0 - д��ǰ��
��ϵ�й���ƪ��Ϊ���������ѧϰ����ƪѧϰ�ʼǡ���Ҫ���ݿ����ܽ����Ϊ������ģ��ͨ�������Եı任���Եõ������Ե�ģ�ͣ���ǿ��ģ�Ͷ����ݵ�����������������������ڻ���ѧϰ������һ���ܳ��������⣬�������Ϊ�˽�����������������������(��������)����Ϊ�˽���������ӵ�ѡ��ģ�͵�ѡ���Լ���������ѡ������������� validation v a l i d a t i o n ����ط�����
- ����ѧϰ�ʼ�- Nonlinear Transformation N o n l i n e a r T r a n s f o r m a t i o n
- ����ѧϰ�ʼ�- Hazard of Overfitting H a z a r d o f O v e r f i t t i n g
- ����ѧϰ�ʼ�- Regularization R e g u l a r i z a t i o n
- ����ѧϰ�ʼ�- Validation V a l i d a t i o n
1 - Quadratic Hypothesis
֮ǰ���ܵ�ģ�������Եģ������е�������һ����Ȩ�͡���������Ҫ����Щ model m o d e l ����ɸ����ӵķ����� ʹ�������Եķ�ʽ�������ݵķ��ࡣ
���Է�������ģ���Dz��������Ժ��������Ҵ������Է����棬��ô�������Է�������
logistic regression l o g i s t i c r e g r e s s i o n ��������ģ�ͻ��Ƿ�����ģ�ͣ�
��������ģ�ͣ���Ϊ logistic regression l o g i s t i c r e g r e s s i o n �ľ��߽߱������Եġ�֤�����£�
�C֪��
���߿��Լ�����Ϊ��˹�ٻع��ǽ���ͨ������ģ�͵Ľ��ӳ�䵽һ��(0�� 1)�����䣬Ȼ��һ������(0.5)��
�C֪��
����ģ�͵ĸ��Ӷ����ܵ����Ƶģ���������ģ�͵ĺô�֮һ�� ��Ϊ��������ȷ�� Ein E i n (ѵ�������)�� Eout E o u t (���Լ����)�������̫Զ������ȱ����Ƕ���������ͼ�е������㣬��һ�����Է��������������Ļ��� �� �� �� ? ? ����ôͻ������ģ������������أ�Ҳ����˵�����Dz���������ʹ�á��ߡ��ķ�ʽ��������չһ��ʹ�������ķ�ʽ�����������������⣿
ֱ���������� ���µ�������Ȼ�������Կɷֵģ������ǡ�ԲȦ���ɷֵġ�Ҳ����˵��ʹ�ú����� hsep(x)=sign(?x21?x22+0.6) h s e p ( x ) = s i g n ( ? x 1 2 ? x 2 2 + 0.6 ) ʱ������ȷ�Ļ��� �� �� �� ? ? �����������һ����ԭ��Ϊ���� r2=0.6 r 2 = 0.6 ��Բ��
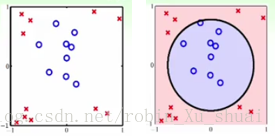
���ڵ�Ŀ����̽�����ϵͳ��������㷨ʹ��ԭ��������ģ�Ϳ������ڷ����Կɷֵ����ݵķ��ࡣ��Ϊ����֮ǰ�Ѿ�ѧ����һЩ��Է���ķ��������� PLA P L A �㷨�� pocket p o c k e t �㷨�� linear regression l i n e a r r e g r e s s i o n �㷨�� logistic regression l o g i s t i c r e g r e s s i o n �㷨����ο��Բ�������Щ�㷨��������Ӧ���ڷ����Կɷֵ����������ǹ��ĵ����⡣
�����ͼ���������ݣ�������ô���Եõ�һ����Բ���Σ���������һ����״�ķ������أ�
���������ǵõ��ķ��ຯ�� hsep(x) h s e p ( x ) ����һЩ���������¶����������
