Learning Deep Bilinear Transformation for Fine-grained Image Representation
摘要
DBT block 同一的将输入的channel 划分成不同的语义群,双线性transformation 可以通过群内通道的交互计算获得。这样可以减少计算消耗。每一个block的输出结合输入的残差能够被回归bilinear 特征获得。
文中贡献
(1)使用了DBT结构,能够加入到CNN结构中获得DBTNets网络,成对交互计算可以在不同网络层学习到,来促进特征判别的能力。
(2)通过学习语义群以及计算交换群双线性转换,从判别性较大的channel间获得成对交互
文中组件
Group 卷积
第一次使用实在Alex net中实现的,对每个channel 按照顺序进行卷积。
网络结构

DBT 结构
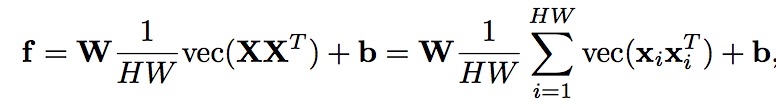
X 是大小为N*H*W大小的feature map 其中N表示channel的数量。
其中W 属于K*N^2,其中b是k维向量,f属于k维向量。分别表示权重, 偏执,以及全连接层
但是这类操作有很多缺陷
文中将语义信息与双线性feature 融为一体。并且提出可以被卷积层适配的深度双线性特征。
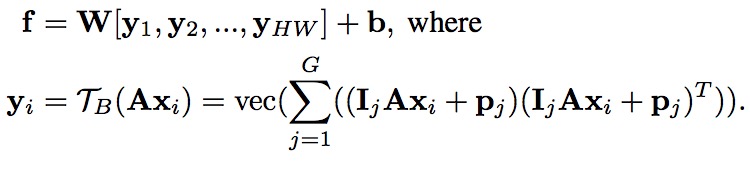
其中TB()表示群blinear function, Axi 表示语义群特征,G表示群的数量,p_j表示群索引编码向量表示群的顺序,Ij 属于N/G*N 是矩阵簇包含G个,第J个区别I, 其他的则是0矩阵。A是语义矩阵,群通道代表相同的语意义。
其中W 为K*(N/G)^2,其中特征[y1, y2, ….yHW]的大小是R(N/G)^2*HW。
语义group layer
深层卷积特征,能够对特殊的语义部分进行响应。我们将卷积的channel根据语义信息分成多个groups。定义每一个channel为一个feature map mi, 其中i属于[1, N],
将语义空间分离成G个groups, S(mi)属于[1, G], 这是一个映射函数,将feature map映射到一个语义空间。为了获得语义部分双线性特征,首先对channel进行排序
![]()
其中AT 是一个n*n的语义映射矩阵,这个矩阵需要进行优化。
为了表示不同语义群,同一语义群和不同与一群的overlap变成下面的loss
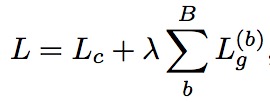
其中
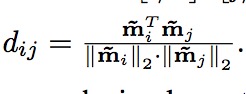
语义建群使用一个1*1的卷积层,一个层可以被变成x = Wz 其中z属于input feature,x是output feature. 假设U = Aw 那么Ax = AWz = Uz ,U就是语义建群层的权重。它的输出是语义群,因为A是索引映射矩阵。
上述索引使用了首先将m*n的feature map拉伸成m*n的向量,再做如上操作。这一层的输出还是HW *N
群双线性层
群双线性卷积可以使用下列形式进行表达
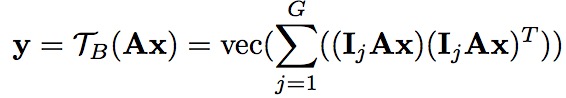
其中Ij 是block 矩阵簇,有G个矩阵,每一个矩阵的大小为N/G*N,其中第j个表示单位矩阵。其他的都是0. Ij AX 是语义群特征的第G个群。输入的X的维度是N, 输出的特征y维度(N/G)^2。
如果G是根号N那么输出的向量也没有改变可以很好的适配卷积网络。
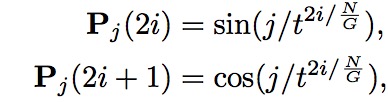
p能够保留group的位置信息
深度属性线性转移网络
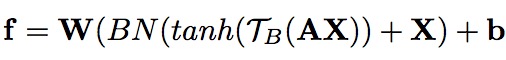

其中SG表示语义groupping 层,GB表示群双线性层。
如果加入GBT之后那么最后的总体loss为
总结
- 主要使用了语义grouping 部分,这一部分使用一个1*1卷积进行排序的一个结果。
第二部分是group bilinear部分。
进一步将这个特征中同一个组内的通道进行双线性操作,来得到针对这个部位的丰富的细节表达,再将不同组之间的双线性表达求和得到低维特征。最后,我们将这样的表达进行向量化,来恢复成卷积特征原本的维度。
群线性就是将向量转化成一个矩阵,然后矩阵家和后再变成N维度向量