1.�����ܽ�
- AWS�ķ���ȫ������SOA�ܹ�������Ҫʱ�����
- ���ڴ����ݵ�ʵʱ��������AWS�ṩ�˴�ͳ��������ȫhost����
- ��ͳ������EC2���沿��flume ���ɼ�����kafka������ת�棩��storam����������
- ��ȫhost������Kinesis
- ʹ��Kinesis������Ҫ�û�ͨ��API�����ֻ�����վ�����IoT���������ȸ�������Դ�����ݽ���
- �����û���дKinesis��Worker�������Զ�������ݴ���������չ�ԣ�
- Kinesis����֮������ݣ�AWS����洢S3��redshift�ȴ洢�У�����ʹ��
- Kinesis�ĵ����÷��ǣ�ǰ������Դ��kinesis��������S3������ʱ���ݡ�EMR���ݴ�����redshift��BI����������ʹ��CW�������м�أ����ҿ��Գ���AutoScaling������������������
- Kinesisʵʱ��������Ӧ�ó���
- ���ڹ��ƽ̨���û��ڻ������ϵ���Ϊ����ʵʱ��Ӱ�����������ݣ����û���һ��ˢ��ҳ��ʱ�����ṩ���û��¹��
- ���ڵ������û���ÿһ���ղء������������Ϊ�����ܱ����ٵĹ������ĸ���ģ���У�����������Ʒ�Ƽ�
- �����罻�������û��罻ͼ�ױ���ͷ�����Ϊ��Ҳ�ܿ��ٷ�ӳ�����ĺ����Ƽ������Ż���������
2.����
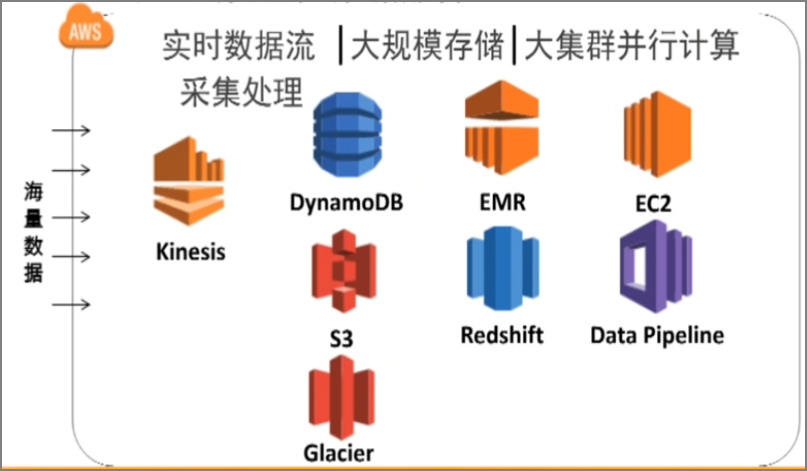
2.1.AWS�����Ƶ����������ݷ���
- �ɼ���ʵʱ�������ɼ�������Kinesis��
- ���棺���ģ�洢
- DynonamoDB
- S3
- Glacier
- ��������Ⱥ���м���
- EMR
- EC2
- Redshift�CMPP���ݿ�
- Data Pipeline�CETL����
2.2.AWS�Ĵ����ݿͻ�
������ҩ������������˾������ҵ

3.�����ݷ�������
3.1.�����ݴ�������ս
�����ݵ��������ڣ��ռ����洢������������
�ɹ�������SUPERCELL���ι�˾
- �ռ���ʵʱ���ݲɼ�Kinesis
- �洢��4T�洢/���S3
- ���ڹ鵵Glacier
- �����������ھ�Hadoop

3.2.ʵʱ����������ʹ�ð���
- ���ڹ��ƽ̨���û��ڻ������ϵ���Ϊ����ʵʱ��Ӱ�����������ݣ����û���һ��ˢ��ҳ��ʱ�����ṩ���û��¹��
- ���ڵ������û���ÿһ���ղء������������Ϊ�����ܱ����ٵĹ������ĸ���ģ���У�����������Ʒ�Ƽ�
- �����罻�������û��罻ͼ�ױ���ͷ�����Ϊ��Ҳ�ܿ��ٷ�ӳ�����ĺ����Ƽ������Ż���������
4.���͵�ʵʱ��̬�����������ܹ���������
1�����ݲɼ�������Ӹ����ڵ���ʵʱ�ɼ��������ݣ�����ѡ��flume��cloudeara�ṩ����ʵ��
2�����ݽ��룺���ڲɼ����ݵ��ٶȺʹ������ٶȲ�һ��ͬ�����������һ����Ϣ�м����Ϊ���壬����apache��kafka��Linkedin�ṩ��
3����ʽ���㣺�Բɼ��������ݽ���ʵʱ����������ѡ��apache��storm��twitter�ṩ��

5.��AWS�Ͻ��д�������ģʽ��
1�����ݲɼ�����EC2�������ϴ�ռ�����kafka��fluedtd��scribe��flume�ȣ�
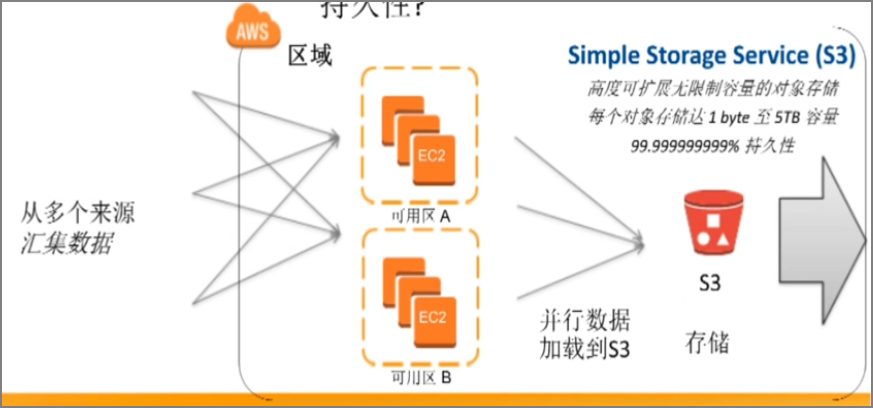
2���������ݡ������ݴ���S3
���Ƽ��洢�ڱ��ش��̣���Ϊ���Ա�֤������չ�ԣ����Ա��ϳ־���
6.��AWS�Ͻ��д�����Kinesisģʽ��
ʵʱ���ݴ����CAmazon Kinesis
- ʵʱ���ݲɼ������룬����
- ����ʵʱ��̬������
- ��������
- ֧�������������ͬ�洢Ŀ�ĵ�
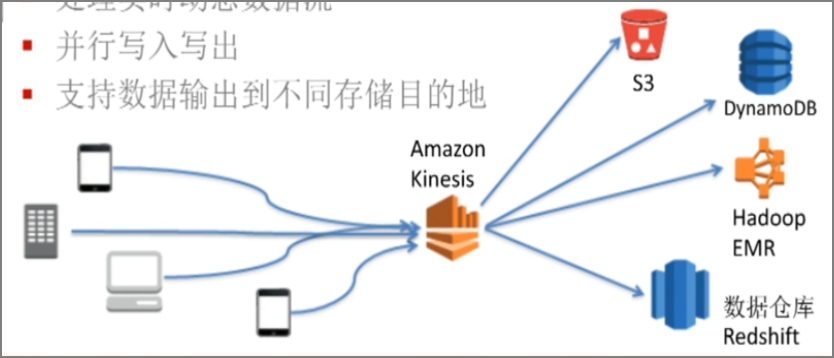
Amazon Kinesis�ļܹ�ģ������ͼ
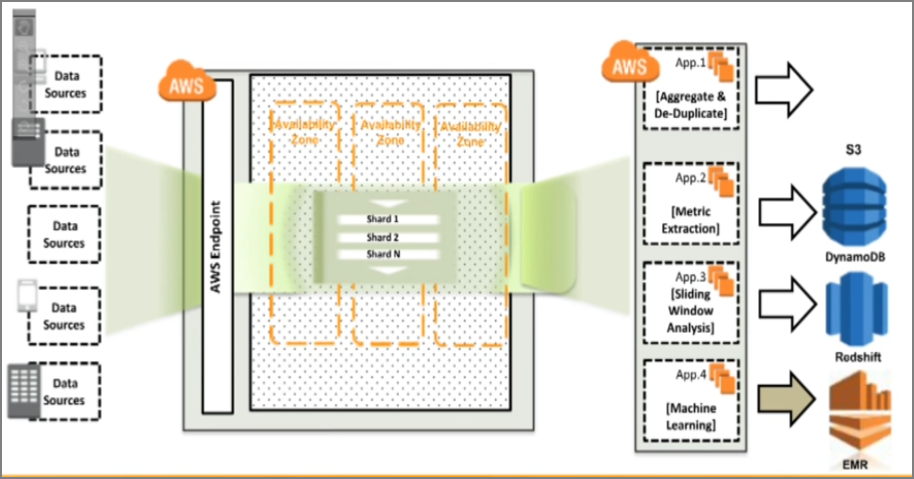
��������
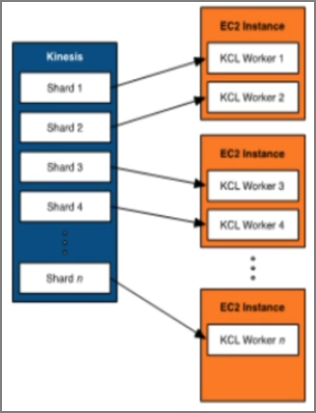
1������һ��������������ʹ��storm�����ƶ�shard����Ƭ��
- shard����Ƭ��Kinesis�������Ļ�����������λ
- һ����Ƭ�ṩ��1MB/���������루write������=1000TPS��2MB/�����ݶ��루read������=5TPS
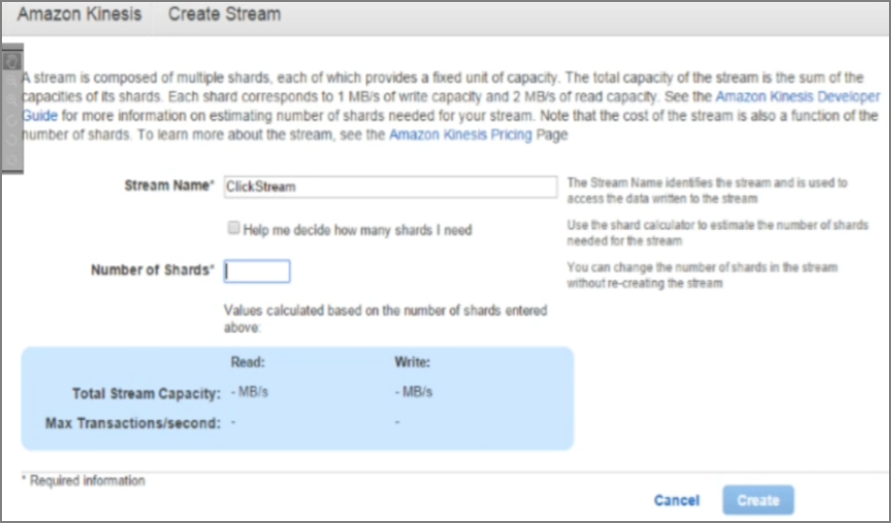
2���趨��������Ƭ�����������磺twitter��ÿ����¼Ϊ140�ֽڣ����趨ÿ����ͬʱд����������5000�������ķ�Ƭ��
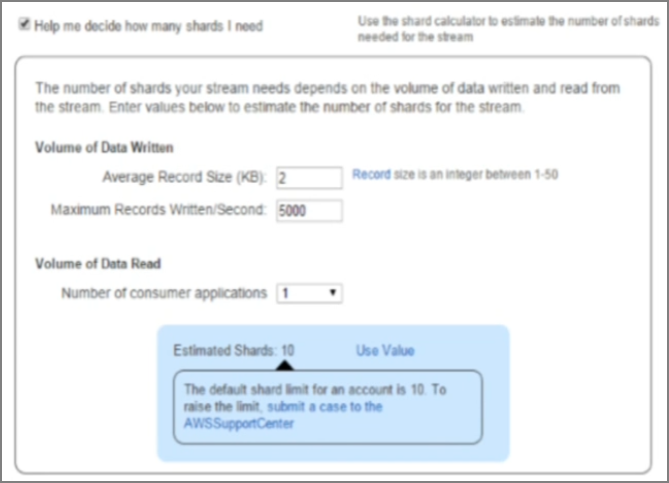
