����Ŀ¼
- 0. ժҪ
- 1. ����
-
- ģ�ͼܹ�
- 2. �ල��EQA
-
- 2.1 �ı��ʹ�����
- 2.2 ��������
-
- �����������
- �������ת��
- 2.3 �ʴ�
-
- ѵ��һ��������QAϵͳ��
- ʹ�ú�����ʣ�
- 2.4 �ල�������ת��
-
- �����������
- ��Ȼ��������
- `Wh*`������ʽ��
- 3. ʵ��
-
- 3.1 �ලQAʵ��
- 3.2�����о��ͷ���
- 3.3 �������
- 3.4 UNMT-�����������
- 3.5 С�����ʴ�
- 4. ��ع���
- 5.����
- 6.�ܽ�
Facebook AI Research������ACL2019
���ĵ�ַ��https://arxiv.org/abs/1906.04980
���Ĵ��룺https://github.com/facebookresearch/UnsupervisedQA
0. ժҪ
����һƪ���ල���������ɵ����¡�����������о�˼·�ǣ�(1)�����ල���������ı�����(context)������(question)����(answer)��Ԫ�顣(2)����������Ԫ���Զ��ϳɳ�ȡʽ�ʴ��ѵ���������У��ල���������ı����ݵIJ������£�
- �Ӵ����ĵ������ѡȡ����(context paragraphs)
- �ٴӶ����������ѡ�����ʶ���(nou phrases)������ʵ����Ϊ��
- �������еĴ�תΪ���������ʽ��cloze questions
- �ٽ�cloze questionsתΪ��Ȼ��������
����������Ա��˶�����������ʾ䵽��Ȼ�����ʾ�ת�����ල���������а���(1)������Ȼ�ʾ�Ƕ������Ϻ���������ʾ���ල��������ģ��(2)���ڹ���ķ�����ͨ��ʵ�鷢�֣��ִ���QAģ���ڱ��ĺϳɵ����ݼ���ѵ��֮��Ȼ���Իش���Ȼ���Է�ʽ�����⡣����֤���ˣ���ʹ��ʹ���κε�SQuAD���ݼ������ĵķ���Ҳ�ܹ����ִ�ģ����SQuADv1��ȡ��56.4 F1�����ڴ�������ʵ�����͵����ݼ�(��������SQuADv1���Ӽ�����𰸶�������ʵ��)����Ի�ȡ���ߵ�64.5 F1���ⳬ�������ڵļලʽѧϰģ�͡�
1. ����
EQA��Extractive Question Answering����ȡʽ�ʴ��ڸ������ĵ��С����ڵ��͵�benchmark���ݼ�SQuAD (Rajpurkar et al., 2016), ��ǰ��ģ���Ѿ�����������������ܣ����� SQuAD 2.0 (Rajpurkar et al.,2018)�� funetuning BERT Ҳ����ƥ����������ܡ���������Natural Questions���Ͽ� (Kwiatkowski et al., 2019), Ҳ��ӽ����������ܡ�Ȼ����Щģ����Ҫ������ѵ�����ݡ�������������µ����������ռ�������ѵ��������Ҫ�ķѾ�����������ġ���ô���û�п��õ�ѵ�������ָ���ô���أ�
û�ж���������ġ����⡢�𰸵�ʱ����ƪ����ʹ���ල��EQA������������⡣���Ľ�EQAתΪ�ල���������ɣ������һ������������Ҫʹ�üලQA�����ܹ��ڸ����ĵ�������ȷ�����⣬��ô�Ϳ����������ɵ�����ѵ��һ��QAϵͳ�������������ֱ������QA��������½�չ�������µ�ģ�Ϳ�ܺ�Ԥѵ������������������кܴ������ԺͿ���չ�ԡ�����������ķ���Ҳ�ܹ������ڰ�ල��ѵ�����ݵ���ǿ��
ģ�ͼܹ�
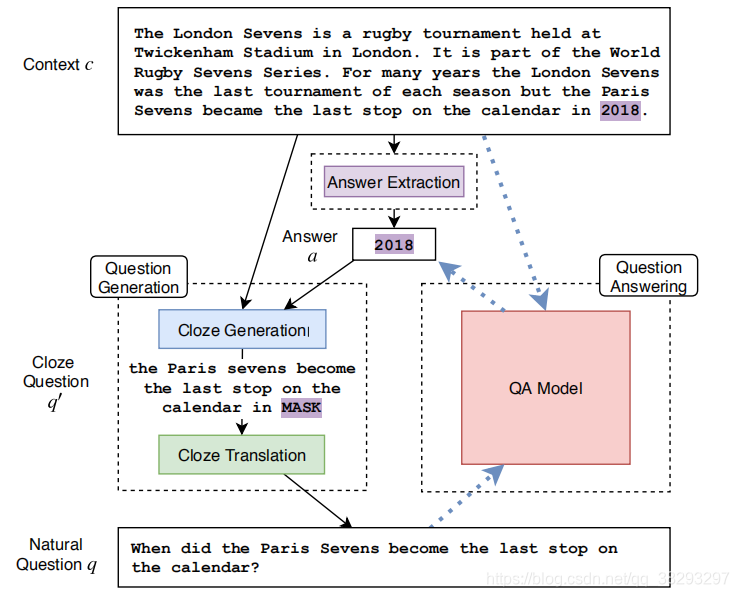
ͼ1�����ǵķ���ʾ��ͼ�� �Ҳࣨ����ͷ��������ͳ��EQA�� ���ǽ������ල�������ɣ���࣬ʵ�ļ�ͷ��������ѵ����EQAģ�͡�
