写在前面(这部分是废话)
这是参加 datawhale 数据挖掘的第一次打卡,打卡内容是数据分析,希望自己能坚持做下去。开始的时候,第一天看了一下题目背景,运行了一下 baseline,刚好中期报告要改,就放下了。今天在这里做一下数据分析这部分的笔记。
介绍
本文主要是根据天池上的教程进行学习的,一些不理解地方做了笔记,内容没有教程全,附上教程链接:Datawhale 零基础入门数据挖掘-Task2 数据分析
数据分析主要的三个工具: pandas、numpy、scipy。(以前只用过 numpy)
可视化的两个主要工具: matplotlib、seabon。(以前只用过 matplotib)
接下来通过代码加个人理解记录一下数据分析的过程。
数据分析过程
环境配置就不记录了,很无聊。首先需要导入一下包:
#coding:utf-8
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
后续代码默认使用如上导入的包。
载入数据
path = './data/'
Train_data = pd.read_csv(path+'used_car_train_20200313.csv', sep=' ')
Test_data = pd.read_csv(path+'used_car_testA_20200313.csv', sep=' ')
print(Train_data.shape)
print(Test_data.shape)
输出:
(150000, 31)
(50000, 30)
使用 pands 库可以很方便地读取数据。这里的 pd.read_csv() 函数有很多参数,这里只设置了两个: filepath_or_buffer 参数表示文件的路径; sep 表示数据使用什么符号分隔的,默认 sep = ','。还有很多其他参数,如 index_col 指定读取哪写列数据、shkiprows=n 跳过前 n 行数据…
查看数据
pd.read_csv() 函数返回的数据类型是 DataFrame,是 pandas 中特有的数据类型,相当于高级版的二维数组,可以通过它实现很多操作,封装了很多处理数据的函数。
