在讲个组件之前现将一下集群
什么是集群
将多台同构或异构的计算机连接起来协同完成特定的任务就构成了集群系统。各个Linux厂商也推出了能够显著地提高基于TCP/IP协议的多种网络服务的服务质量的高可用性集群系统,通过将物理上分离的多个集群连接在一起使使多个同构或异构的计算机能够通过局域网或广域网共享计算资源,并能够为用户提供对资源的透明访问。
集群分类
1、 LB:load balancing 负载均衡(针对大容量的请求)
负载均衡群集为企业需求提供了更实用的系统。该系统使负载可以在计算机群集中尽可能平均地分摊处理。该负载可能是需要均衡的应用程序处理负载或网络流量负载。这样的系统非常适合于运行同一组应用程序的大量用户。每个节点都可以处理一部分负载,并且可以在节点之间动态分配负载,以实现平衡。对于网络流量也如此。通常,网络服务器应用程序接受了太多入网流量,以致无法迅速处理,这就需要将流量发送给在其它节点上运行的网络服务器应用。还可以根据每个节点上不同的可用资源或网络的特殊环境来进行优化。
2、 HA:high Availability 高可用 (7X24小时在线)
高可用性群集的出现是为了使群集的整体服务尽可能可用,以便考虑计算硬件和软件的易错性。如果高可用性群集中的主节点发生了故障,那么这段时间内将由次节点代替它。次节点通常是主节点的镜像,所以当它代替主节点时,它可以完全接管其身份,并且因此使系统环境对于用户是一致的。能够实现服务器实时在线的功能。
3、 HP:high performance 高性能(科学计算集群)
通常,多个计算机同时处理数据,以解决复杂的科学问题。这是并行计算的基础,尽管它不使用专门的并行超级计算机,这种超级计算机内部由十至上万个独立处理器组成。但它却使用商业系统,如通过高速连接来链接的一组单处理器或双处理器 PC,并且在公共消息传递层上进行通信以运行并行应用程序。使用最多的就是气象分析,科学勘探,核爆炸分析等。
实现方法
1、对于负载均衡集群,要实现可通过LVS,nginx,haproxy等工具实现
2、对于高可用集群,要实现可借助keepalived、hearbeat、corosync+pacemaker工具实现
3、对于高性能集群,要实现得从软硬件双方面着手
本文重点介绍高可用集群实现的几大组件。
keepalived介绍
Keepalived是一个基于VRRP协议来实现的服务高可用方案,可以利用其来避免IP单点故障,类似的工具还有heartbeat、corosync、pacemaker。但是它一般不会单独出现,而是与其它负载均衡技术(如lvs、haproxy、nginx)一起工作来达到集群的高可用。
VRRP全称 Virtual Router Redundancy Protocol,即 虚拟路由冗余协议。可以认为它是实现路由器高可用的容错协议,即将N台提供相同功能的路由器组成一个路由器组(Router Group),这个组里面有一个master和多个backup,但在外界看来就像一台一样,构成虚拟路由器,拥有一个虚拟IP(vip,也就是路由器所在局域网内其他机器的默认路由),占有这个IP的master实际负责ARP相应和转发IP数据包,组中的其它路由器作为备份的角色处于待命状态。master会发组播消息,当backup在超时时间内收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master,保证路由器的高可用。