ģ����������ͼһ��ʾ������EQAѵ������3�����裺
(1) ��Ŀ������(���籾����Ӣ�ĵ�Wikipedia)������һ������
(2) ʹ��Ԥѵ���ķ����������NER��������ʶ����ʶ������������еĺ�ѡ�𰸣���ɺ�ѡ�𰸼�������ʹ�õ������������Ȼ�Ǽලʽ�ģ�����û���õ�����(question��answer)��(question��context)�Ķ������ݡ��ܽ���ǣ��Ӻ�ѡ�𰸺�ԭʼ��������������������⡣
(3) �������ල�������������-��Ȼ�ʾ�ת�������������������������תΪ��Ȼ�ʾ���
���У������������������ս�Ե��� �����������תΪ��Ȼ�ʾ� �����Ի��ڸ��ӵĹ���(Heilman and Smith, 2010)��ɳ����䵽�ľߵ�ת��(������Ӣ��)��������QAϵͳ�ϵ����ܱ���Ҳ����������Ҫ�������������������ʱ����Ҫ�����Ĺ���ʦ�������������Ƶ��㷨���÷����ض���̫ǿ������������������תΪ��Ȼ�ʾ��������������ලʽ����(Du et al. 2017; Du and Cardie 2018; Hosking and Riedel 2019, inter alia)����������Ҫ�˹���ע������Բ��������Ķ��ڸ�����Ľ������Դ���ල�������� (Lample et al., 2018, 2017; Lample and Conneau, 2019; Artetxe et al., 2018)�����У�������Ҫ�ռ���������Ȼ������ʽ���ʾ����Ϻ�δ����ĵ����������������������������back-translation��de-noising auto-encoding����ѵ��һ��seq2seqģ����ʵ����Ȼ�ʾ�������������֮���ӳ�䡣
ʵ�鷢�֣�����ʹ�õ����Ƚ���QAģ�Ϳ�ܣ�����������ලQA�ܹ�ȡ�ñ����ڼල����(Rajpurkar et al., 2016)���õĽ����ʵ�鷢��ͨ���ʵ��Ƴ��ͷ�ת��������(����Ȼ��)��������������Ȼ��ڹ���ķ������ܸ��á����ල��seq2seqģ�������ƴʻ�ת�ʵ����������ͺͻ��ڹ����ϵͳ���ָ��á�ʵ���л�֤�����ĵķ����ܹ�����С����ѧϰ������ֻ��32����ע����F1ֵ�Ϳ���ȡ��59.3������ʹ�ñ��ķ���F1ֵֻ��Ϊ40.0��
�ܽ�һ�£����������¹��ף�
(1) �״����ලQA�����������������ලQA����תΪ�ල��������ձ任��������ʹ�õĹؼ��������ල�������롣
(2)�㷺��ʵ����֤���������������ת���㷨�ͼ���
(3)ͨ��ʵ��֤�����ķ�����EQA�е�С����ѧϰ����Ч�ԡ�
2. �ල��EQA
���Ż���ȡʽ�ʴ𣺸�������qqq���ı�ccc����Ҫ�ṩһ����a=(b,e)a=(b,e)a=(b,e)������bbb����ʼλ�ã�eee�ǽ���λ�á�ͼ1���Ұ벿����������̵�ͼʾ��
��������˽�������������εİ취��
- ���ȣ���ʹ���κ�QA�ල���һ������ʽģ��p(q,a,c)p(q,a,c)p(q,a,c)
- Ȼ��ʹ��ppp��Ϊ������ѵ��һ���б�ģ��pr(a�Oq,c)p_r(a|q,c)pr?(a�Oq,c)��������p(q,a,c)=p(c)p(a�Oc)p(q�Oa,c)p(q,a,c)=p(c)p(a|c)p(q|a,c)p(q,a,c)=p(c)p(a�Oc)p(q�Oa,c)����һ���������ʽ�������ݡ���ͨ��p(c)p(c)p(c)����һ���ı�����ͨ��p(a�Oc)p(a�Oc)p(a�Oc)�����ı���Χ�ڵĴ𰸣����ͨ��p(q�Oa,c)p(q | a, c)p(q�Oa,c)�õ��ô𰸺��ı�����Ӧ�����⡣