ָ����Ƭ��������������Ƭ������ͬʱд���� ֮�ͻ��Զ��������е�������
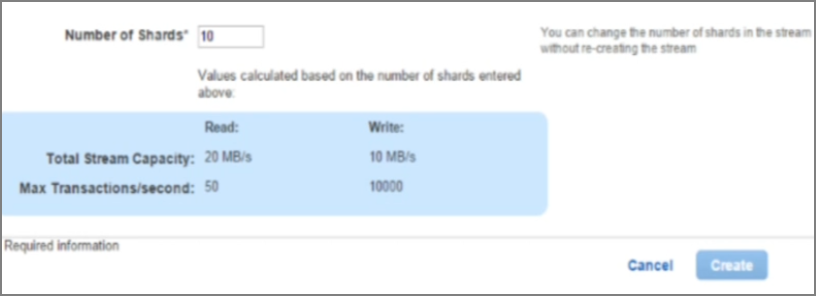
3�� ������CW�п��Լ���������
�ͻ���������ͨũ����
- ����put���̬��������
- ÿ����Ƭ������ÿ��1MB���ݣ��ߴ�1000TPS��
- ��ͻȻ��ұ���֮��ͣ��״̬�¶�̬��չ shard����
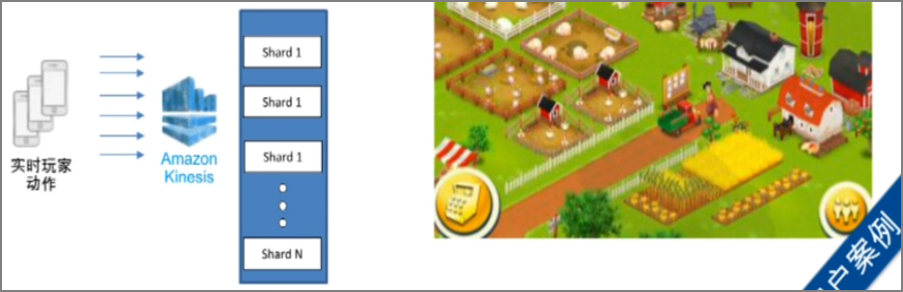
6.1.����������Kinesis������
- PutRecord API�����������ݵ�Amazon Kinesis ������
- ָ�������������ƺͷ�������partition key��
- ���������ڷ������ݼ�¼����ͬ����������Ƭ
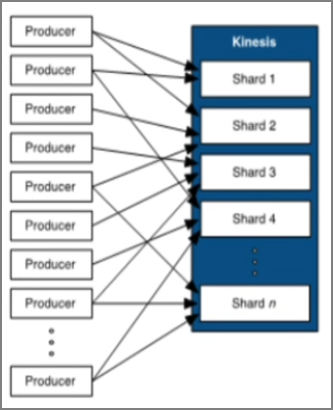
6.2.ʵʱ����������
- �ֲ�ʽ������shards
- �ݴ�
- ʵʱ��̬��չworkers
- רע���ݴ�����
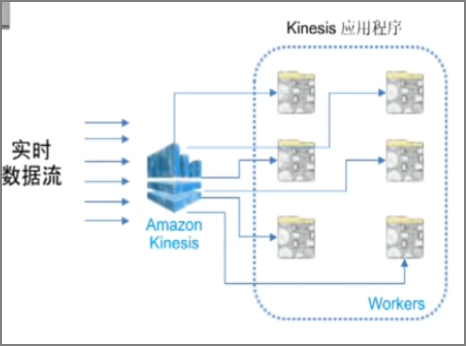
6.3.��������Amazon Kinesis������������
Amazon KinesisӦ�ó���workers�������û��Լ�����
- ��ȡ�ʹ�������������strom���ݵ�ʹ����
- ʹ��Kinesis�ͻ��˿ޣ�KCL������Ӧ�ó���ִ�зֲ�ʽ�������ķ�������
- �Զ���չ�飨AutoScaling��ʵʱ��̬��չ
6.4.Amazon Kinesis �Ա� Storm
- Storm
- ����ɼ����ߣ�����flume