关于 DataFrame 更多方法介绍,建议参考 python下的Pandas中DataFrame基本操作(一),基本函数整理
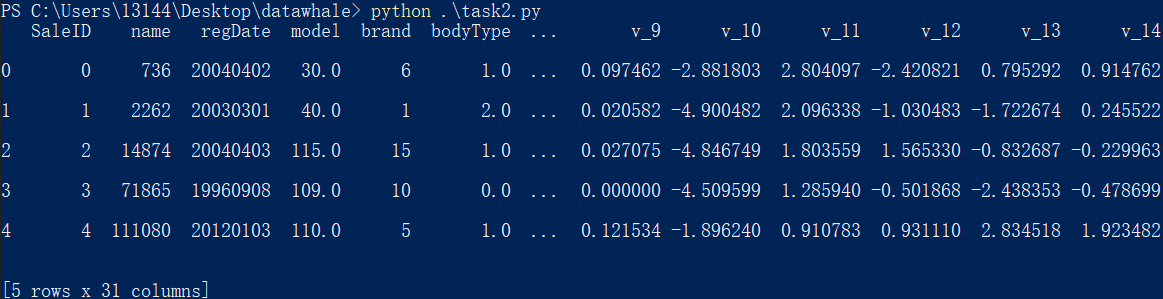
head(n=5)
可以通过 head(n) 函数展示数据的前 n 行数据,默认 n=5。
print(Train_data.head())
运行结果:
tail(n=5)
与 head() 函数相反,tail(n) 函数返回的是数据后 n 行数据,默认 n=5。
print(Train_data.tail())
运行结果:

总览数据
在查看了数据之后,对数据的样子就会有个大概的认识。但更多时候,只是查看数据长什么样子是不够的,还需要查看数据的性质,包括数据方差、个数等等。下面是几个常用的总览数据的方法。
describe(percentiles=None, include=None, exclude=None)
describe() 是针对 pandas 中 Series 或 DataFrame 所有的列进行数据统计的一种方法。函数是用来查看数值特征的一些信息,返回特征的总数、均值、标准差、最小值、分位数、最大值。
这里解释下函数的三个参数,具体理解,还请参考官网 pandas-dataframe-describe
-
percentiles:数组类型,表示分位线。所有值应该是(0,1)之间的小数,默认是 [.25, .5, .75],返回 25%, 50%和75%
-
include, exclude : 列表类型,指定输出结果的形式。分三种情况,当二者都为
None时,结果只包含数值类型的统计信息;如果是一组dtypes或strings,所有数值类型使用numpy.number,类别属性使用type;如果include='all',则输出的列与输入相同。
示例:
print(Train_data.describe())
运行结果:
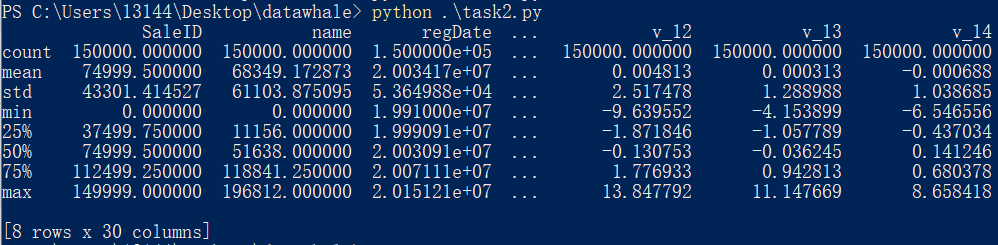
其中,百分数 25%, 50%和75% 表示分位数,表示在把所有数值由小到大排序,并分成四等份,处于三个分割点位置的数值。
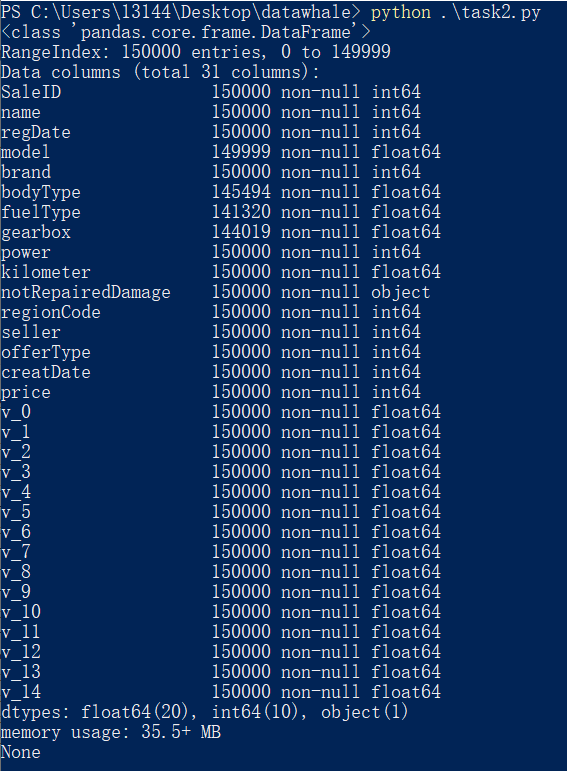