���������������������Ƿ������Ե�ģ������ʽ�ֳ����ˣ������ġ����������Ĺ�����ʵ�����ǽ����е� X X �ռ��еĵ�ͨ������ʽת�� ӳ�䵽��һ���µĿռ��У� ���dz�֮Ϊ Z Z �ռ�������
��ʽ�ӣ�1������������ Z Z �ռ��п���ͨ�����Ե�ģ��
��ȷ�Ļ��� �� �� �� ? ? ������ģ��������֮ǰѧ��������������Ե�����ͱ���� Z Z �ռ��п�������ģ�ͽ����������ֻ������������һ����ѡ�
�ڵõ��˺�
��ص�һ�����Է�����֮���ٶ�Ӧ�� X X �ռ䣬�͵õ���һ��������ȷ�Ļ���
�� ? ? ��Բ�εķ���߽硣�������ǾͿ���ʹ��һ����Բ����������һ�����ߡ������ݷ��࣬ ���������Բ����ʹ������ģ�������ġ�

�������Ǹ��������Ĺ��̣������ݴ� X X �ռ��� �ռ��Ĺ��̳�Ϊ����ת��( feature transform f e a t u r e t r a n s f o r m )�����Ե�����������ת��֮�����ǾͿ����� Z Z �ռ���ʹ��������Ϥ������ģ�� �� pocket p o c k e t �� linear regression l i n e a r r e g r e s s i o n �� logistic regression l o g i s t i c r e g r e s s i o n �������ݽ��з��ࡣ
(z0,z1,z2)=z=��(x)=(1,x21,x22) ( z 0 , z 1 , z 2 ) = z = �� ( x ) = ( 1 , x 1 2 , x 2 2 )
h(x)=h~(z)=sign(w~T��(x))=sign(w0~+w1~x21+w0~x22) h ( x ) = h ~ ( z ) = s i g n ( w ~ T �� ( x ) ) = s i g n ( w 0 ~ + w 1 ~ x 1 2 + w 0 ~ x 2 2 )
����� X X �ռ��п���ʹ�á�ԲȦ���������ݣ� �ھ�����ת��֮���� �ռ��о����Ի��֡����ǣ�1��ʽ���������ǵġ��������أ�����µ����Ͽ���ʹ��һ�����ֿ��� ��ôԭ��������һ������ʹ��Բ���ֿ���ͨ���±����Կ������� Z Z �ռ��еIJ�ͬ���ߣ���Ӧ�� �ռ�����Ǹ�ʽ������ͬ�����ߣ� ������Щ�߶�Ӧ����֮�����Ǿ�֪���� X X �ռ��������Щ����������ͬ�ķ������� �п�������Բ����Բ��˫���ߵȵȣ�
���Կ���ʹ�����������ת���õ��� X X �ռ��еĶ������߷������������Ƶģ�Բ����ԭ�� ����һ�������Ҫ�õ� X X �ռ������еĶ������߷��������Ǿ���Ҫ���¶������������һ�������ת���� ���õ��µ� Z Z �ռ䣨6ά���� �ռ��е�ÿһ��ֱ�ߣ���Ӧԭ���ռ��е�һ�����ε����ߣ�ԭ�� X X �ռ��е�����������ߣ�Ҳ��Ӧ�� �ռ��е�һ��ֱ�ߡ�
���������������˶����ݽ��з�����µ�˼·�������µļ��輯���Ȱ�ԭʼ�����ݣ������Ƕ�ά�ģ�ͨ��ij������ת�������� ��2(x) �� 2 ( x ) �� ���� 2 2 ��ʾ����ת����ӳ�䵽 �ռ䣬 �� Z Z �ռ���ʹ��ij�����Ե�ģ�͵õ����Եķ����� �� �����Ϳ��Եõ��� X X �ռ���������״�Ķ��η�������
�ٸ����ӣ�
������ X X �ռ�����Ҫһ�����µġ�б��Բ��������ȷ�Ļ������ݣ�
��
���ڿ����Dz��ǿ���ʹ�� 6 6 ά��
�ռ� (1,x1,x2,x1x2,x21,x22) ( 1 , x 1 , x 2 , x 1 x 2 , x 1 2 , x 2 2 ) �е�һ��ֱ��������������������Եõ����Ӧ�� Z Z �ռ��е�ֱ�ߵIJ���Ϊ