在VRRP协议实现里,虚拟路由器使用 00-00-5E-00-01-XX 作为虚拟MAC地址,XX就是唯一的 VRID (Virtual Router IDentifier),这个地址同一时间只有一个物理路由器占用。在虚拟路由器里面的物理路由器组里面通过多播IP地址 224.0.0.18 来定时发送通告消息。每个Router都有一个 1-255 之间的优先级别,级别最高的(highest priority)将成为主控(master)路由器。通过降低master的优先权可以让处于backup状态的路由器抢占(pro-empt)主路由器的状态,两个backup优先级相同的IP地址较大者为master,接管虚拟IP。
heartbeat / Corosync+Pacemaker
一些慨念性问题
集群事物信息层(massage layer)
传递集群事物信息集群资源管理(Cluster Resource Manager)
CRM包过:DC(Designated Coordinator):DC上运行了两个进程,pe(决策引擎) te(事务引擎)PE(Policy Engine) 策略引擎,获取所有的节点信息,决定资源怎么分配,资源怎样启动,怎样启动,这样要通过资源约束来实现,资源约束通过配置接口实现。各个节点之间通过xml传递数据。pe通过CIB接受messaging layer信息。TE(Transactio Engine)LRM(Local Resource Manager)CRM通过LRM(本地资源管理器)管理执行,LRM调用RA来具体实现。CLB (cluster information base)集群信息库:使用CIB来配置xml文件。在配置集群时,可以连接到任何节点的CRM,配置cib,然后cib信息可以同步到DC中,DC再通知给 所有的CIB中。- 资源代理(Resource Agent)
当节点发生故障时,心跳信息传递给CRM,CRM通过集群决策,决定哪个备用节点启动,但是CRM没有能力启动节点上的服务(资源),因此需要借助于RA来实现
RA:Resource agent(服务启动的脚本?),能够被CRM调用,用于实现在节点上对某资源进行管理的工具,通常情况下是一个脚本。必须能够接受参数{start|stop|restart|status}。CRM会每隔固定时长(自定义)检查资源状态,因此status必须是runing或者stopped,而不能是否定状态的短语。
# 架构图
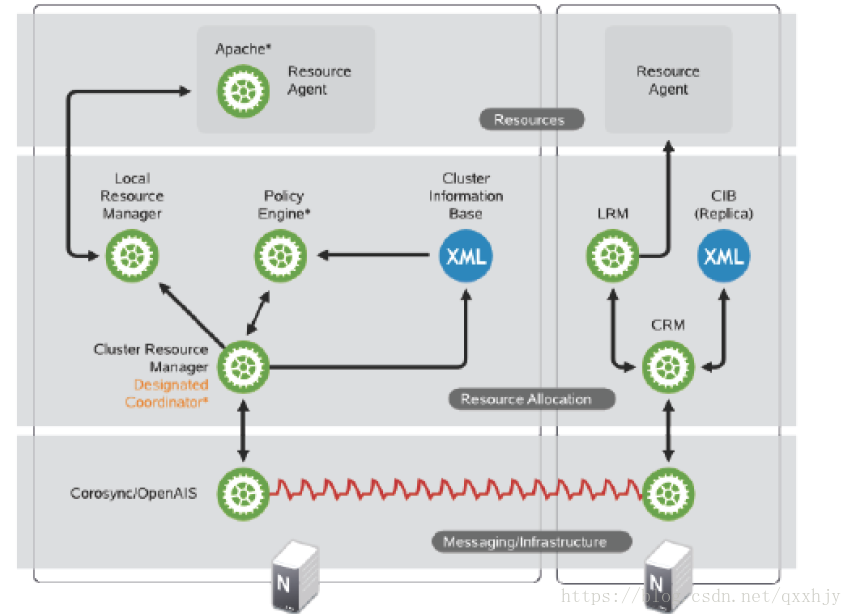
简单描述下整个过程,在最底部的messaging layer,所有的节点都安装了heartbeat或者corosync等软件,节点之间能够互相通信,然后在上一层,资源管理层,CRM来统筹管理由messaging传递过来的信息,托举一个DC,DC运行了两个进程,pe和te,pe是策略引擎,它根据CIB(集群资源仓库)收集到的所有的资源配置信息(获取当前互动节点的信息),进行决策。连接到任何一个节点的CRM都可以配置CIB,然后就可以同步到DC中,DC再通知所有的节点。然后CRM通过LRM来管理资源管理,而LRM则调用RA来具体控制资源。
在高可用的情况下,所有的资源都是由CRM控制LRM调用RA来控制,自动启动的,因此,不用让资源服务开机自动启动。一定要保证。可以通过chkconfig service off来停止开机自动启动服务
DC发现集群中有一个节点发生故障,剔除掉,然后根据在CRM中配置的规则(比如倾向性,倾向于优先使用哪个备用服务器),然后通过底层信息将集群事务决策传递给备节点,备节点CRM收到来自底层的信息后,通知LRM,调用RA,启动资源。
实现服务的高可用。一个服务由多个资源组成,例如一个web服务需要有vip、web服务、网页文件,又如lvs服务,至少有ipvs和规则等组成才能算是一个完整的服务。
