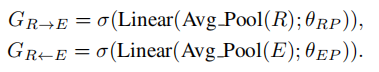
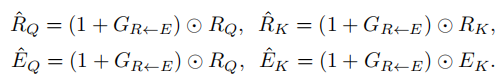
根据另一种模态调整过的特征,通过门控查询和关键特征获得不同的内部模态关系的关键特征。