������ Z Z �ռ��е�ÿһ���ߣ�����������ʵ��ijһ����
�ռ��ж�Ӧ�ķ��ʽ��
��һС�ڵ�˼����ʵ���ѣ���֪��Ϊʲô����˵���ȴ���ú��ѡ��ܽ��£�Ϊ�˵õ������ӵķ�������������ֻ�����Եģ�����Ҫ���ľ��ǽ�������ת������Ҫ�õ������ӵķ������ͽ��и����ӵ�����ת������ת����ĸ�ά�ռ���ʹ������ģ�Ͷ�ת������������з��࣬ �Ϳ��Եõ���Ӧ��ԭʼ�Ŀռ���������״�ķ�������
2 - Nonlinear Transform
���������Ѿ��õ������Ͻ��н�����6ά������ת���£� Z Z �ռ䣨
ά���е����е�ֱ�߿��Զ�Ӧ�� X X �ռ䣨
ά���е����еĶ������ߡ��������X�Ƕ�ά�ռ䣬 Z����ά�Ŀռ䣩����������� Z Z �ռ��п����ҵ�һ���õķָ��ߣ���ô�Ͷ�Ӧ����
�ռ��е�һ���õĶ������ߡ���ν�õķָ��߾���ָ�ܹ���ȷ���� �� �� �� ? ? ���ߡ�
�����������ڵ��������� Z Z �ռ����ҵ�һ���õġ��ߡ���Ŀǰ���ǻ���������
�ռ���ʹ����֪������ {
(xn,yn)} { ( x n , y n ) } �õ�һ���õķָ��ߣ���������ֻҪ�� X X �ռ��е�����ͨ��ij������ת���� ���磬
ӳ�䵽 Z Z �ռ䣬 �����Ϳ���ʹ���κε����ԵĶ�Ԫ�������
�ռ�ʹ������ {
(zn=��2(xn),yn)} { ( z n = �� 2 ( x n ) , y n ) } ����һ���õķָ��ߡ�
2.1 - ������ת���Ļ�������
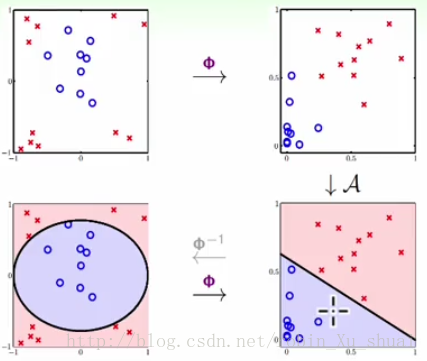
- �� X X �ռ��е�����ͨ��ijһ��ת�� ӳ�䵽 Z���� Z �� �� ����ά�ռ䣩��������ͼ ? ? ����ͼ��
- �� Z Z �ռ����������� ʹ���κ����Է�����㷨 A A �õ�һ���õķ����� ��������ͼ ? ? ����ͼ��
- �õ������� g(x)=sign(w~T ��(x)) g ( x ) = s i g n ( w ~ T �� ( x ) ) ����һ�� X X �ռ��е��µ����ݵ�Ҫȷ������ʱ��ͬ���ȶԸ����ݵ�ʹ�ñ任 ӳ���� Z Z �ռ䣬�� �ռ��еõ�����Ľ����������ͼ ? ? ����ͼ��
2.2 - ������ģ��
�����Ե�ת�� + ���Ե�ģ�� = �����Ե�ģ����
�����Ե�ģ����Ҫ���ǵ��������⣺
- ʹ��ʲô��������ת��������˵ת����ʲô���� Z Z �ռ��У�
- ʹ��ʲô��������ģ�ͣ�����˵��ʹ��ʲô�㷨��
���Ե� �㷨�� pocket p o c k e t �㷨�� linear regression l i n e a r r e g r e s s i o n ������ logistic regression l o g i s t i c r e g r e s s i o n �㷨���һ�����ε�����ת�����Ϳ��Եõ����ε� PLA P L A �㷨�� ���ε� pocket p o c k e t �㷨�����ε� linear regression l i n e a r r e g r e s s i o n �����Ƕ��ε� logistic regression l o g i s t i c r e g r e s s i o n �㷨����������ε�����ת�����������ε� PLA P L A �㷨�� �� �� ��Ҳ����˵ֻ�ǻ�һ���ռ��� linear learning l i n e a r l e a r n i n g ��
2.3 - һ��������ģ�͵�ʵ��

�ڻ���ѧϰ������һ��������Ҳ�Ǻܻ�����Ӧ�þ�����д���ֵ�ʶ�����������ǿ���һ�ֱȽ�ԭʼ�ķ������������� 1 1 ������һ������������⣺����һ�����֣��ж���
���߲��� 1 1 ��
����ѧϰ��
��Ϊ���֣� һ���� concrete c o n c r e t e �ģ����кܷḻ���������壻һ���� raw r a w ����ԭʼ�ռ��������ݡ����� raw r a w ���͵����ϣ�����ʹ��רҵ��֪ʶ��Ϊ concrete c o n c r e t e ������������ϵ����⣬�����ռ��������������ؼ���ģ� ��ÿһ����д����ʹ��һ��32 �� �� 32�����ؾ����ʾ���� raw r a w ���͵ģ������ǿ���ͨ�����������ʶ�� domain knowledge d o m a i n k n o w l e d g e ��������ȡ������������������������ǿ��Կ����Գ��Ժ��ܶ�����Ϊ���� 1 1 �DZȽ��Գ��ģ�����
�������ܶ��DZȽϵ͵ġ��������Ǿͽ�ԭ����32 �� �� 32ά������ת��Ϊ��2ά�������� ���������������� �� �� �� �� �� �� �� �� �� ��Ͷ�Ӧ��һ������ת�� �� �� �� ������ͼ ? ? ����ͼ�������������, ÿһ��ͼƬ��Ϊ�˶�ά�ռ��е�һ���㡣��ʱ���������� concrete c o n c r e t e ���͵ġ�ԭ����32 �� �� 32ά����������ͨ��ת�� �� �� ��Ϊ2ά�ģ� ���Կ���ʹ�����Ե��㷨���з��ࡣ������ͼ ? ? ����ͼ������ô���ڲ��Լ��е����ݣ�����ͼ����ͬ����������ȡ���ǵ����������� ������������ �� �� �� �� �� �� ����������ά�ȵĿռ��н��з��ࡣ

2.4 - A question
���ڼ���X�ռ���������ά�Ȳ����� 2 2 �� ���� ��������X�ռ���������ת�� ��2 �� 2 ����ôת�����Z�ռ���ά���Ƕ��٣�
- ������ĸ����� Cd2+d C 2 d + d
- һ����ĸ����� d d
- ������ĸ�����
Z Z �ռ��ά���ǣ� ��
3 - Price of Nonlinear Transform
3.1 - Computation or Storage Price
���������ᵽ�����⣬ԭʼ�� X X �ռ���������ά����
���������Ҫ�� Q Q -�εĶ���ʽת��
�� ��ôת��֮��Ŀռ��ά�ȿ��Ա�ʾ���£�
�� d d ���������ҳ����е��� �ε���ϣ������ظ������� Z Z �ռ��ά���� ������ԭʼ�� X X �ռ��е�ά��Ϊ2������ת��Ϊ �� ������һ�� 50 50 �ζ���ʽ������ת������ô����������Եõ��µ� Z Z �ռ�Ĵ�С��1325ά�ġ������оʹ�����һ����Ҫ�����⣬���������������֧�����1000��ά�Ŀռ䣬 ��2ά�Ŀռ��У�����20���������ˣ� ������һ��1000ά�Ŀռ��У�20�������ǿ϶������ġ�
����Ҫ�����ܴ�Ĵ��� ��
- ��������ת���ļ������Ƿdz��Ӵ�ġ�ÿһ��������Ҫ�� d d άת��Ϊ ά��
- ��ʹ�����Ե�ģ����� w w ��ʱ�� ������ d d �������� �����������磬 linear regression l i n e a r r e g r e s s i o n �еĽ�������Ҫ��� (1+d~)��(1+d~) ( 1 + d ~ ) �� ( 1 + d ~ ) ά�ľ����α�����
- ��������Ҫ 1+d~ 1 + d ~ �Ŀռ�������� d d ��
3.2 - Overfitting
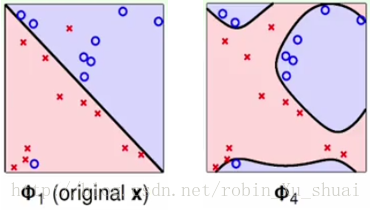
