1.Dice系数
Dice距离主要是用来计算两个集合的相似性的(也可以度量字符串的相似性).计算公式如下:
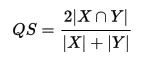
2. F1 score
F1分数是用来衡量二分类模型精确度的一种指标,同时考虑到分类模型的准确率和召回率.可看做是准确率和召回率的一种加权平均.
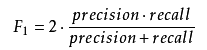
在已知精确率和召回率的情况下 求得的一种平均的结果.
3. 各种指标的含义
precision: 预测为对的当中,原本是对的比例(越大越好,1为理想状态)
recall:原本为对的当中,预测是对的比例(越大越好,1为理想状态)
F-measure: 由于precision和recall两个指标不想管,所以用F-measure将他们合并成一个衡量指标(越大越好.理想为1)
accuracy: 预测正确的(包括预测对的正例和反例)占整个样本的比例(越大越好,理想为1)
FP rate : 原本是错的,但是预测为对的比例(越小越好,理想为0)
TP rate: 原本为对的,预测为对的比例(越大越好,理想为1)
ROC 曲线: 得到某算法的一组(FP rate, TP rate), 然后做出曲线; 衡量标准是AUC,
ROC-AUC: ROC 曲线下的面积(越大越好,1为理想状态)
PR曲线: 以recall作为横坐标,以precision作为纵坐标绘制的曲线..如果recall和precision二者都是越大越好,但是二者是负相关的. 所以PR曲线是越往忧伤凸越好(双高的状态),