���������ѧϰ������������ѧϰϵ���������漰�� Neural Network �� Backpropagation Algorithm �� Deep Learning �� Autoencoder ��
PCA �� Radial Basis Function Network �� K -
- ����ѧϰ�ʼ�-Neural Network
- ����ѧϰ�ʼ�-Deep Learning
- ����ѧϰ�ʼ�-Radial Basis Function Network
- ����ѧϰ�ʼ�-Matrix Factorization
Radial Basis Function Network
�ȴ�һ��֮ǰ���ܹ���ģ�� Gassian SVM ˵�𣬼���˵���ģ�;����� SVM �м����˸�˹�˺������Ӷ���������������ά�ȵĿռ��������ָ���ƽ�档��ģ�����յõ��ķ��������£�
���������յõ��Ľ�������� Gassian SVM ���Կ�����һЩ��˹������������ϣ���Щ��˹���������ĵ��� support vector ����Щ������ϵ�ϵ���� ��nyn ��
Radial basis function ָ��������Ҫ����ĺ����Ľ��ֻ�;��� (��x?xn��) �йأ�
Radial basis function �������������һ��ȡֵ������������ԭ������ʵֵ������Ҳ���� ��(x)=��(��x��) �����������ǵ�����һ�� c �ľ��룬
c ���Ϊ���ĵ㣬Ҳ���� ��(x,c)=��(��x?c��) ��
���Ǽ� gn(x)=ynexp(?����x?xn��2) �����ʽ�ӿ�������Ϊ������ x �����ĵ�
�����Ļ����ģ�;Ϳ�������Ϊ��һЩ��֧������ (support vector) �йصľ�������� (radial basis function) ��������� (linear aggregation) ��
��һƪҪ���ܵ� Radial basis function network(RBFNetwork) ����������ģ�͵����죺���ֻ��뾶 (��x?xn��) �йصĺ������Ӷ��õ��õ�ѧϰ�����
����� RBFNetwork �ļܹ��������� neural network �Ƿdz����Ƶģ������Ҳ�����Ϊ network ��ԭ������ͼ��
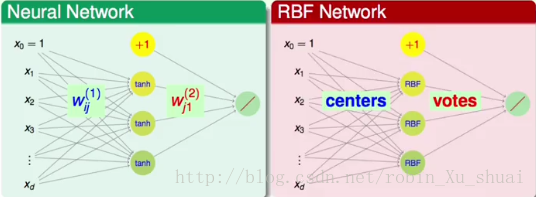
���Կ����� RBFNetwork ���м�һ�㣬���� neural network �ĸ��Ҳ���������У����� m ���ڵ㣬�ֱ��ʾ
RBF Network Hypothesis
�������ǿ���ʹ�������ʽ����������ͬ�� RBFNetwork ����ʽ��
���У� RBF(x,��m) �����Ǹ�˹�����������ľ���ĺ����� ��n �����ĵ������� ��m ��������ϵ�ϵ���� Output �ķ�ʽ��Ҫ����������ǻع黹�Ƿ���������������������ȽϹؼ������أ� һ����Ҫ�ο������ĵ� ��m ����Щ����һ����������ϵ�ϵ�� ��m ��ô��������������� Gaussian SVM ��˵�� RBF �Ǹ�˹����������Ҫ������Ƕ�Ԫ�������⣬���� Output ���õĺ����� sign �� M �Ĵ�С��֧�������ĸ�����
����һ�����˵�� RBFNetwork ��Ҫ�����ľ������ĵ� ��m ��������ϵ�ϵ�� ��m �������һ������������ RBF ������ѡ���Լ� Output �������ʽ��
��SVM with Gaussian Kernel�������ᵽ�� Kernel function �Ľ������˵������������ת������ά�ռ��еăȻ�����Ȼ�ǃȻ���˿�������Ϊ��һ�ֺ��������Եķ�������ԭ��������ά�ռ�������������ͨ��ת������ά�ռ����Ȼ��������� Poly ����������һ������ʽת����Ҳ����˵����������һ������ά�ռ��е������ԣ�ͬ����˹������������һ������ά�ռ��е������ԡ�
��������� RBF Ҳ��һ�������Եĺ�����������ֱ��ͨ���� X �ռ��еľ���������ģ������˹���������ǽ������ƽ��ȡ����Ȼ��
���� Kernel �� RBF ���Կ��������������Եĺ����������� Gaussian �������ַ�ʽ�Ľ�����
RBFNetwork ��������һ������Ҫ�������ǣ���������һ�ֺܺõĶ�������ת���ķ��������Ե�������������Եĺ����������� kernel �أ��� RBF �أ���ô�Ϳ���������Щ��������Ϊ����ת�������ѧϰ��Ч����
���µ��������������Կ����� RBF ��
- exp(?����x?����2)
- ?xTx?2xT��+��T��???????????????��
- ��x=����
RBF Network Learning
��һС�ڽ����� RBF �Ļ�������
����һ����Ҫ��������������ĵ� ��m ���ѡȡ��һ���Ľ�������ǽ�ÿһ�����ݶ����������ĵ㣬������ RBFNetwork ��Ϊ Full RBFNetwork ��
Full RBFNetwork��M=N (������)�� ��m=xm �������ķ�ʽ��������Ϊÿһ����֪�����ݶ�������δ֪���ݵ�Ԥ�⣬ֻ������Ԥ�����Ĺ���ȡ���ں�δ֪�����������Ի���˵���롣���磬���ڶ�����������˵�� ym��{ ?1,+1} �� full RBF network ���ɵķ��������£�
Nearest Neighbors
���ڲ�֪�������ѡȡ���ĵ�������е���������Ϊ���ģ���ʵ�������ķ�ʽ�ԼӸĽ����ܵõ���һ��ʮ�ֳ����Ļ���ѧϰ������ K -
��
������ uniform full RBF network ���� k nearest neighbors �����Կ�����ѵ����ֻ���������ݵĴ洢�����еĹ����������е���Ԥ��Ρ�
Interpolation by full RBF network
��������� full RBF network ����������������ϸ�˹�����IJ�����������Ϊ�� ym ���������Ƕ�����иĽ���ѧϰ�õ���ѵIJ��� ��m ���������ǵ�Ŀ����ʹ�� full RBF network ���� regression ��������ϣ���õ���ģ���ǣ�
Ҫ�����ѵ� ��m ����ʵ����Ҫ��ͨ�� RBF ����ת��֮������ݣ� zn={
RBF(xn,x1),RBF(xn,x2),?,RBF(xn,xN)},n=1,2,?.N ����һ�����Իع顣���Եõ����Իع����ѽ⣺
����
-
- Z ��һ��
N��N ���Գƾ��� (zi.j=RBF(xi,xj)=RBF(xj,xi)=zj,i) �� - �����е� xn ��ͬ��ʱ��ʹ����˹��������õ��� Z �����ǿ���ġ�
��Ϊ
Z �ǶԳƵģ� �ǿ���ģ������� ��=(ZTZ)?1ZTy=Z?1Z?1Zy=Z?1y������ʹ�� Gaussian ������Ϊ RBF ��ÿһ�����ݵ㶼��Ϊ���ĵ㣬�������ϲ��ظ��Ļ�����ô��ѵ� ��m �кܼĽ����� ��=Z?1y ��
�������Ǿ͵õ��� full Gaussian RBF network for regression ��ģ�ͣ����£�
gRBF=(��m=1NZ?1y exp��x?xm��2)��������������������ģ����ʲô�ر�֮���������ǰ�ѵ�����е�һ�������� xn ι����ģ�͵�ʱ���־�����ģ�ͼ���֮���õ��������� yn ֵ������ļ�������磺
gRBF(x1)=��Tz1=(Z?1y)T(first column of Z)=yTZ?1(first column of Z)=yT[1 0 ? 0]T=y1
���У� ZT=Z?(Z?1)T=Z?1��ZTZ=IҲ����˵ gRBF ��ѵ�����ϵĴ�����Ϊ 0 �������Ľ������һЩӦ�����纯���ƽ�
function approximation ��˵�������ģ���Ϊ������ϵĺ���ͨ����ÿһ����֪�������㣬���Ƕ��� machine learning ��˵����һ���õĽ������Ϊ������� overfitting �ķ��ա�Regularized full RBF network
�����Իع� linear regression �У�ͨ����������������ֹ����ϣ������������ linear regression ��Ϊ ridge regression ����ʱ��õ� regularized full RBFNet for regression ����ѵ� �� Ϊ��
��=(ZTZ+��I)?1ZTy(3)�� kernel ridge regressrion ����ѵ� �� Ϊ��
��=(K+��I)?1y(4)���Կ��� (3) �� (4) ʽ�dz����������Ϊ RBFNet �е� Z ��ʵ�͵��ڸ�˹�˾���
K ������������ԭ������ regularization �ķ�ʽ��ͬ���� kernel ridge regressrion �����������ά��ת���� regularization ���� regularized full RBFNet ���Ƕ�����ά�ȵ�ת���� regularization �����ϵ����۶��ǻ������е����϶��������ĵ�����������˵�������ܻ���� overfitting ��������Ҫ���� regularizer ����� SVM �� support vector �Ľ��������ʹ�����е����ݵ㶼��Ϊ���ĵ��ʱ���ܻ��и��õĽ�����ñȽ��ٵ����ĵ�Ҳ���Ե��������� regularization �� ��Ϊ�����Ļ��ڶ����Ȩ�ؾͱ����ˡ���һ�����ǽ�������δ����е����ݵ���ѡ������д����Ե����ݵ���Ϊ���ĵ㡣
k-Means Algorithm
��һС�����ǵ���ҪĿ������һЩ�д����Ե�������Ϊ RBFNetwork �����ĵ㣬�����ǽ����е������������� RBFNetwork �����ĵ㡣��Ϊ�� x1��x2 ��ʱ�����ǵľ���������������˼Ҳ�Dz��ģ������Ϳ�����һЩ�Ƚ��д����Ե����������������յ� RBF Network ������������Ԥ���ʱ�������е��Ӱ�졣���������Կ����� �ڽ���������Ĺ����У������Ƶ����˾����㷨 k -
Means ��������ѧ�ĽǶȻ���˵�����Ż��ĽǶ�������ʶ���������ʮ�����õ��㷨��������д����Ե���������������ת��Ϊ�������⣬��Ϊ�������ݾ������֮��ÿһ����ľ������ľ���������Ҫ�ҵ� RBF Network �о��д����Եĵ㡣
���ھ������⣬����ϣ��ÿһ�����е�������Ҫ�����ܵ����ƣ����� ��� x1,x2��Sm ����ô ��m��x1��x2 �������� ��m �� Sm �ľ������ģ�Ҳ����������Ҫ�ҵĴ����㣩ͬ������Ҳ���Զ���һ����ʧ�������£�
Ein(S1,?,SM;��1,?,��M)=1N��n=1N��m=1M[[xn��Sm]]��xn?��m��2(1)
������Ҫ Ein ��С�� ���У���� ? ������ [[?]]=1 ����� ? �������� [[?]]=0 �� N Ϊ�����ĸ�����M Ϊ����ĸ�����ֱ���Ͻ���1ʽ����Ҫ��С�����������㵽�������ĵ�ľ��롣һ��������Ҫ�ҵ���ѵ����ݾ��ʽ������һ��������Ż����⣻��һ����������Ҫ�ҵ���ѵ����ĵ�ѡȡ��ʽ������һ����ֵ���Ż����⡣Ҳ������Ҫ����������� { S1,?,Sm},{ ��1,?,��M} �����������Dz�ȡ���Ż���ʽ�ǽ��н�����Ż��� optimize alternatingly ���� ��1,?,��M �̶���ʱ��Ҳ���Ǿ��������Ѿ��̶������ˣ� ����ֻ��Ҫ���Ƕ���һ�������� xn ��˵����ξ�����������࣬����1ʽ�����õ�����ѡ��ʹ�� ��xn?��m�� ��С�� Sm ��Ҳ������ xn ����ľ����������ڵ�����Ϊ xn ���������ʱ Ein ��С��
��������һ�룬 ��ÿһ�������㶼����������������֮�������Ϳ��Ը���ÿһ���������.ͨ�����ǻ����������ݵ�ľ�ֵ��Ϊ�����µľ������ģ� Ϊʲô��ô���أ�
�� S1,?,Sm �̶���ʱ����С�� Ein ������ͱ������Ա��� �� ��һ����Լ�������Ż����⡣��Ȼ������ԥ����ȡ�ݶȣ�
����mEin=?(��Nn=1��Mm=1[[xn��Sm]]��xn?��m��2)?��m=?2��n=1N[[xn��Sm]](xn?��m)=?2(��xn��Smxn?|Sm|��m)���ݶ�Ϊ 0 ��ȡ��ѽ⡣
?2(��xn��Smxn?|Sm|��m)=0?��m=��xn��Smxn|Sm| �������Ǿ͵õ���һ���dz��������ලѧϰ�㷨�� k -
Means �����㷨�������̸�۸���һЩ��ͬ���ӽ�����������㷨��������k Means Algorithm
- �����������ѡ�� k �����ݵ���Ϊ��ʼ�ľ�������
-
repeate
- ��ÿһ���������������������ľ������ģ��Ӷ��õ�k����
- ��ȡÿһ�����еľ�ֵ��Ϊ�µľ�������
- until converge
Ϊʲô���㷨һ���������أ�Ҳ����˵Ϊʲô����һ�������ĵ���֮��{S_1, \cdots, S_m}��ڷ����仯���ȶ��أ���������ķ�������֪����ÿһ�����裬������ȷ�������Ļ������ݵ㣬 ����ȷ������ؾ����µľ������ģ���������С�� Ein ���� Ein ������Ϊ 0 �� ���Ը��㷨һ����������
RBF Network Using k-Means
����֮���Ի��Ƶ�
k - Means ����㷨����Ϊ��ȷ�� RBF Network �����ĵ㡣��� k -Means �õ��� RBFNetwork �㷨���£�RBF Network Using kMeans
- run kMeans with k=M to get { ��m}
- construct transform ��(x) from RBF at ��m:��(x)=[RBF(x,��1),RBF(x,��2),?,RBF(x,��M)]
- run linear model on { (?(xn),yn)} get ��
- return grbfNet(x)=LinearHypothesis(��,��(x))
����ʹ�� k -
Means �㷨���õ������� M �����ĵ㣬����������Щ���ĵ��Ͼ��������RBF ��������ת�� ��(x) ��ԭʼ���ݾ�������ת���õ��µ����� ��(x)=[RBF(x,��1),RBF(x,��2),?,RBF(x,��M)] �� ����Щ��������������ģ�ͣ� linear regression,logistic regression,linear SVM �ȵ������ �� ���õ����� RBF Network ���������ǵڶ��ο���ʹ�÷Ǽල��ѧϰ�㷨����ȡ�����е���������һ�������� autoencoder ��
�� RBF Network �еIJ�����Ҫ�� M �����ĵ�ĸ�����
RBF �еIJ������������ʹ�� Gaussian �Ļ���Ҫ�������е� �� ��k-Means and RBF Network in Action
k -
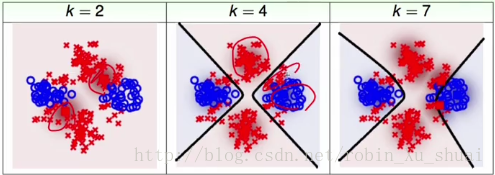
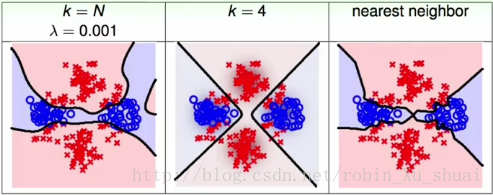
Means �㷨�Ľ���ܸ����IJ��� k �ͳ�ʼ���������趨��Ӱ�죬��Ϊ�����Ĺ�����ʹ�õķ�����alternating optimization ���Բ���һ���ᱣ֤�õ�ȫ�����ŵĽ⡣�����ͼ������һ������ RBFNetwork Using kMeans ������������ӣ�
����ͼ���Եõ��Ľ����ǣ� ��ʹ�� k -
Means �����ܹ��ҳ����������������ĵ����˵���ݵĴ�����ʱ����ô RBF Network �ڻ�������������ת��֮�»�õ����õĽ������ʹ�� full RBF network ��Ҳ���ǽ����е������㶼���������ĵ㣬��������ϵĶ���������ʱ���������ͼ���������ұߵ� kNN Ҳ��ʹ�����е���������Ϊ���ĵ㣬ֻ�����������ߵ�ʱ��ֻ���� k �������������
full RBF network �ϼ���������õ��˸���ƽ���ķ���߽硣������Ԥ���ʱ�� full RBF network ������ģ��Ҫ�������е����ϣ�������ʵ����ͨ�����Ǻܳ��á�
�ܽ�
��ƪ��Ҫ������ RBF network ����ģ����һЩ���ĵ� prototype �ϵľ�������� RBF ���ɣ���Щ������������Ը�˹�����ȵȣ���Щ���ĵ���������е�����������Dz��־��д����Ե������㡣��Ѱ�Ҿ��д����Ե����ĵ�Ĺ����У��Ƶ������ලѧϰ�㷨�� k -
Means �����㷨�����Ż����Ĺ����� alternating optimization �������ĵ㱻ѡȡ����֮���� RBF network ģ�;�ֻ��Ҫ�����е�ԭʼ���ݾ���������Щ���ĵ��Ͼ�������� RBF ���������ת���õ��������������һ�� linear model ��������ǿ����������㷨�ı��ִ������һ��ʼѡ������ĵ�����á� - Z ��һ��