ЁОbatch sizeЁПЃКжаЮФЗвыЮЊХњДѓаЁЃЈХњГпДчЃЉЁЃ
МђЕЅЕуЫЕЃЌХњСПДѓаЁНЋОіЖЈЮвУЧвЛДЮбЕСЗЕФбљБОЪ§ФПЁЃ
batch_sizeНЋгАЯьЕНФЃаЭЕФгХЛЏГЬЖШКЭЫйЖШЁЃ
ЮЊЪВУДашвЊгаBatch_SizeЃК
batchsizeЕФе§ШЗбЁдёЪЧЮЊСЫдкФкДцаЇТЪКЭФкДцШнСПжЎМфбАевзюМбЦНКтЁЃ
Batch_SizeЕФШЁжЕЃК
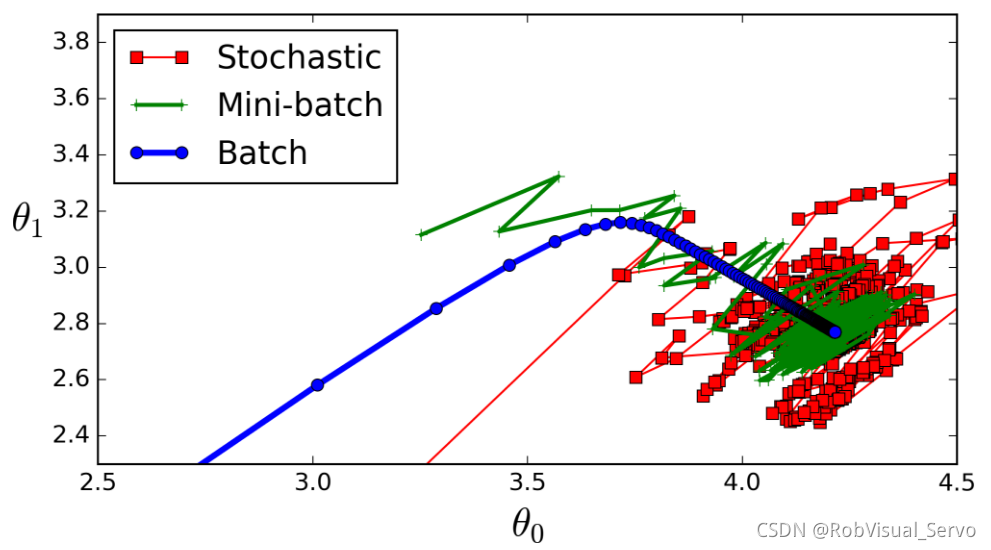
ШЋХњДЮЃЈРЖЩЋЃЉ
ШчЙћЪ§ОнМЏБШНЯаЁЃЌЮвУЧОЭВЩгУШЋЪ§ОнМЏЁЃШЋЪ§ОнМЏШЗЖЈЕФЗНЯђФмЙЛИќКУЕФДњБэбљБОзмЬхЃЌДгЖјИќзМШЗЕФГЏЯђМЋжЕЫљдкЕФЗНЯђЁЃ
зЂЃКЖдгкДѓЕФЪ§ОнМЏЃЌЮвУЧВЛФмЪЙгУШЋХњДЮЃЌвђЮЊЛсЕУЕНИќВюЕФНсЙћЁЃ
УдФуХњДЮЃЈТЬЩЋЃЉ
бЁдёвЛИіЪЪжаЕФBatch_SizeжЕЁЃОЭЪЧЫЕЮвУЧбЁЖЈвЛИіbatchЕФДѓаЁКѓЃЌНЋЛсвдbatchЕФДѓаЁНЋЪ§ОнЪфШыЩюЖШбЇЯАЕФЭјТчжаЃЌШЛКѓМЦЫуетИіbatchЕФЫљгабљБОЕФЦНОљЫ№ЪЇЃЌМДДњМлКЏЪ§ЪЧЫљгабљБОЕФЦНОљЁЃ
ЫцЛњЃЈBatch_SizeЕШгк1ЕФЧщПіЃЉЃЈКьЩЋЃЉ
УПДЮаое§ЗНЯђвдИїздбљБОЕФЬнЖШЗНЯђаое§ЃЌКсГхжБзВИїздЮЊеўЃЌФбвдДяЕНЪеСВЁЃ
ЪЪЕБЕФдіМгBatch_SizeЕФгХЕуЃК
1.ЭЈЙ§ВЂааЛЏЬсИпФкДцРћгУТЪЁЃ
2.ЕЅДЮepochЕФЕќДњДЮЪ§МѕЩйЃЌЬсИпдЫааЫйЖШЁЃЃЈЕЅДЮepoch=(ШЋВПбЕСЗбљБО/batchsize)/iteration=1ЃЉ
3.ЪЪЕБЕФдіМгBatch_Size,ЬнЖШЯТНЕЗНЯђзМШЗЖШдіМгЃЌбЕСЗе№ЖЏЕФЗљЖШМѕаЁЁЃЃЈПДЩЯЭМБуПЩжЊЯўЃЉ
ОбщзмНсЃК
ЯрЖдгке§ГЃЪ§ОнМЏЃЌШчЙћBatch_SizeЙ§аЁЃЌбЕСЗЪ§ОнОЭЛсЗЧГЃФбЪеСВЃЌДгЖјЕМжТunderfittingЁЃ
діДѓBatch_Size,ЯрЖдДІРэЫйЖШМгПьЁЃ