info(verbose=None, buf=None, max_cols=None, memory_usage=None, null_counts=None)
info() 函数可以用来查看 DataFrame 信息, 能够简要看到对应一些数据列名,了解数据每列的 type,以及 NAN 缺失信息。
参数介绍:
- verbose:如果为True,则显示所有列;如果为False,则会省略一部分。
- buf:结果输出到的位置。
- max_cols:输出列的最大数目,超过则进行缩减输出。
- memory_usage:是否显示 DataFrame 的内存使用情况,缺省(None)时,默认为 True。
- null_counts:是否显示非空计数。
示例:
print(Train_data.info())
运行结果:
数据缺失和异常
统计数据信息查看完后,还要进一步查看数据是否异常,如 nan 或 null。
isnull()
isnull() 函数,以布尔的方式返回所有数据是否为 null 的信息,返回值的类型也是 DataFrame。
示例:
Train_data.isnull().sum()
运行结果:
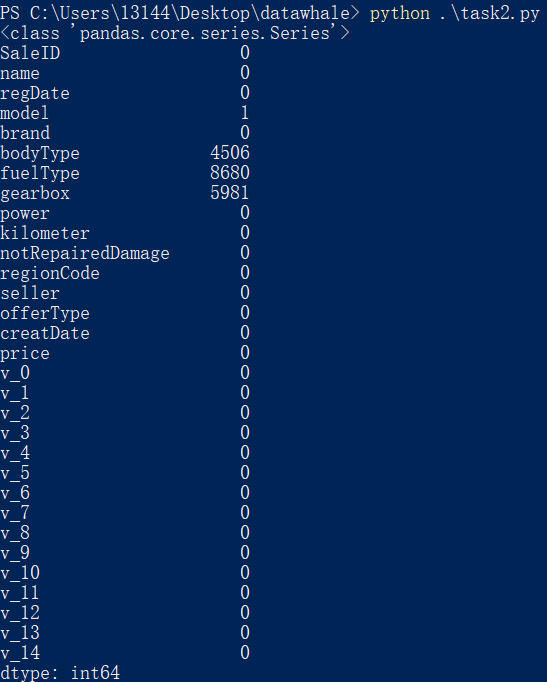
其中,sum() 函数按列进行求和,返回一个 Series 类型的值。
缺失数据的可视化
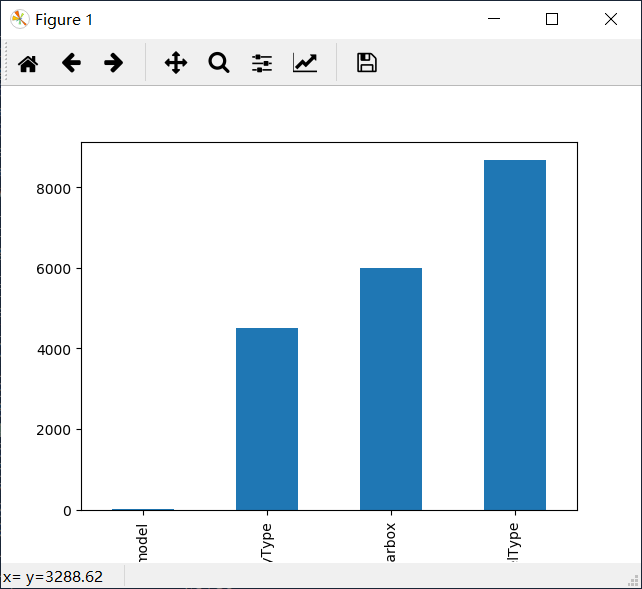
示例:
missing = Train_data.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar() # 垂直条形图
plt.show()
运行结果:
示例:
msno.matrix(Train_data.sample(250))
plt.show()
sample() 函数表示随机选取若干行。
运行结果:

示例:
msno.bar(Train_data.sample(1000))
plt.show()
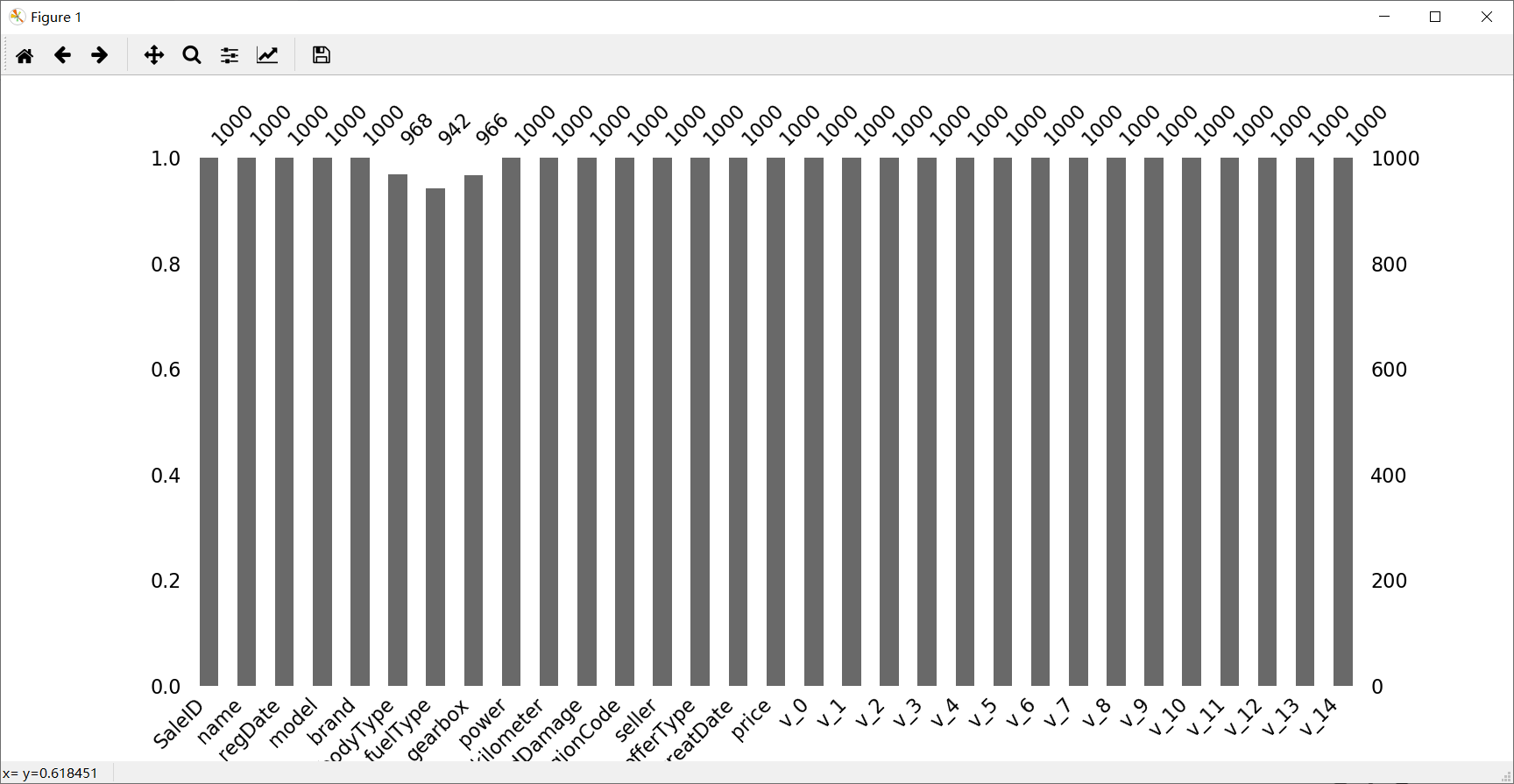
统计信息
查看类型为 object 特征:
print(Train_data['notRepairedDamage'].value_counts())