集群系统可以通过单播,组播,广播进行集群事务信息通告。
上文涉及的策略
资源组:
- 一组资源共进退,比如vip和ipvs
资源约束
* 排列约束(colation):定义资源是否能够运行于同一节点* score:* 正值:可以在一起(inf:正无穷)* 负值:不能在一起(-inf:负无穷) * 位置约束(location):定义资源更倾向于运行在那个节点* score(分数)* 正值:倾向运行于该节点* 负值:倾向于逃离此节点 * 顺序约束(order):定义资源启动或关闭时的次序资源隔离
- 节点级别:STONITH(爆头):预防某个节点没挂透
- 资源级别:FC,SAN,SWITH可以实现在存储资源级别拒绝某节点的访问
共享设备和文件系统
要想所有数据在各节点进行共享使用,必须使用共享设备和共享文件系统
- 支持共享的设备
- NAS (在文件级别进行共享)
- SAN
- SCIC
提供集群事务传递的软件
1、heartbeat:heartbeat v1 heartbear v2 heartbear v3
2、corosync:OpenAIS定义了一套规范,分隔为corosync和一组api。这里corosync是主要使的,只用于实现messaging layer,不实现资源管理的功能。
3、cman:cluser manger,红帽的,是对OpenAIS的一种实现。
4、keepalived
5、ultramokey
提供集群资源管理的软件
1、heartbeat v1:haresources(hearbeat自带功能,配置接口是一个配置文件:haresource)。
2、heartbear v2:可以作为独立进程:crm(各个节点均运行进程crmd,5566,客户端使用crm进行交互(shell),完成配置),也有图形界面heartbeat-GUI
3、heartbeat v3:分隔多个项目 heartbear(底层信息传递)+pacemaker(CRM资源管理)+cluster-glue。pacemaker不仅可以与heartbear一起工作,也可以与corosync一起工作,这个时候需要使用cluster-glue进行粘合。
4、pacemaker:仍然使用crmd运行,配置接口使用crm(红帽对应的为psc),对应的GUI接口为hwk,LCMC,pacemaker-mgmt
5、rgmanager:cman使用的工具,resource group manager。故障转移域,failover domain。
RHCS:Redhat Cluster Suite(套件),配置接口,conga,全生命周期的配置接口
注意事项
1、 节点名称必须与uname -n命令结果一致
2、 ssh互信通信
3、时间同步
heartbeat
三个主要配置文件
1、秘钥文件,600,authkeys
2、heartbeat服务的配置文件ha.cf
3、资源管理配置文件
heartbeat通过resource配置文件管理资源,可以使用替代产品crmd来进行资源管理
crmd:提供命令行和推行界面的两种配置方式
例子
1、 HA MYSQL + HA HTTP
可以定义资源粘性,比如mysql更倾向于运行在A节点,http更倾向于B节点
2、 HA 双主mysql
集群文件系统:当一个节点在写共享文件时,会向文件施加一个所,而集群文件系统会向其他集结宣告这个锁,其他节点就不能同步写该共享文件。
集群文件系统有:GFS,OCFS2
支持集群文件系统的设备:DAS,SAN
d当测试到某个服务失败时,先尝试重启,再尝试资源转移