діДѓBatch_Size,ЫљашФкДцШнСПдіМгЃЈepochЕФДЮЪ§ашвЊдіМгвдДяЕНзюКУЕФНсЙћЃЉ
етРяЮвУЧЗЂЯжЩЯУцСНИіУЌЖмЕФЮЪЬтЃЌвђЮЊЕБepochдіМгвдКѓЭЌбљвВЛсЕМжТКФЪБдіМгДгЖјЫйЖШЯТНЕЁЃвђДЫЮвУЧашвЊбАевзюКУЕФBatch_SizeЁЃ
дйДЮжиЩъЃКBatch_SizeЕФе§ШЗбЁдёЪЧЮЊСЫдкФкДцаЇТЪКЭФкДцШнСПжЎМфбАевзюМбЦНКтЁЃ
ЁОiterationЁПЃКжаЮФЗвыЮЊЕќДњЁЃ
ЕќДњЪЧжиИДЗДРЁЕФЖЏзїЃЌЩёОЭјТчжаЮвУЧЯЃЭћЭЈЙ§ЕќДњНјааЖрДЮЕФбЕСЗвдДяЕНЫљашЕФФПБъЛђНсЙћЁЃ
УПвЛДЮЕќДњЕУЕНЕФНсЙћЖМЛсБЛзїЮЊЯТвЛДЮЕќДњЕФГѕЪМжЕЁЃ
вЛИіЕќДњ=вЛИіе§ЯђЭЈЙ§+вЛИіЗДЯђЭЈЙ§ЁЃ
ЁОepochЁПЃКжаЮФЗвыЮЊЪБЦкЃЈЕќДњТжДЮЃЉЁЃ
вЛИіЪБЦк=ЫљгабЕСЗбљБОЕФвЛИіе§ЯђДЋЕнКЭвЛИіЗДЯђДЋЕнЁЃ
ЩюЖШбЇЯАжаОГЃПДЕНepochЁЂiterationКЭbatchsizeЃЌЯТУцАДеездМКЕФРэНтЫЕЫЕетШ§ИіЧјБ№ЃК
ЃЈ1ЃЉbatchsizeЃКХњДѓаЁЁЃдкЩюЖШбЇЯАжаЃЌвЛАуВЩгУSGDбЕСЗЃЌМДУПДЮбЕСЗдкбЕСЗМЏжаШЁbatchsizeИібљБОбЕСЗЃЛ
ЃЈ2ЃЉiterationЃК1ИіiterationЕШгкЪЙгУbatchsizeИібљБОбЕСЗвЛДЮЃЛ
ЃЈ3ЃЉepochЃК1ИіepochЕШгкЪЙгУбЕСЗМЏжаЕФШЋВПбљБОбЕСЗвЛДЮЃЛ
ОйИіР§згЃЌбЕСЗМЏга1000ИібљБОЃЌbatchsize=10ЃЌФЧУДЃК
бЕСЗЭъећИібљБОМЏашвЊЃК
100ДЮiterationЃЌ1ДЮepochЁЃ
ВЮПМСДНгЃКhttp://blog.csdn.net/anshiquanshu/article/details/72630012
------------------------------------------------------ЛЊРіЕФЗжИюЯп----------------------------------------------------
ЩёОЭјТчбЕСЗжаЃЌEpochЁЂBatch SizeЁЂКЭЕќДњЩЕЩЕЕФЗжВЛЧхЃП