输出:
0.0 111361
- 24324
1.0 14315 Name: notRepairedDamage, dtype: int64
将值替换成 nan:
Train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
print(Train_data['notRepairedDamage'].value_counts())
输出:
0.0 111361
1.0 14315
Name: notRepairedDamage, dtype: int64
去掉倾斜严重的特征
查看以下两个特征(按照教程做的,事先肯定不知道哪个特征严重倾斜)
print(Train_data["seller"].value_counts())
print(Train_data["offerType"].value_counts())
输出:
0 149999
1 1
Name: seller, dtype: int64
0 150000
Name: offerType, dtype: int64
分析数据分布
查看要预测数据(price)的分布信息:
import scipy.stats as st
y = Train_data['price']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
plt.show()
就不展示图像了。
查看偏度和峰度
简单理解一下偏度和峰度的概念,参考:数据的偏度和峰度――df.skew()、df.kurt()
-
偏度: 表示数据总体取值分布的对称性。
-
峰度: 表示数据分布顶的尖锐程度。
sns.distplot(Train_data['price']);
print("Skewness: %f" % Train_data['price'].skew())
print("Kurtosis: %f" % Train_data['price'].kurt())
plt.show()
运行结果:
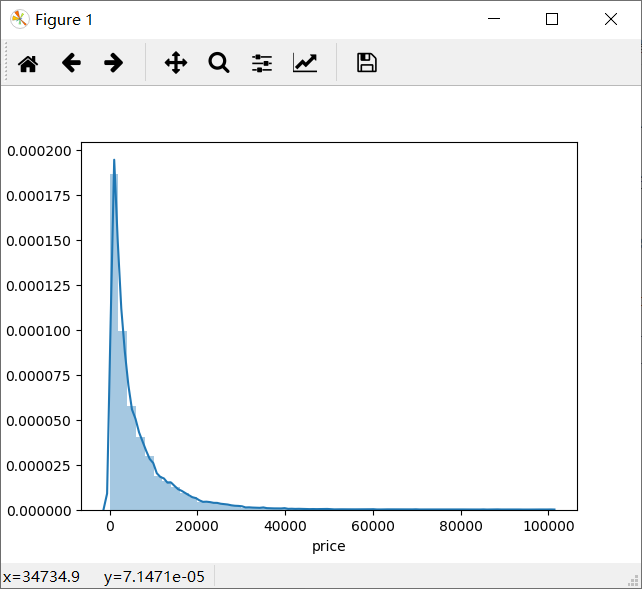
Skewness: 3.346487