����ͼ�ֱ���ʹ��ԭʼ�����ݣ����� ת�����;�������ת����ʹ�� ��4 �� 4 ת�����Ĵζ���ʽ�������������з���Ľ������Ȼ��ͼ�� Ein(g)=0 E i n ( g ) = 0 ������ѵ�����ϵ����Ϊ0�� ����������Ϊ��ߵĻ����Ǹ��õġ�
����ѧϰ���ĵ���������������
�ܲ���ȷ�� Eout(g) E o u t ( g ) �� Ein(g) E i n ( g ) �㹻�Ľӽ���Ҫ��ģ���㹻��
�ܲ�������ʹ�� Ein(g) E i n ( g ) �㹻С��Ҫ��ģ���㹻���ӣ�
��ʹ�ò�ͬ�ļ��躯���C��2�εģ�����4�εģ�����������������IJ����Dz�һ���ġ�����������ת����ʱ����� Q Q �ܴ�ʹ�÷dz����ӵ�����ת������ʱ����2�ܹ��ܺõĽ������������1���ܵõ���֤����� ��С����ʹ�úܼ�����ת������ֱ��ʹ��ԭʼ������������ learning l e a r n i n g ����ʱ����1�ܹ��ܺõĽ������������2���ܵõ���֤������ machine learning m a c h i n e l e a r n i n g ������Ҫ��һ�� tradeoff t r a d e o f f ��
�����������ˣ� ���ѡ����ʵ�����ת�� �� �� ��
4 - Structured Hypothesis Sets
4.1 - Polynomial Transform
�Զ���ʽ�����任��һ�����ݹ顱�Ķ��壺
���·ֱ�������� 0 0 ά�ı任��
ά�ı任��
����
Q Q �ζ���ʽ�任 = �� �ζ���ʽ�任 + ���е� Q Q ��ʽ����
���Կ��Եõ����µĹ�ϵ�� ����
��ʾ���� Hypothesis set H y p o t h e s i s s e t �����Լ�����Ϊ���õ�ģ�ͣ��� ��һ���任�ļ��輯����ǰһ���任�ļ��輯�������ӵ����ϵ������Ϊ0���ɣ���
���Եõ����µ� Hypothesis set structure H y p o t h e s i s s e t s t r u c t u r e
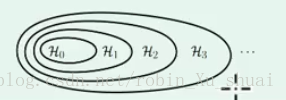
��һ���ķ������Եõ���
�� hypothesis h y p o t h e s i s ����ʱ��ѡ�����ˣ� ����Щ���ӵ�ѡ���У����ܻ��ҵ�һ�� hypothesis h y p o t h e s i s �и�С�� Ein E i n ������ Ein E i n �ͻ��½����������û���ҵ����õģ�����������ԭ������һ���ġ����� Ein E i n Ӧ���ǻ�һֱ�½��ġ�
����������������ʽ�õ�����ѧϰ��һ������Ҫ��ͼ��
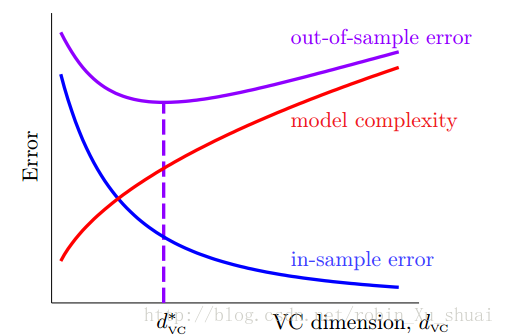
�������ͼ���Կ����� Ein E i n ���� Hypothesis Set H y p o t h e s i s S e t �ĸ��Ӷȵ���߶��½�������ģ�͵ĸ��ӶȻ���֮��������������ĵ� Eout E o u t ���½�������������ʹ��һ����ά�ȵı任������ʹ�� Ein E i n ��С������ Eout E o u t ȴ��ܸߣ� ��Ϊģ�͵ĸ��Ӷ�̫���ˡ���ѵ������������ü�ģ�ͣ� ������ʱ�� Ein E i n �Ѿ���С�ˣ� ��ô�Ϳ��Խ����ģ����Ϊ���յ�ģ�ͣ�����Ļ��� �����ý�Ϊ���ӵ�����ת����
5 - Summary
��ƪ�����˷����Ա任�����̣�ʹ��ԭ����Ե����Ե��㷨����Ӧ�õ������Կɷֵ����Ρ���Ҫ�������������ͨ��һ������ת�� �� �� ����ά�ռ䣨ԭ���� X X �ռ䣩�е�����ת������ά�ռ� �У��� Z Z �ռ���ʹ�����Եķ����㷨���ɡ���Ȼ�⿴�����dz��� �� ����ʵ������Ҫ����ģ���ӶȵĴ��۵ġ����������ȫ���������ǣ���ʹ�ü�ģ�͡