ЮЊСЫРэНтетаЉЪѕгягаЪВУДВЛЭЌЃЌЮвУЧашвЊСЫНтвЛаЉЙигкЛњЦїбЇЯАЕФЪѕгяЃЌБШШчЬнЖШЯТНЕЃЌАяжњЮвУЧРэНтЁЃ
етРяМђЕЅЕФзмНсЬнЖШЯТНЕЕФКЌвхЃК
ЬнЖШЯТНЕЪЧвЛИідкЛњЦїбЇЯАжагУгкбАевНЯМбНсЙћЃЈЧњЯпЕФзюаЁжЕЃЉЕФЕќДњгХЛЏЫуЗЈЁЃ
ЬнЖШЕФКЌвхЪЧаБТЪЛђепаБЦТЕФЧуаБЖШЁЃ
ЯТНЕЕФКЌвхЪЧДњМлКЏЪ§ЕФЯТНЕЁЃ
ЫуЗЈЪЧЕќДњЕФЃЌвтЫМЪЧашвЊЖрДЮЪЙгУЫуЗЈЛёШЁНсЙћЃЌвдЕУЕНзюгХЛЏНсЙћЁЃЬнЖШЯТНЕЕФЕќДњаджЪФмЪЙЧЗФтКЯбнБфГЩЛёЕУЖдЪ§ОнЕФНЯМбФтКЯЁЃ
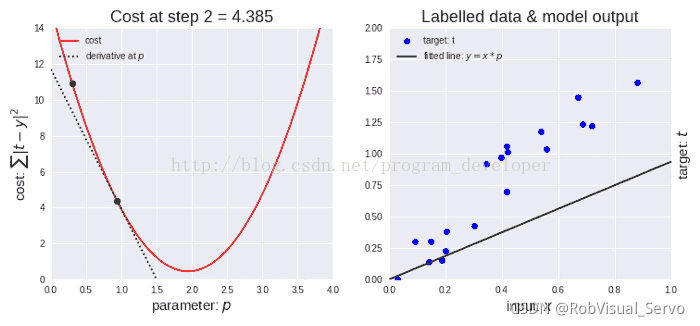
ЬнЖШЯТНЕжагавЛИіГЦЮЊбЇЯАТЪЕФВЮСПЁЃШчЩЯЭМзѓЫљЪОЃЌИеПЊЪМбЇЯАТЪНЯДѓЃЌвђДЫЯТНЕВНГЄИќДѓЁЃЫцзХЕуЕФЯТНЕЃЌбЇЯАТЪБфЕУдНРДдНаЁЃЌДгЖјЯТНЕВНГЄвВБфаЁЁЃЭЌЪБЃЌДњМлКЏЪ§вВдкМѕаЁЃЌЛђепЫЕДњМлдкМѕаЁЃЌгаЪБКђвВГЦЮЊЫ№ЪЇКЏЪ§ЛђепЫ№ЪЇЃЌСНепЪЧвЛбљЕФЁЃЃЈЫ№ЪЇ/ДњМлЕФМѕаЁЪЧвЛИіИХФюЃЉЁЃ
жЛгадкЪ§ОнКмХгДѓЕФЪБКђЃЈдкЛњЦїбЇЯАжаЃЌЪ§ОнвЛАуЧщПіЯТЖМЛсКмДѓЃЉЃЌЮвУЧВХашвЊЪЙгУepochsЃЌbatch sizeЃЌiterationетаЉЪѕгяЃЌдкетжжЧщПіЯТЃЌвЛДЮадНЋЪ§ОнЪфШыМЦЫуЛњЪЧВЛПЩФмЕФЁЃвђДЫЃЌЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧашвЊАбЪ§ОнЗжГЩаЁПщЃЌвЛПщвЛПщЕФДЋЕнИјМЦЫуЛњЃЌдкУПвЛВНЕФФЉЖЫИќаТЩёОЭјТчЕФШЈжиЃЌФтКЯИјЖЈЕФЪ§ОнЁЃ
epoch
ЕБвЛИіЭъећЕФЪ§ОнМЏЭЈЙ§СЫЩёОЭјТчвЛДЮВЂЧвЗЕЛиСЫвЛДЮЃЌетИіЙ§ГЬГЦЮЊвЛДЮepochЁЃШЛЖјЃЌЕБвЛИіepochЖдгкМЦЫуЛњЖјбдЬЋХгДѓЕФЪБКђЃЌОЭашвЊАбЫќЗжГЩЖрИіаЁПщЁЃ
ЮЊЪВУДвЊЪЙгУЖргквЛИіepoch?