Kurtosis: 18.995183
查看帧数,更具体地查看数据分布
plt.hist(Train_data['price'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()
# log 变换后的分布
plt.hist(np.log(Train_data['price']), orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()
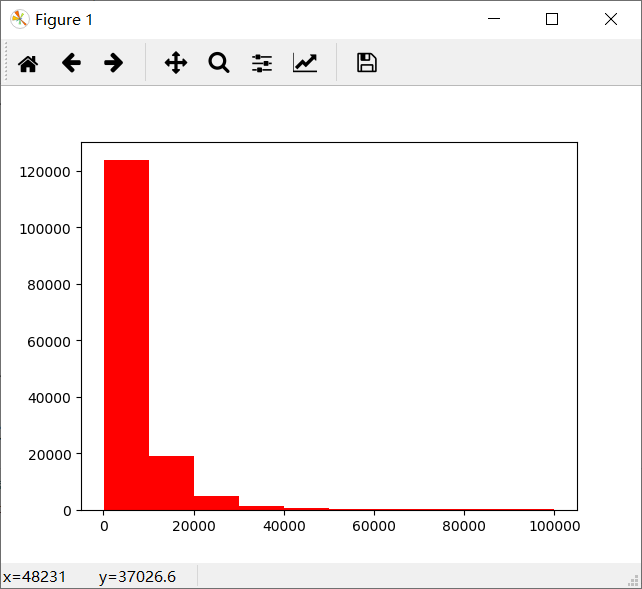
会发现大于 20000 的数据很少。
做 log 之后的数据分布图:
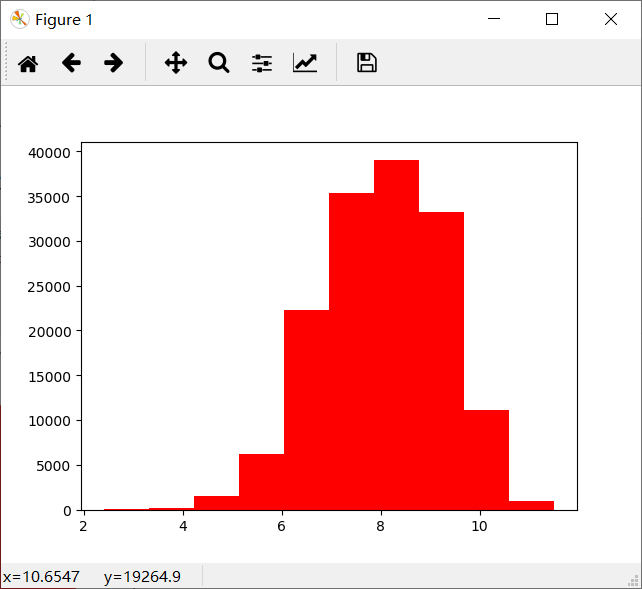
会发现数据分布不像之前那样集中了。
特征分类
select_dtypes()
特征分为类别特征和数字特征。可以使用 select_dtypes() 函数查看两种特征各包含哪些列:
# 数字特征
numeric_features = Train_data.select_dtypes(include=[np.number])
print(numeric_features.columns)
# 类别特征
categorical_features = Train_data.select_dtypes(include=[np.object])
print(categorical_features.columns)
运行结果:
Index([‘SaleID’, ‘name’, ‘regDate’, ‘model’, ‘brand’, ‘bodyType’, ‘fuelType’,
‘gearbox’, ‘power’, ‘kilometer’, ‘regionCode’, ‘creatDate’, ‘price’,
‘v_0’, ‘v_1’, ‘v_2’, ‘v_3’, ‘v_4’, ‘v_5’, ‘v_6’, ‘v_7’, ‘v_8’, ‘v_9’,
‘v_10’, ‘v_11’, ‘v_12’, ‘v_13’, ‘v_14’],
dtype=‘object’)
Index([‘notRepairedDamage’], dtype=‘object’)
