本文提出了一种统一的视觉语言训练(VLP)模型..该模型的统一体现在两点:
(1)可以对视觉语言生成(例如,图像标题)或理解(例如,视觉问题回答)任务进行微调
(2)它使用共享的多层transformer网络进行编码和解码,这不同于许多现有的方法,现有的编码器和解码器是使用单独的模型实现的。
利用双向和序列(seq2seq)mask视觉语言预测两个任务的无监督学习目标,对大量的图像-文本对进行了统一VLP模型的预训练预测。两项任务的区别仅在于预测所基于的上下文。这是通过为共享的transformer网络使用特定的自注意掩码来控制的。
这些模型使用两阶段训练方案,第一步,称为预训练阶段,学习上下文化的视觉语言表示;第二步,对预训练模型进行了微调以适应下游任务(即VQA,图像描述等)。


VLP将编码器和解码器合并,并学习更通用的上下文视觉语言表示形式,该形式可更轻松地进行微调
Vision-Language Pre-training
使用现有的目标检测器从图像中提取固定数量的对象区域,表示为![]() ,对应的特征向量
,对应的特征向量![]() ,区域物体的标签为
,区域物体的标签为![]() 区域位置信息
区域位置信息![]()
![]() ,以及词向量
,以及词向量![]() ,S 中的单词表示为单热矢量,这些矢量进一步编码为具有嵌入大小 e 的单词嵌入。
,S 中的单词表示为单热矢量,这些矢量进一步编码为具有嵌入大小 e 的单词嵌入。
其中 d 是嵌入大小,l 指示对象探测器的对象类数,o = 5 包含区域边界框的左上角和右下角坐标的四个值(归化为 0 和 1 之间),其相对区域的一个值(即边界框区域与图像区域的比率,也介于 0 和 1 之间)
我们的视觉语言变压器网络,将transformer网络的编码器和解码器合并为一个模型,模型输入包括类别识别区域嵌入,单词嵌入和三个特殊标记。区域嵌入定义为
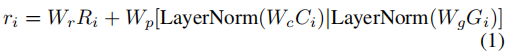
其中[・| ・]表示要素维的级联,LayerNorm表示图层归一化,第二项模拟BERT中的位置嵌入,但是添加了额外的区域类别信息,并且W r,W p,W c,Wg是嵌入权重(偏置项和非线性项被省略)。请注意,在这里,我们对r进行了重载,以表示类感知区域嵌入。
我们定义了三个特殊标记[CLS],[SEP],[STOP],其中[CLS]指示视觉输入的开始,[SEP]标记视觉输入和句子输入之间的边界,[STOP]确定句子的结尾。然后,在模型输出中,将最后一个Transformer块的隐藏状态投影到单词似然性,在该似然率中以分类问题的形式预测被屏蔽的标记。通过这种重构,模型可以学习上下文中的依赖关系并形成语言模型。
如图2(右)所示,两个目标之间的唯一区别在于self-attention mask,用于双向目标的掩码允许在视觉模态和语言模态之间无限制地传递消息,而在seq2seq中,将来要预测的单词不能参与该单词,即满足自回归属性。
更正式地说,我们将第一个Transformer块的输入定义为:![]()
![]() ,然后在不同级别的transformer上编码
,然后在不同级别的transformer上编码
![]()

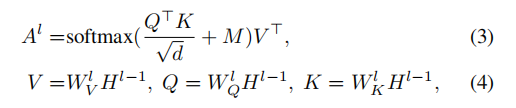
在预训练期间,我们在两个目标之间交替进行批处理,并且seq2seq和双向的比例分别由超参数λ和1-λ确定。
微调部分
我们将VQA框架作为一个多标签分类问题..在本工作中,我们将重点放在开放域VQA上,其中最常见的答案被选择为答案词汇,并用作类标签。在微调过程中,在[CLS]和[SEP]的最后隐藏状态的元素级乘积之上学习多层感(Linear+ReLU+Linear+Sigmoi),利用交叉熵损失来优化软答案标签的模型输出分数。