дкЩёОЭјТчжаДЋЕнЭъећЕФЪ§ОнМЏвЛДЮЪЧВЛЙЛЕФЃЌЖјЧвЮвУЧашвЊНЋЭъећЕФЪ§ОнМЏдкЭЌбљЕФЩёОЭјТчжаДЋЕнЖрДЮЁЃЕЋЧыМЧзЁЃЌЮвУЧЪЙгУЕФЪЧгаЯоЕФЪ§ОнМЏЃЌВЂЧвЮвУЧЪЙгУвЛИіЕќДњЙ§ГЬМДЬнЖШЯТНЕРДгХЛЏбЇЯАЙ§ГЬЁЃШчЯТЭМЫљЪОЁЃвђДЫНіНіИќаТвЛДЮЛђепЫЕЪЙгУвЛИіepochЪЧВЛЙЛЕФЁЃ
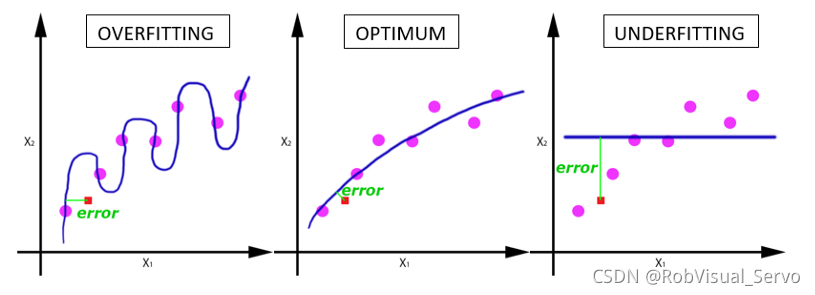
ЫцзХepochЪ§СПдіМгЃЌЩёОЭјТчжаЕФШЈжиЕФИќаТДЮЪ§вВдкдіМгЃЌЧњЯпДгЧЗФтКЯБфЕУЙ§ФтКЯЁЃ
ФЧУДЃЌЮЪЬтРДСЫЃЌМИИіepochВХЪЧКЯЪЪЕФФиЃП
ВЛавЕФЪЧЃЌетИіЮЪЬтВЂУЛгае§ШЗЕФД№АИЁЃЖдгкВЛЭЌЕФЪ§ОнМЏЃЌД№АИЪЧВЛвЛбљЕФЁЃЕЋЪЧЪ§ОнЕФЖрбљадЛсгАЯьКЯЪЪЕФepochЕФЪ§СПЁЃБШШчЃЌжЛгаКкЩЋЕФУЈЕФЪ§ОнМЏЃЌвдМАгаИїжжбеЩЋЕФУЈЕФЪ§ОнМЏЁЃ
Batch Size
batch sizeНЋОіЖЈЮвУЧвЛДЮбЕСЗЕФбљБОЪ§ФПЁЃзЂвтЃКbatch size КЭ number of batchesЪЧВЛЭЌЕФЁЃ
BatchЪЧЪВУДЃП
дкВЛФмНЋЪ§ОнвЛДЮадЭЈЙ§ЩёОЭјТчЕФЪБКђЃЌОЭашвЊНЋЪ§ОнМЏЗжГЩМИИіbatchЁЃ
Iteration
IterationЪЧbatchашвЊЭъГЩвЛИіepochЕФДЮЪ§ЁЃ
ОйИіР§згЃК
гавЛИі2000ИібЕСЗбљБОЕФЪ§ОнМЏЁЃНЋ2000ИібљБОЗжГЩДѓаЁЮЊ500ЕФbatch,ФЧУДЭъГЩвЛИіepochашвЊ4ИіiterationЁЃ
зЊздЃКhttps://blog.csdn.net/qq_37277944/article/details/82746635