注意:这个区别方式适用于没有直接label coding的数据,这里把很多类别特征用数字表示了,因此该方法在该比赛中不适用,需要人为根据实际含义来区分
unique() 和 nunique()
unique() 函数返回的是特征的所有唯一值;nunique() 函数返回的是特征中所有唯一值的个数。
示例,查看每个分类特征的分布:
# 特征nunique分布
for cat_fea in categorical_features:print(cat_fea + "的特征分布如下:")print("{}特征有个{}不同的值".format(cat_fea, Train_data[cat_fea].nunique()))print(Train_data[cat_fea].value_counts())
接下来详细介绍一下数字特征和类别特征。
数字特征分析
好多啊,,,后面两部分简写一下。。。
1. 使用 corr() 分析相关性
corr() 函数返回的是各个特征之间的相关系数,是 DataFrame 类型。
示例:
# 数字特征
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
numeric_features.append('price')
## 1) 相关性分析
price_numeric = Train_data[numeric_features]
correlation = price_numeric.corr()
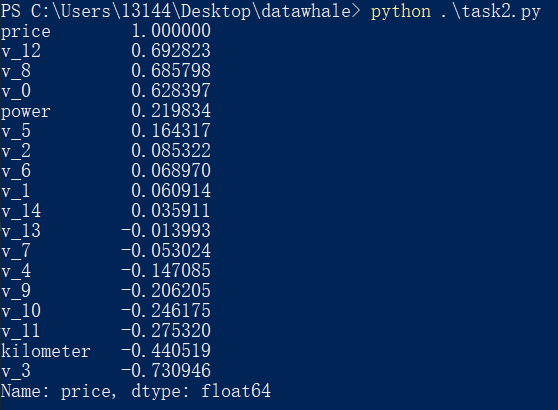
print(correlation['price'].sort_values(ascending = False),'\n')
运行结果:
以热力图的形式画出各个数字特征之间的相关系数:
# 画相关系数图
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation, square=True, vmax=0.8)
plt.show()
运行结果:
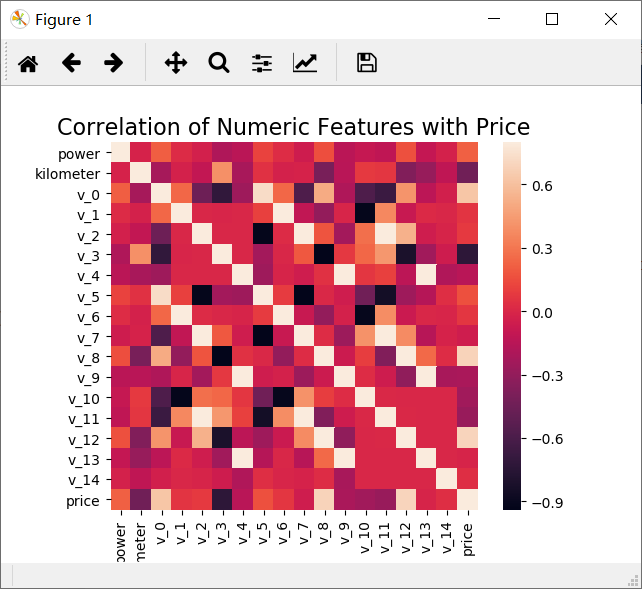
关于热力图的画法,参考:sns.heatmap的用法简介