- �������ݽ��빤�ߣ�����kafka
- ����ʵʱ�������ߣ�����storm
- Kinesis
- �Զ����òɼ������롢��������
- �Զ���չ���ݴ�
- ��AWS���������ںϣ�����s3��redshift��dynamoDB
6.5.ʵʱ����������&�������ݴ洢����
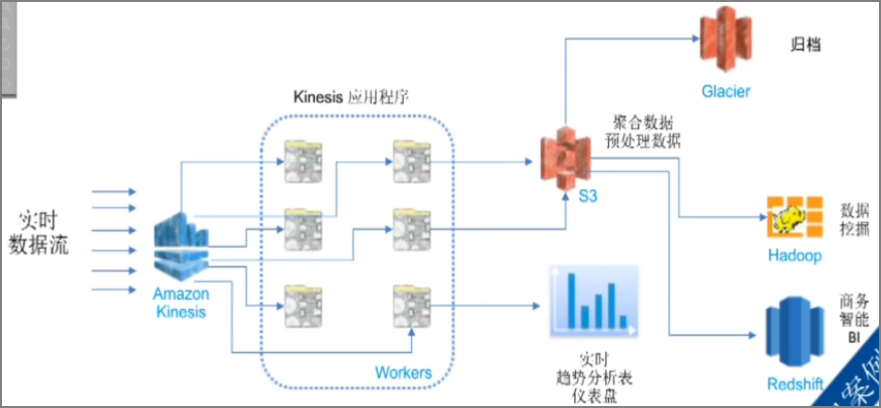
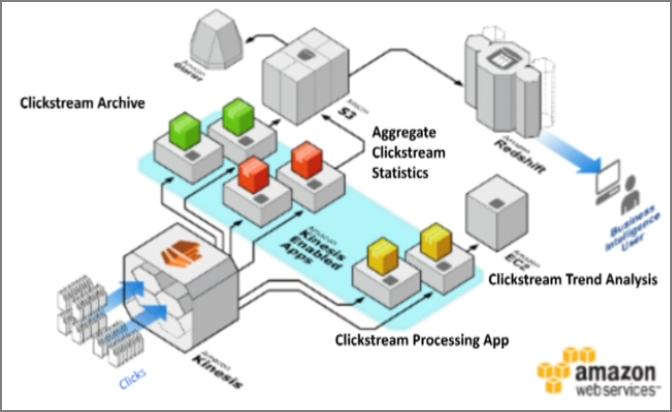
- supercell���û������Ļ��ʵʱ��������д��kinesis
- workerӦ�ó���������Щ����
- �ۺ�����Ԥ����д��S3
- ʵʱ���Ʒ�������������������������������ʹ������ȣ�
- Glacier�������鵵
- hadoop�����������ھ�EMR��S3�л�ȡ���ݣ�
- ��hadoop������Ϻ�����ݣ�����redshift����BI����
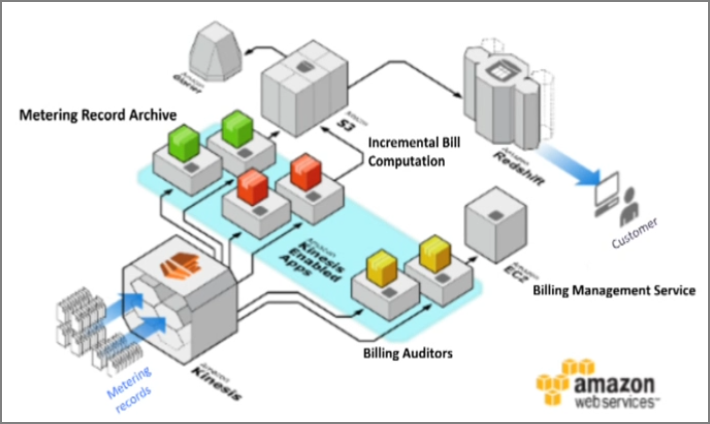
6.6.AWS��Kinesis�ij���CDP�ܹ�
#1 ���������
#2 ֧��
7.�ܽ�
- ʵʱ�ռ�����������
����ʹ��
- ͨ��java��python��KCL���ɹ���Ӧ�ó���
- ��S3��Redshift��DynamoDB����������
�����
- �ۺ����ݷ��͵�S3�洢������
- ʵʱ������־���ڷ����������ʱ��������
- ʵʱ������վ�����
���Ӧ��
- ��̬����Kinesis��������������
�ɿ�
- ����AZͬ���������ݣ�������24Сʱ����ֹӦ�ù��Ϻ����ݶ�ʧ