��ע����Ȼ��ʱ����ƪ���µ�ʱ��о��ܲ��������ǻ���д��ǰ�棬��Ҫ�˽���ڻ���ѧϰ�����ļ����߶ȣ�������ֱ�ӿ���־����ʦ��������ĵ�2�£�ģ��������ѡ��д������ĺܺã���
���µ�һ��������ת���ԣ�����ѧϰ�㷨�е�ȷ��(Precision)���ٻ���(Recall)��Fֵ(F-Measure)����ôһ����
ժҪ��
�����ھ���ѧϰ���Ƽ�ϵͳ�е�����ָ�ꡪȷ��(Precision)���ٻ���(Recall)��Fֵ(F-Measure)��顣
���ԣ�
�ڻ���ѧϰ�������ھ��Ƽ�ϵͳ��ɽ�ģ֮����Ҫ��ģ�͵�Ч�������ۡ�
ҵ��Ŀǰ�������õ�����ָ����ȷ��(Precision)���ٻ���(Recall)��Fֵ(F-Measure)�ȣ���ͼ�Dz�ͬ����ѧϰ�㷨������ָ�ꡣ���Ľ�������ijЩָ������Ҫ���ܡ�
������Զ�Ԫ��������
������Զ�Ԫ����������
������Զ�Ԫ������������
�Է���ķ�����������ָ�꽫���Ժ������н��ܡ�
�ڽ���ָ��ǰ�������˽⡰��������
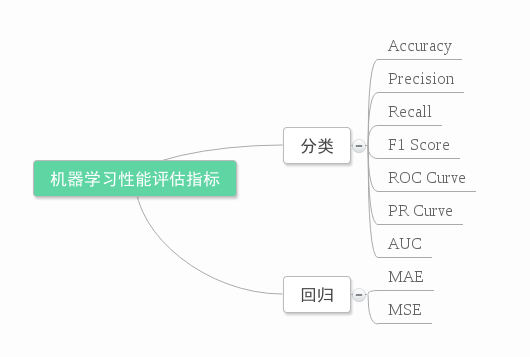
��������
True Positive(������TP)��������Ԥ��Ϊ������
True Negative(�渺��TN)��������Ԥ��Ϊ������
False Positive(������FP)��������Ԥ��Ϊ�������� (Type I error)
False Negative(�ٸ���FN)��������Ԥ��Ϊ��������©�� (Type II error)

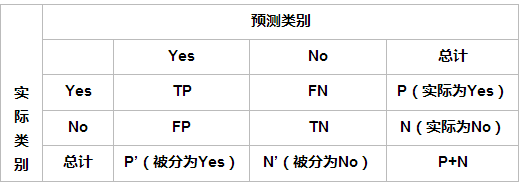
1��ȷ�ʣ�Accuracy��
ȷ��(accuracy)���㹫ʽΪ��
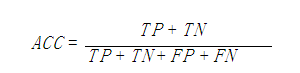
ע��ȷ�����������������ָ�꣬���Һ��������⣬���DZ��ֶԵ��������������е���������ͨ����˵����ȷ��Խ�ߣ�������Խ�á�
ȷ��ȷʵ��һ���ܺú�ֱ�۵�����ָ�꣬������ʱ��ȷ�ʸ߲����ܴ���һ���㷨�ͺá�����ij������ij������Ԥ�⣬����������һ�ѵ�������Ϊ�����������ԣ����ֻ��������0������������1����������һ������˼���ķ���������ÿһ�����������������Ϊ0������ô���Ϳ��ܴﵽ99%��ȷ�ʣ�����ĵ�������ʱ��������������������������������ʧ�Ǿ�ġ�Ϊʲô99%��ȷ�ʵķ�����ȴ����������Ҫ�ģ���Ϊ�������ݷֲ������⣬���1������̫�٣���ȫ�������1��Ȼ���Դﵽ�ܸߵ�ȷ��ȴ���������ǹ�ע�Ķ������پٸ�����˵���¡�������������ƽ�������£�ȷ���������ָ���кܴ��ȱ�ݡ������ڻ�����������棬����������Ǻ��ٵģ�һ��ֻ��ǧ��֮���������acc����ʹȫ��Ԥ��ɸ��ࣨ�������accҲ�� 99% ���ϣ�û�����塣��ˣ�������ȷ��������һ���㷨ģ����ԶԶ������ѧȫ��ġ�
2�������ʣ�Error rate��
����������ȷ���෴�����������������ֵı����� =
����ijһ��ʵ����˵���ֶ���ִ��ǻ����¼�������accuracy =1 - error rate��
3�������ȣ�sensitive��
sensitive = TP/P����ʾ�������������б��ֶԵı����������˷�������������ʶ��������
4����Ч�ȣ�sensitive��
specificity = TN/N����ʾ�������и����б��ֶԵı����������˷������Ը�����ʶ��������
5����ȷ�ʡ����ȣ�Precision��
��ȷ��(precision)����Ϊ��
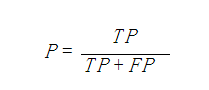
��ʾ����Ϊ������ʾ����ʵ��Ϊ�����ı�����
6���ٻ��ʣ�recall��
�ٻ����Ǹ�����Ķ����������ж����������Ϊ������recall=TP/(TP+FN)=TP/P=sensitive�����Կ����ٻ�������������һ���ġ�
7���ۺ�����ָ�꣨F-Measure��
P��Rָ����ʱ�����ֵ�ì�ܵ��������������Ҫ�ۺϿ������ǣ�����ķ�������F-Measure���ֳ�ΪF-Score����
F-Measure��Precision��Recall��Ȩ����ƽ����
��������=1ʱ�����������F1��Ҳ��
��֪F1�ۺ���P��R�Ľ������F1�ϸ�ʱ����˵�����鷽���Ƚ���Ч��
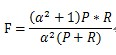
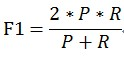
8����������ָ��
�����ٶȣ�������ѵ����Ԥ����Ҫ��ʱ�䣻
³���ԣ�����ȱʧֵ���쳣ֵ��������
����չ�ԣ����������ݼ���������
�ɽ����ԣ���������Ԥ����Ŀ������ԣ�������������Ĺ�����Ǻ���������ģ����������һ�Ѳ����Ͳ������⣬����ֻ�ð�������һ���ں��ӡ�
��������һ��ROC��PR���ߣ���������Ϊ�Լ��ܽᣩ��
1��ROC���ߣ�
ROC��Receiver Operating Characteristic���������Լ����ʣ�FP_rate���������ʣ�TP_rate��Ϊ������ߣ�ROC���������������ǽ���AUC������ͼ��ʾ��
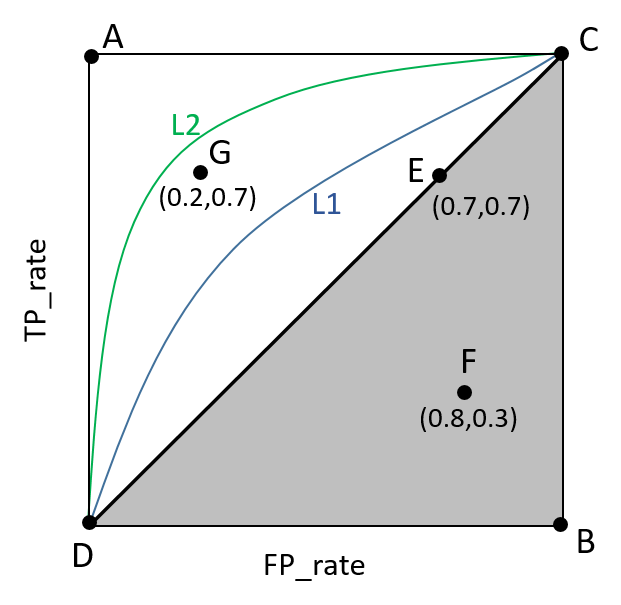
ͼƬ����Paper��Learning from eImbalanced Data����
����: 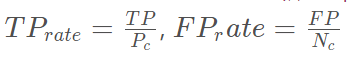
��1��������FP_rate��Χ�ɵ����������AUC��Խ��˵������Խ������ͼ��L2���߶�Ӧ��������������L1��Ӧ�����ܡ���������Խ����A�㣨���Ϸ�������Խ�ã�����Խ����B�㣨���·�����������Խ�
��2��A������������performance�㣬B�����������㡣
��3��λ��C-D���ϵĵ�˵���㷨���ܺ�random�²���һ���ĨC��C��D��E�㡣λ��C-D֮�ϣ�������λ�ڰ�ɫ���������ڣ�˵���㷨������������²�C��G�㣬λ��C-D֮�£�������λ�ڻ�ɫ���������ڣ�˵���㷨���ܲ�������²�C��F�㡣
��4����ȻROC������Ƚ���Precision��Recall�Ⱥ���ָ����Ӻ������������ڸ߲�ƽ�����������µĵı�����Ȼ�������룬���ܹ��ܺõ�չʾʵ�������
2��PR���ߣ�
����PR��Precision-Recall�����ߡ�
�ٸ����ӣ���������Paper��Learning from eImbalanced Data����
����N_c>>P_c����Negative������ԶԶ����Positive������������FP�ܴ��кܶ�N��sample��Ԥ��ΪP����ΪFPrate=FPNcFP_{rate}=\frac{FP}{N_c}FPrate?=Nc?FP?�����FP_rate��ֵ��Ȼ��С���������ROC��������ж������ܺܺã�����ʵ���������ܲ����ã��������������PR����ΪPrecision�ۺϿ�����TP��FP��ֵ������ڼ��Ȳ�ƽ��������£�Positive���������٣���PR���߿��ܱ�ROC���߸�ʵ�á