2.1 �ı��ʹ�����
�Ը������ĵ����ϣ������ı�����ģ��p(c)p(c)p(c)���о��Ȳ�����һ�����Ⱥ��ʵĶ���ccc��ͨ��p(a�Oc)p(a�Oc)p(a�Oc)���ɴ𰸣�������������ʲô�Ǻô𰸵�������ʡ������p(a�Oc)p(a�Oc)p(a�Oc)���2���ı��壺
���ʶ��Noun Phrases����
�ڶ���ccc�г�ȡ�����е����ʶ��������������о��Ȳ���������һ�����ܵĴ𰸡�����Ҫ�鴦���㷨(chunking algorithm)��
����ʵ�壨Named Entities����
���ǿ��Խ�һ�����ƺ�ѡ��Ϊ����ʵ����Ϊ�ˣ���Ҫ����NERϵͳ��ȡ��ȫ��������ʵ���ἰ���پ��Ȳ���������Ҳ����������Ķ����ԡ�����Ч�Բμ�3.2�ڡ�
2.2 ��������
����˵��QAϵͳ�к�����ս������ʹ�֮��Ĺ�ϵ��ģ�����������������ģ��p(q�Oa,c)p(q�Oa,c)p(q�Oa,c)�б��������ǽ���һ����Ϊ2�����裺
- ����������ɣ�q��=cloze(a,c)q��=cloze(a,c)q��=cloze(a,c)
- ����ת����p(q�Oq��)p(q�Oq��)p(q�Oq��)
�����������
�����������(Cloze questions)�ǽ����ڱεij����䡣
��1����һ���뷨�Ǹ��ݴ�ѡ�ô���Χ�ľ��ӣ���������뷨�Ľ��Ϊ��
"For many years the London Sevens was the last tour nament of each season but the Paris Sevens became the last stop on the calendar in ___"��
��2���������ͨ�����ƴ���Χ�������Խ�һ�����ͳ��ȡ����Խ�����������ӽ�һ������Ϊ"the Paris Sevens became the last stop on the calendar in ___"��
�������ת��
�����������������q��q��q�����Խ�һ��תΪ��������ʵQA�������ʽ����������̽��4�ַ���:
���ӳ�䣨Identity Mapping��
������Ϊ����������Ȿ���ṩ���ܹ�ѧϰQA��Ϊ����Ϣ��Ϊ����֤������裬���IJ���Identity Mapping��Ϊ�������ת����baseline��Ϊ�ܹ�����"questions"(����ʵQA������ʹ����ͬ�ʵ�)����wh*����(���ѡ��������ʽ���μ�2.4��)�滻���ڱε�token��
���������������(Noisy Clozes)��
������������������Ȼ����֮��������һ�ַ����ǰ����ֲ����Ϊһ�ָ�����ʽ��Ϊ�������Ŷ���³���ԣ����������������������������������������£�
- ɾ�������������q��q��q���б��ڱε�token��
- �ٶ���ʹ��һ������������
(Lample et al. (2018)����ͷ������һ��wh*����(���ѡ��������ʽ���μ�2.4��)����ĩβ����һ������mark��
��������������word dropout��������Ϻʹ��ڱ�������������ɡ���˿���(���ٶ���SQuAD)��ѧϰһ��������ʶ����������n-gram�ص��Ĵ�Ƭ�Σ��ҶԴ�����Ŷ�����һ�����ݴ�������
���ڹ���(Rule-Based)��
�������еĴ�Ƕ�뵽һ��(q,a)(q,a)(q,a)���п��Ա�����Ϊһ�ִ���wh-�ƶ���wh-�� ��������ѡ���ľ䷨ת��������Ӣ�ģ����е������Ѿ�֧�ָù��ܣ�����ʹ��Heilman and Smith (2010)����ij�����-�ʾ� ����������������ʹ��һϵ�еĹ������ɺ�ѡ�ʾ䣬��ʹ��һ������ϵͳѡ����ѽ����
�������(Seq2Seq)
��������Ҫô��Ҫ��Ĺ�����������֪ʶ(���ڹ���)��Ҫô���ɽ������Ȼ������Ȼ���ϴ�**(identity mapping, noisy clozes)**������ͨ��һ���ල��seq2seqģ�ͽ������2�����⡣��seq2seqģ���ܹ�ʵ����������������Ȼ����֮���ת��������ϸ�ڲμ�2.4�ڡ�
2.3 �ʴ�
ͨ������ģ�͵õ���ȡʽ�ʴ�Ĵ𰸣�����������2�ַ�����
ѵ��һ��������QAϵͳ��
���������������У����ڿ��õ��κ�QA����У�ѵ�����������ڱ��������������ɡ����ǣ����������ɵ����ݲ�̫���ܴﵽ��ʵQA���ݼ�������������ϣ��QAģ���ܹ�ѧϰ��������QA��Ϊ��
ʹ�ú�����ʣ�
��һ����ȡ��aaa�ķ����������������p(a�Oc,q)p(a�Oc,q)p(a�Oc,q)�������ڸ����ı���ǰ���£��𰸸���=p(a�Oc)=p(a�Oc)=p(a�Oc)����ȼ��ڼ���arg?max?a��p(q�Oa��,c)\arg \max _{a^{\prime}} p\left(q | a^{\prime}, c\right)argmaxa��?p(q�Oa��,c)��ͨ������ÿ����ѡ�����ɸ�����ĸ��ʼ��ɡ��÷�����Lewis and Fan (2019)�еļල�������ơ�
2.4 �ල�������ת��
Ϊ��ѵ��һ��seq2seqģ����ʵ���������ת�����������ල��������(NMT)�����еĽ��ڳɹ�����Щ�����ĺ�����û��ƽ�����ϵ�Դ���ݺ�Ŀ�����Եľ��ӡ���Щ�����У�Դ���Ӳ������κε�Ŀ�����Եķ�����ӣ���֮��Ȼ������أ��ڱ��ĵ������ϣ�����������ѧϰһ���ܹ�ӳ����Ȼ����(target)�������������(source)�ĺ�����������ƽ�����������Ľ���Ҫ�����������������CCC����Ȼ����QQQ��
�����������
�����������CCC�Ĵ���������2.2���еķ�������Wikipedia �������������5M������������⣬������ÿ����Ƭ�κ�������ձ߽紴��һ������CCC�������ڴ�ʵ��������Ϣ(��. NE��ǩ)����ʹ���ض����͵�mask���ڱ�token���Ա�ʾ5�ָ��Ĵ����͡�����5��mask�����ִ����͡�����ϸ�ڲο�����A.1��
��Ȼ��������
������Ȼ������ռ������Ǵ�Ӣ����ҳ����ȡ��á�����QQQ���Ǵ����ٲ�������5M�ʾ䣬����ÿ����wh*��ͷ���ʾ���������ȵġ�
��Lample et al. (2018)һ����ʹ��CCC��QQQѵ���任ģ��ps��t(q�Oq��)p_{s \rightarrow t}\left(q | q^{\prime}\right)ps��t?(q�Oq��)��pt��s(q��Oq)p_{t \rightarrow s}\left(q^{\prime}|q \right)pt��s?(q���Oq)������ģ�͵�ѵ������ʹ����denoising autoencoding������ѵ����online-backtranslation�Ŀ���ѵ������һ���̶���Ҳ������Ϊһ�ַ��ת��������Subra- manian et al. (2018)���ơ����ƶϽΣ���Ȼ�ʾ�ͨ��arg?max?qps��t(q�Oq��)\arg \max _{q} p_{s \rightarrow t}\left(q | q^{\prime}\right)argmaxq?ps��t?(q�Oq��)���ɡ������ʵ��ϸ�ڲο�����A.2��
Wh*������ʽ��
Ϊ"identity mapping"��"noisy cloze"�������������ṩ���ʵ�wh*���ʣ���������һ�ּ�����ʽ�����Խ�ÿ��������ӳ�䵽����ʵ�wh*���ʡ����磬������ΪTEMPORAL��ӳ��Ϊwhen��ʵ������У������ල��������ı任������ʱ���ӳ���������������ӳ�䵽���ʵ���wh*���ʣ�����Ҳ����wh*����ʽ�����������ʾ���������������ģ�ͣ���ѵ���ڼ��������ʽ��Ŀ���ʾ��ͷ������wh*��ӳ��Ĵ����������磬�ʾ���when��ʼ������ͷ������"TEMPORAL"������ϸ�ڲο�����A.3��
3. ʵ��
- ̽��QAϵͳ��û��ʹ��(q,a)(q,a)(q,a)������ʱ�����ܱ���
- ���ķ����������ල�����ĶԱ�
- ���ķ�������������Ҫѵ�������ල�����ĶԱ�
- ��ͬ��Ʋ��Զ�QAϵͳ���ܵ�Ӱ��
- ��֤���ķ����Ƿ��ܹ�Ӧ����С����ѧϰ
- �����ල��NMT�Ƿ������Ϊ�����������Ч����
3.1 �ලQAʵ��
���ںϳɵ����ݼ������Dz�������2��QAģ�ͽ���ѵ����finetuning BERT��BiDAF+Self Attention��������������ʷ����Ӿ��Ӽ���Ӿ��г�ȡ������������⣬��ʹ����������NMT��������p(q�Oc,a)p(q�Oc,a)p(q�Oc,a)������ָ�꣬ʹ�õ��DZ�����ȫƥ��(EM)��F1ֵ��
�ලѵ�����̣����ڼ�������ȡ��dev set������QAģ��ѵ����ֹͣ������QAϵͳ������ָ���ںϳɵ������е��������ݼ����ȶ����������⣬������SQuAD�е�dev set������ģ�����ĸ���ɳɷָ�Ϊ��Ҫ(�μ�3.2��)��Ϊ����SQuAD �������ݵ������ԣ�����test server�ύ�����ʱ����ύ������ѵ�ϵͳ��
���ķ����빫����baseline���˶Աȡ�Rajpurkar et al. (2016)����ڼල���ع�ģ�������������̣�������һ���������ڲ��ҵ������ʾ���ص���Ϊ�𰸡�Kaushik and Lipton (2018)���üල����ѵ����ģ�����������ʾ���Ϣ�������ش��ĵ������г�ȡ�������ƵĴ�Ƭ�Ρ���������֪�������ǵ�һ��ר�����SQuAD�ǼලQA�Ĺ�����Dhingra et al. (2018)�����о����ǰ�ලQA����ȷʵ������һ���ල�����������Ϊ�˶ԱȵĹ�ƽ�ԣ������������ǹ�������������ʵ�������ǵķ�������ѵ����BERT-Large��һ�����塣���ǵķ���Ҳʹ�������������(cloze questions)������û���õ�ת������(translation)������������Wikipedia���µĽṹ��
��������ķ�����SQuAD�IJ��Լ��ܹ�ȡ�õ���ý����54.7F1������5��ģ��(��ͬ���ӵ�)�������ܹ���һ��ȡ��56.4F1����1 ��¼��baselines���ලѧϰ�����ලQAģ����SQuAD �ϵı��֡�
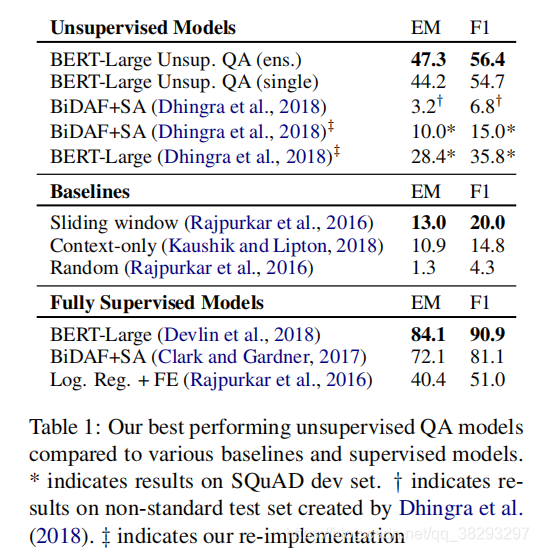
���п��Կ��������ĵķ�����������baselineϵͳ����BiDAF+SA[Dhingra et al. (2018)]�����������ڵļලʽϵͳ��
3.2�����о��ͷ���
Ϊ���˽ⲻͬ��ɲ��ֶ��ڽ�����ܵĹ��ף�������SQuAD dev set�Ͻ�һ�����������о�����Ҫ��BERT-base��BiDAF+SA������ģ�ͽ��������о��������о�������2 ��ʾ��
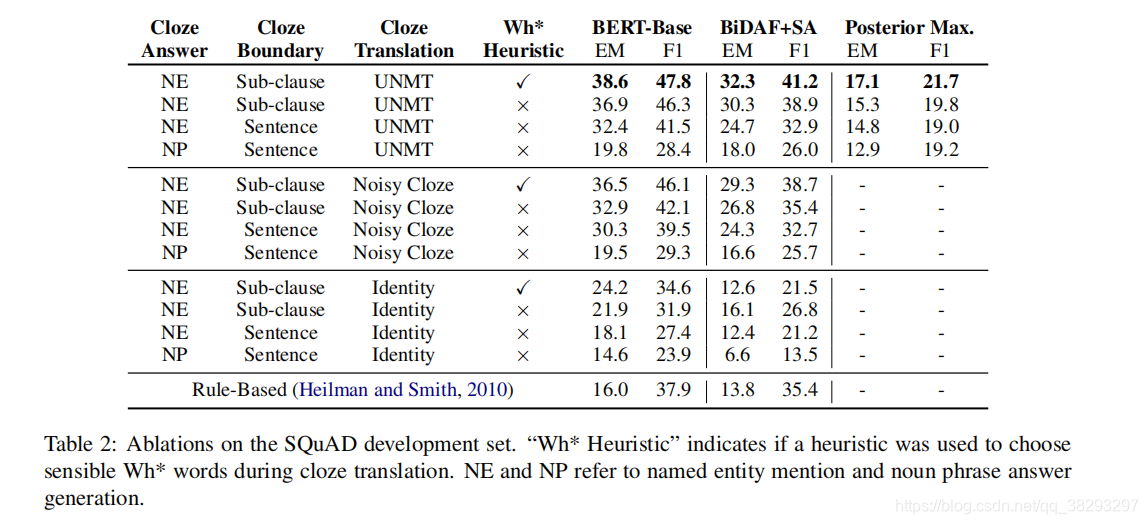
��������� vs. ���������ݼ���ѵ����
�������������BERT-base��BiDAF+SA�Աȷ��֣���ѵ����QAģ���ϱȲ�������ʾ���ȻҪ��Ч�ö����ⲿ�ֹ�����QAģ���ܹ����ɴ�Ƭ�Σ��Ӷ��ڲ���ʱ���صĴ𰸲��������漰����ʵ�塣BERTģ�ͻ���������Ԥѵ�������ƣ���һ������˷���������
������֪ʶ��Ӱ�죺
����ʵ��(NEs)�����ʶ���(NPs)����Ч������ͬ��BERT-baseģ���ϣ�������NEs��Ϣ�������NPs��Ϣƽ����������8.9F1��Rajpurkar et al. (2016)����SQuAD��52.4%�Ĵ���NEs����84.2%�Ĵ���NPs(�趨NEs��NPs���Ӽ�)�����Ǹ��ݱ��ĵ��о����֣�ÿ���ı��д����14NEs����NPs��33���������ѵ�������в���NEs���Խ��ͺ�ѡ�𰸵������ռ䡣
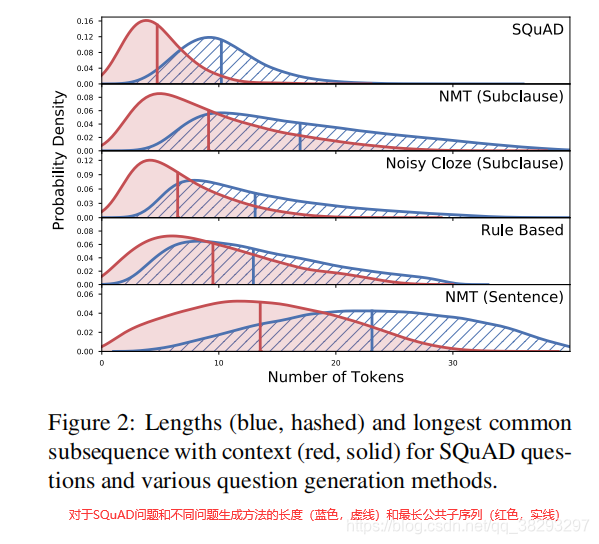
���ⳤ�Ⱥ��ص��̶ȵ�Ӱ�죺
��ͼ2���Կ��������ôӾ�������ɻᵼ�����ɵ�������̣�����ԭʼ�����ĵĹ���������Ҳ���̡�����ʵ������SQuAD�ʾ�ķֲ������������������ij���������translation�������ɸ����Ҹ���ȷ�����⡣��BERT-base�ϲ��ôӾ�Ȳ�����������ƽ��Ҫ�߳� 4.0 F1������"noisy cloze"���������ת����ʽ���ɵ������NMT���̣�ͬʱҲ���̵Ĺ���������(���ڴ��Ŷ�����)��
�������ת����ʽ��Ӱ�죺
������Ч������������BERT-base�϶Ա�"noisy"ת����ʽ��"identity"��ת����ʽ������ǰ��ƽ���߳����� 9.8 F1���ල��NMTЧ���������ֱ�"noisy"��ת����ʽƽ���߳� 1.8 F1��
QAģ�͵�Ӱ�죺
��QAģ���ϵĶԱȣ��ٴ�˵��BERT-base��BiDAF+SA�����㡣BERT-Large(���ڱ�2��)����DZȱ�����õ�ģ�߳� 6.9 F1��
���ڹ����������ݵ�Ӱ�죺
���û��ڹ���(RB)ϵͳ����ѵ����ѵ������QAģ�ͣ�������������NMT������ȡ�Ϊ����֤�Ƿ����ڴ����Ͳ�ͬ�����µģ������������´���:
(a)RBϵͳ�����ɵ���������뱾�ĵ�(NE����)�𰸲�һ�£���ȥ��
(2)�������ɵ����������RBϵͳ�еĴ�����(NE)��һ�£���ȥ��
��3�Ľ��������RBϵͳ�е����ⰴ���ı������ͽ���һ��ɸѡ�������ܿ����������������RBϵͳ�����ݷ��������Ʊ��ĵ��������ɷ�����ή�����ܡ�
3.3 �������
ʵ���з���QAģ����Ȼʹ�õ�ѵ������ֻ��NE���͵Ĵ𰸣�����Ԥ���ʱ��������ѡ������ʵ����Ϊ�𰸡���SQuAD���ݼ����մ��Ƿ�NE���ͻ���������ڴ�����ΪNE���͵����ݼ���ģ�͵���������Ϊ 64.5 F1�����ڴ����Ͳ���NE���͵����ݼ���ģ�͵�������Ȼ��47.9 F1�����ǹ����ڣ�����Ԥѵ����BERT�Ѿ�����һ��������ѧ�����������ܹ����ɳ�NEs�ھ�����������������ã������Ǽ�ģ��NERϵͳ������BiDAF+SAģ�͵���������NE����F1Ϊ 58.9�����������Ƿ�NE����F1 �轵��23.0��
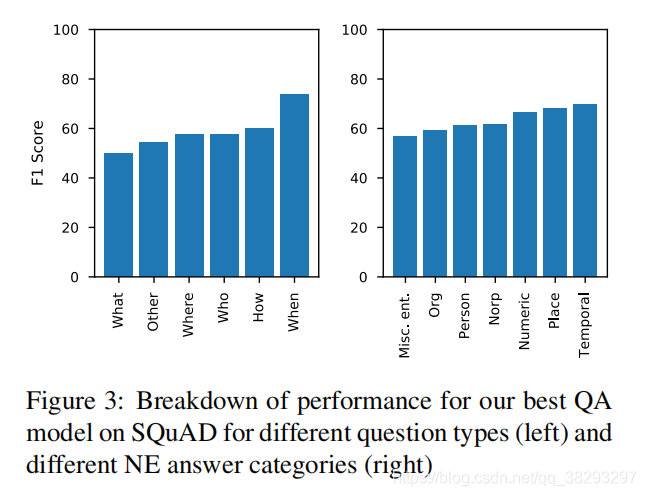
ͼ3 չʾ�˱���ϵͳ�Բ�ͬ��������ʹ����͵����ܽ��������ϵͳ����"when"���������ã���������Ĵ𰸿ռ��С�����Ƕ���"what"�������ڴ������㷺������������Ե�����ÿ�θ����Ĵ��������Ų���������Զ�������ڴ��������ά�ȿ��Կ�������TEMPORAL"���͵Ĵ𰸱�����ã�����"when"������һ�µġ�
3.4 UNMT-�����������
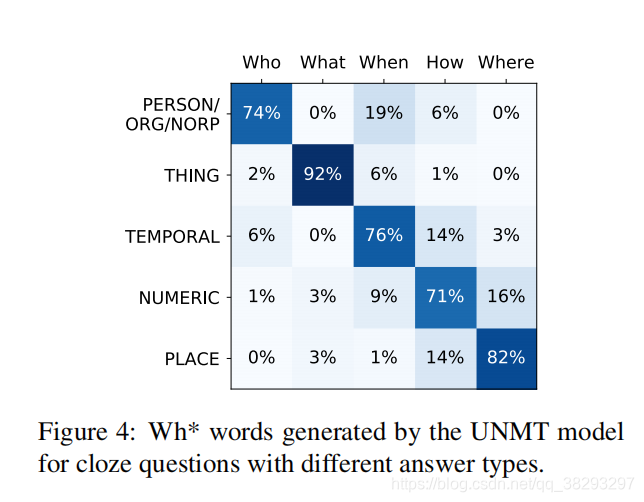
��Ȼ���ĵķ�������������������QAģ�͵����ܣ����Ƕ��ලNMT��UNMT���������ת��ϵͳ�����������м���Ҳ��һ����ָ�����塣�ලNMT��ǰ�ڵ����������õ�(Subramanian et al.,2018)������cloze-to-question���ɸ�����ս��һ����������������������Ȼ�ʾ䵥�ʳ����ǷǶԳƵģ���һ������ת��ʱ��Ҫ�����𰸣�����������dz���ת�������ͼ4չʾ�˲�ʹ��wh*����ʽ����ʱ��ģ���ܹ��ú��ʵ�wh*������Ϊ������ѧϰ�������⡣���Ƕ���Person/Org/Norp ����ֵ�����𰸣����нϴ�������
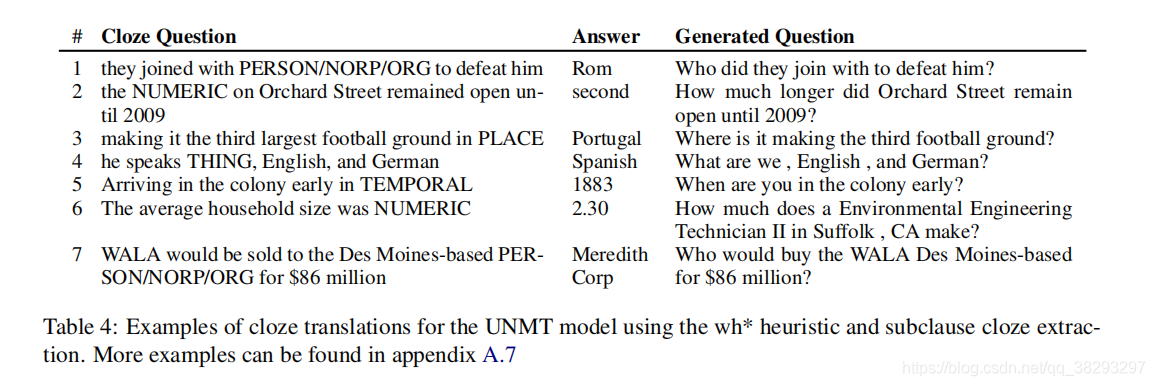
��4չʾ������NE�ලNMTģ�͵Ĵ�����������ģ��ͨ����������Ĵ֡�Ҳ��ͼ2��ʾ�����ɵ�����ƽ�������������ĵ�9.1������token�����У���Ӧ�����ָ������ɵ������56.9%������� SQuAD�����4.7��token(46.1%)���Ⲣ����֣���Ϊ������ѵ����Ŀ��������ȵ��ؽ����룬�������ط��롣
ͼ3��ʾ�����ǵ�ϵͳ�ڲ�ͬ���͵�����ʹ������µ����ܡ���ģ������when�������ϱ�����ã���Ϊ��when�������DZ�ڴ𰸽��٣�����what��������������ͷ�Χ���㣬���ÿ�������ĵĴ𰸸���������ģ������TEMPORAL�����ϱ������ã�����when����������ñ�����һ�¡�
3.5 С�����ʴ�
������ǿ����˽����������Ĵ���ǩ��ѵ�����ݵ�С����ѧϰ���� ����follow��Dhingra et al. (2018) and Yang et al. (2017)�ķ������������ѵ����������ѵ������ʹ�ÿ�������������ֹͣ�� ����ʹ�� Dhingra et al. (2018)�ṩ�IJ�֣����л������Ͳ��Բ�֣���ʹ���Բ�־���n·ע�͵Ĵ𰸡� ��������ʹ�õ�3���е�������ö�BERT-large QAģ�ͽ���Ԥѵ����Ȼ��ʹ��������SQuADѵ�����ݽ������� ���ǽ��������Ǹ��ֵ�Dhingra et al. (2018)����ֱ���ڿ���������ѵ��QAģ�ͣ�����������ල��QAԤѵ����
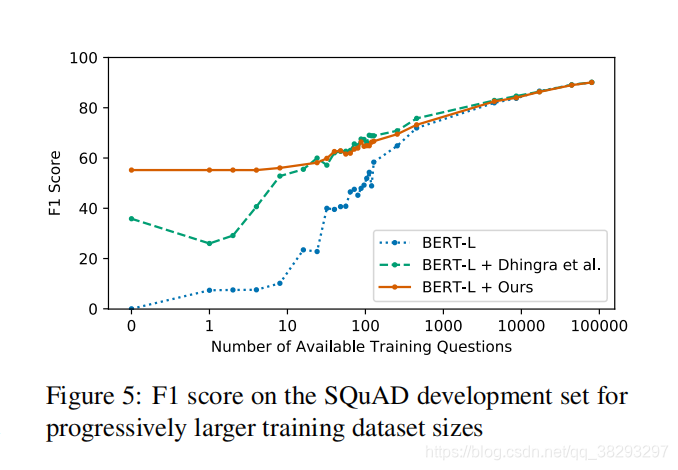
���ķ����ڴ���������ʱ��ı�������ͼ5��ʾ����Dhingra et al. (2018)һ�������ǵ�������ͨ��ʹ�ñ�ѵ�����������������ֹͣ�Ŀ���������õġ���ˣ��Ⲣ���ǵ�����״̬�����ܵ�������ӳ�������ǿ��Զ�ģ�ͽ��бȽϷ�����
���Ƿ������ǵķ����������ѷ�������±�����ã���Dhingra et al. (2018)���ơ����ǻ�Ҫע��
BERT-Large�����dz���Ч������1%�Ŀ������ݾͿ��Դﵽ60%��F1ֵ
4. ��ع���
�ල����
����صĹ������ලNMT�еijɹ�������ο�Conneau et al., 2017; Lample et al., 2017, 2018;Artetxe et al., 2018�����ġ���һ����Ϊ��صijɹ���(Subramanian et al., 2018)�ķ��Ǩ�����ġ�
��ලQA��
Yang et al. (2017)ѵ����QAģ��Ҳ�ܹ������µ����⣬������Ҫ��ע���ݡ�Dhingra et al. (2018)���䷽�����м���������������Ȼ���ල�ģ����Dz�����ԷǼල��QAҲ��������Ȼ�����⡣���⣬�÷���һ����������������ɵ��ı�Ҫ��ǿ��Ҫ������ƣ���һ���滹��ҪWikipedia��ժҪ���䡣Chen et al. (2018)��WebQuestions�ϲ��ð�ල��������������������ܡ�Lei et al. (2016)���ð�ල�����������������ԵĽ�ģ��Golub et al. (2017)���һ�ֿ��������ص�����QAѵ�������ķ�������ʵ��SQuAD��NewsQA֮���Ǩ��ѧϰ����һ�ְ�ල�ķ�ʽ�ǽ��ⲿ֪ʶ���뵽QAϵͳ��Weissenborn et al. (2017) and Mihaylov and Frank(2018)��QA������������Conceptnet(Speer et al., 2016)��
�������ɣ�
�����ǻ���ģ�������������������ģ���ϼ����������ɵ������ܺʹӷ��ŽǶȽ����о���������չΪ���üලʽ�������緽����(Du et al., 2017; Yuan et al., 2017; Zhao et al., 2018; Du and Cardie, 2018; Hosking and Riedel, 2019)���Ի���SQuAD���ݼ��е�c,ac,ac,a���������⡣
5.����
ֵ��ע����ǣ����ķ����е����Ž������Ҫ����NERϵͳ(ֱ�Ӳ���OntoNotes 5�ı�ע����)��������ȡ�Ӿ�Ľ�����(����Penn Treebankѵ������)�����⣬���õ��ض�����(����ָӢ������)��wh*����ʽ������ѵ�����ŵ�NMTģ�͡�������Щ�����˱��ķ����������Ժ�����ԣ�ֻ�ܾ�����ijЩ�зḻ������Դ(NER��treebank datasets)���ض�������ض����֡����⣬���ĵķ�������ҪһЩ������˹��������̣����綨���µ�����ʽ����
���ܱ��ĵķ��������������㣬���DZ��ĵķ���������(question��answer)��(question��context)�� ��������Ƕȿ�ȷʵ���ල�ġ���(question��answer)��(question��context)���ݶ��ڱ�ע���ģQAѵ�����ݼ�ʱ������ѵġ�
������ʹ�õ���"noisy cloze"ϵͳ�ɼĹ����������ɣ����������ܽ��������븴�ӵ�����ϵͳ����(�ɻز��2)���������ּķ���ȱ����������ص���;䷨������"noisy cloze"ϵͳ���ɵ������ڽ����ʾ�������"well-formed"����ȻҲ�Եú��ӣ�ֻ��2.7%��"well-formed"����Щ�����������SQuAD���ԣ������Ƿ���Ȼ������ʽ�Ե�û��ô��Ҫ����ʹ��ʹ��ǿquestion-context�Ĵ�ƥ�䷽ʽҲ�ܹ�ȡ���㹻�õ����ܡ��ⲿ�ֹ������Բο�Jia and Liang (2017)����������֤���˼�ʹ���мල��ģ��Ҳ�����ڵ���ƥ�䡣
��Ҫ����˵�����ǣ�����������������ɷ�������������߶���ӵ���������������Ȼ�ܹ���SQuAD��ȡ�ò��ijɼ�����ʵ�ϣ�Min et al. (2018)ָ��SQuAD��90%������ֻ��Ҫԭ���е�һ�����Ӽ���Ӧ�ԣ�Sugawara et al. (2018)����SQuAD��76%������ʹ𰸴��ڸ߶ȵ�token�ص���
6.�ܽ�
����̽����ȡʽQA���ල������������շ��֣�������������ල����ȷʵ���У��ҳ�Խ�ļලϵͳ����ԶԶ����������ʹ�ñ�ע���ݼ����ල���������ĵ��ල������SQuAD��ȡ�� 56.4 F1������һ���ڴ�����������ʵ��������ݼ���ȡ��64.5 F1�����ͬʱ����Ҫע�������Ȼ�������Լ�QA���������˹��裬����δ��������Ҫ�������������սQA���⣬�������Ƕ�������Դ������ʽ��������