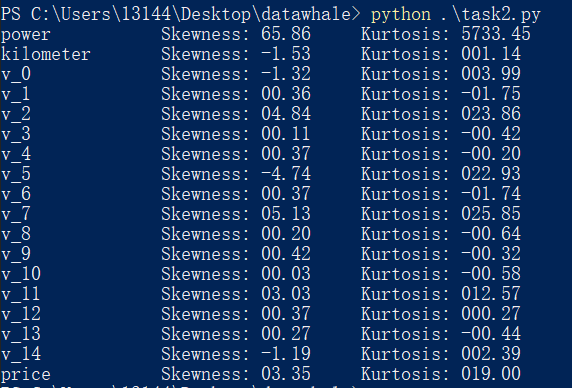
2. 查看各个特征的偏度和峰度
示例:
## 2) 查看几个特征的 偏度和峰值
for col in numeric_features:print('{:15}'.format(col), 'Skewness: {:05.2f}'.format(Train_data[col].skew()) , ' ' ,'Kurtosis: {:06.2f}'.format(Train_data[col].kurt()) )
运行结果:
3. 每个数字特征得分布可视化
示例:
## 3) 每个数字特征的分布可视化
f = pd.melt(Train_data, value_vars=numeric_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
plt.show()
melt() 函数是一个逆转操作,其中的 value_vars 参数表示需要转换的列名。
运行结果:
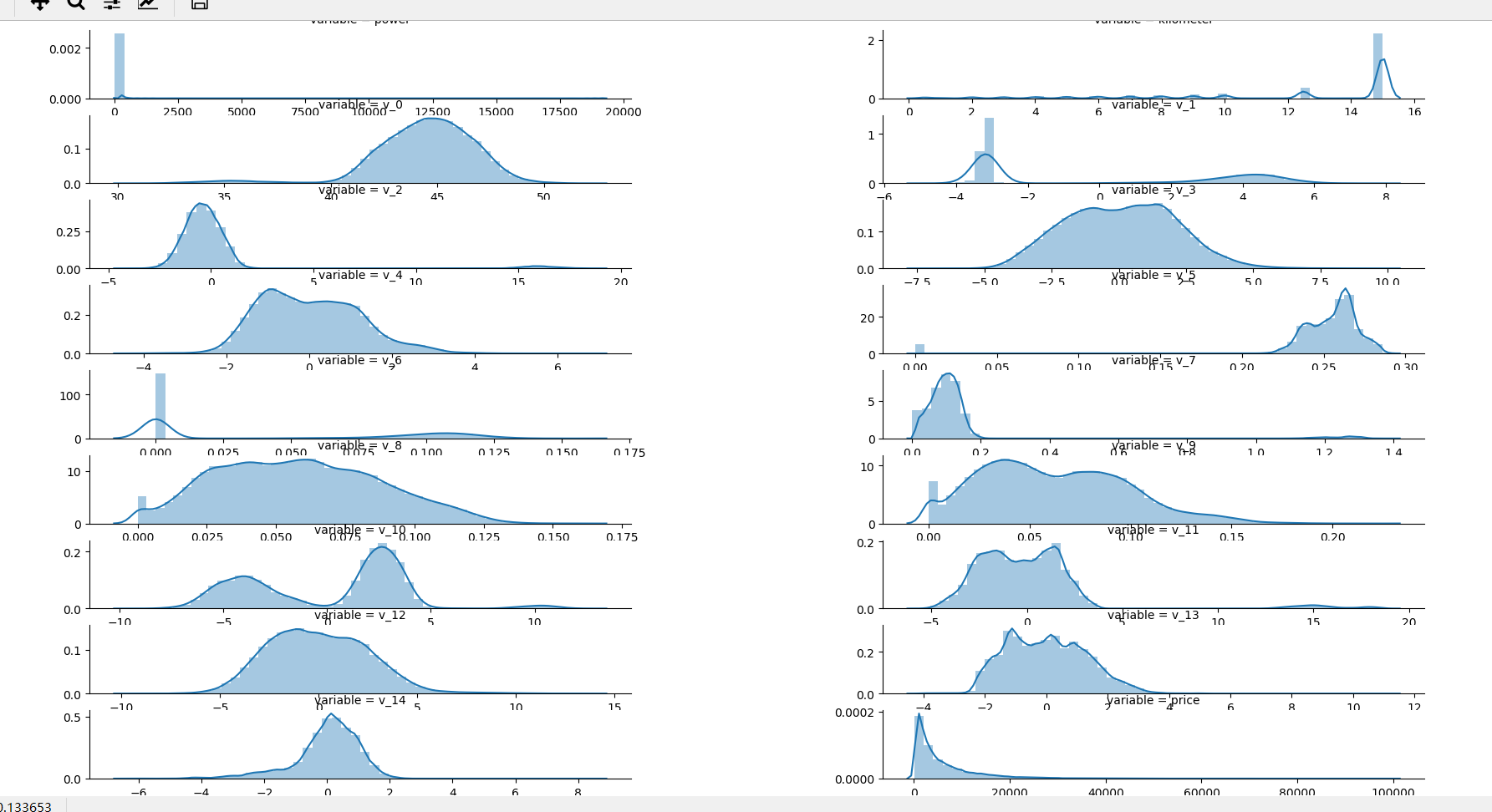
4. 数字特征相互之间的关系可视化
## 4) 数字特征相互之间的关系可视化
sns.set()
columns = ['price', 'v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14']
sns.pairplot(Train_data[columns],size = 2 ,kind ='scatter',diag_kind='kde')
plt.show()

5. 多变量互相回归关系可视化
参考:Seaborn-05-Pairplot多变量图
分类特征
好多画图的,不想记录了,这部分简写一下。
-
unique分布(前面记录了)
-
类别特征箱形图可视化
-
类别特征的小提琴图可视化
-
类别特征的柱形图可视化
-
类别特征的每个类别频数可视化(count_plot)
pandas_profiling
最后,可以用 pandas_profiling 生成一个较为全面的可视化和数据报告。
最后
后面的内容就简单写了一下过程,后续还会补充点东西,主要是了解整个数据分析的过程。