1.1��Logistics Regressionģ��
1�����Կɷ�VS���Բ��ɷ�
��������һ���������⣬ͨ�����Է�Ϊ���Կɷ������Բ��ɷ����� �����һ�������������ʹ�������б�����ȷ�ķ��࣬��Ƹ�����Ϊ���Կɷ֡���ͼ��ʾΪ���Կɷ֣�����Ϊ���Բ��ɷ֣�
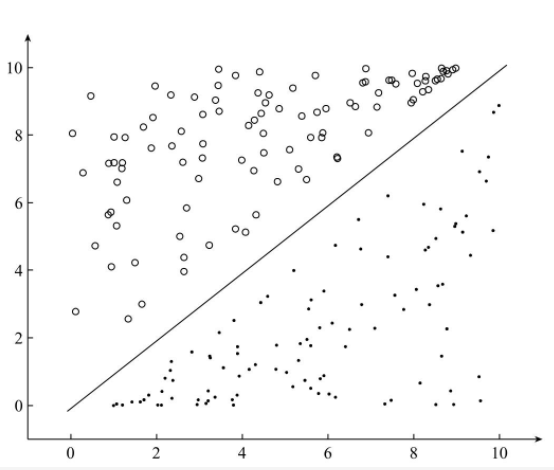
��ͼΪ���Բ��ɷ֣�
1.2��Logistics Regressionģ��
����Logistics Regressionģ��Ϊ���������ģ�͵�һ�֣��������Եķ���ģ�͡��������Կɷ����⣬��Ҫ�ҵ�һ��ֱ�ߣ��ܹ���������ͬ����ֿ�������ֱ��Ҳ��Ϊ��ƽ�档����������ƽ�棬����ʹ�����µ����Ժ�����ʾ��
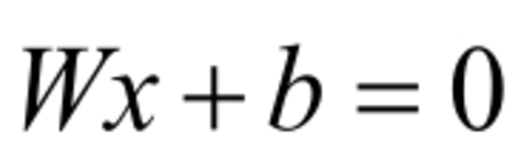
����WΪȨ�أ�bΪƫ�á����ڶ�ά������£�Ȩ��W��ƫ��b��Ϊ��������Logistic Regression�㷨�У�ͨ����ѵ��������ѧϰ�����յõ��ó�ƽ�棬�����ݷֳ�����������𡣴�ʱ����ʹ����ֵ������������ӳ�䵽��ͬ������У���������ֵ������Sigmoid����������ʽ���£�

Sigmoid������ͼ����ͼ��ʾ��

��Sigmoid������ͼ����Կ������亯��ֵ��Ϊ��0,1������0�����ı仯�Ƚ����ԡ��䵼���� Ϊ��
��

����ΪPythonʵ��Sigmoid������Ϊ���ܹ�ʹ��numpy�еĺ������������ȵ���numpy
# -*- coding: UTF-8 -*-
# date:2018/5/24
# User:WangHong
import numpy as np
def sig(x):'''name:Sigmoid����:param x::return:Sigmoid������ֵ'''return 1.0 / (1 + np.exp(-x))
���д�������Ա���ȡֵ��[-7,7]��Sigmoid����ͼ��
# -*- coding: UTF-8 -*-
# date:2018/5/24
# User:WangHong
import numpy as np
import matplotlib.pyplot as plt
def sig(x):'''name:Sigmoid����:param x::return:Sigmoid������ֵ'''return 1.0 / (1 + np.exp(-x))z = np.arange(-7,7,0.1)
phi_z = sig(z)
plt.plot(z,phi_z)
plt.axvline(0.0,color='k')
plt.axhspan(0.0,1.0,facecolor='1.0',alpha=1.0,ls='dotted')
plt.axhline(y=0.0,ls='dotted',color='k')
plt.axhline(y=0.5,ls='dotted',color='k')
plt.axhline(y=1.0,ls='dotted',color='k')
plt.yticks([0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0])
plt.ylim(-0.1,1.1)
plt.xlabel('z')
plt.ylabel('$\phi (z)$')
plt.show()����
�������Կ�����sigmoid�����������⻬���ϸ�����(0,0.5)���ĶԳƣ���һ���dz����õ���ֵ������
��x����������ʱ��y������0��������������ʱ��y������1��x=0ʱ��y=0.5����Ȼ����x����[-6,6]�ķ�Χ����ֵ������û�б仯��ֵ�dz��ӽ�����Ӧ����һ�㲻���ǡ�
Sigmoid������ֵ��Χ������(0,1)֮�䣬����֪��[0,1]�����ֵ�ķ�Χ�����Ӧ�ģ�����sigmoid����������һ�����ʷֲ���ϵ�����ˡ�
����Sigmoid�����ĵ������䱾���ĺ�������f �� (x)=f(x)(1?f(x)) ��
����dz����㣬Ҳ�dz���ʡ����ʱ�䡣�Ƶ��������£�

�ڳ����У�Sigmoid���������ΪSimoidֵ��������������X�������������ĸ���Ϊ��
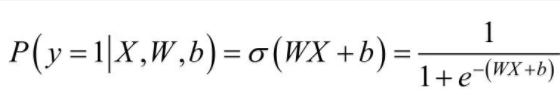
���У� ��ʾ����Sigmoid��������ô��������������X�������ڸ����ĸ���Ϊ��
��ʾ����Sigmoid��������ô��������������X�������ڸ����ĸ���Ϊ��
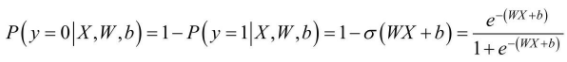
����Logistics Regression�㷨��˵����Ҫ���ķָ���ƽ���еIJ�������ΪȨ�ؾ���W��ƫ������b����ô��Щ�������������ţ�Ϊ�����ģ�͵��������������ȱ��붨����ʧ������
1.3����ʧ����
����������Logistics Regression�㷨�����������y�ĸ���Ϊ��
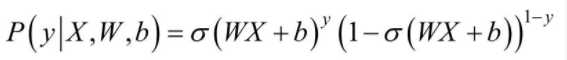
Ҫ����������IJ���W��b������ʹ�ü�����Ȼ��������й��ƣ�����ѵ�����ݼ���m��ѵ������{��X1��y1������X2��y2��,....,(Xm,ym)}��������Ȼ����Ϊ��

���У����躯��hw,b(X(i))Ϊ��

������Ȼ�����ļ���ֵ����⣬ͨ��ʹ��Log��Ȼ��������Logistics Regression�㷨�У�ͨ���ǽ�����Log��Ȼ������Ϊ����ʧ��������the negative log-likelihoo��NLL����Ϊ����ʧ��������ʱ����Ҫ�����NLL����Сֵ����ʧ����lW,bΪ��

��ʱ��������Ҫ��������Ϊ��

Ϊ��������ʧ����lW,b����Сֵ������ʹ�û����ݶȵķ���������⡣
1.4���ݶ��½�����
�����ڻ���ѧϰ�㷨�У����ںܶ�ලѧϰģ�ͣ���Ҫ��ԭʼ��ģ������ʧ����������������ͨ���Ż��㷨����ʧ���������Ż����Ա�Ѱ�ҵ����ŵIJ���W����������ѧϰ����W���Ż��㷨ʱ��ʹ�ý϶���ǻ����ݶ��½����Ż��㷨��Gradient Descent��GD����
�����ݶ��½������ŵ㣬ֻ��Ҫ�����ʧ������һ����������ijɱ��Ƚ�С����ʹ���ݶ��½������ںܶ���ģ���ݼ��ϵõ�Ӧ�á��ݶ��½����ĺ�����ͨ����ǰ������ݶȷ���Ѱ���µĵ����㣬���ӵ�ǰ���ƶ����µĵ��������Ѱ���µĵ����㣬ֱ���ҵ����Ž⡣
����1.4.1���ݶ��½���������
���������ݶ��½�����һ�ֵ����Ե��Ż��㷨�����ݳ�ʼ����ÿһ�ε����Ĺ�����ѡ���½��ķ������ı���Ҫ�ĵIJ����������Ż�����min f��W�����ݶ��½�������ϸ����������ʾ��
-
-
- ���ѡ��һ����ʼ��W0
- �ظ����¹���

- �����ݶ��½�����
- ѡ����
- ���£�Wi+1=Wi+��*di
- ֱ��������ֹ������
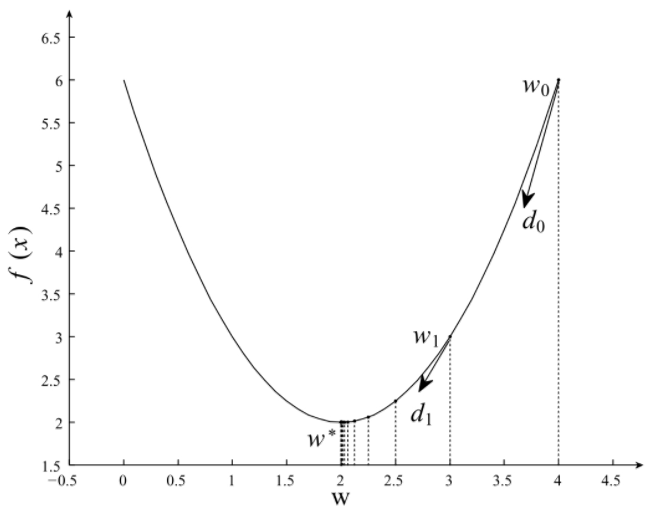
-
�����ڳ�ʼʱ���� W0����ѡ���½��ķ���d0��ѡ����������W��ֵ����ʱ����W1�����ж��Ƿ�������ֹ���������ֲ�δ�������Ž�W*���ظ������Ĺ��̣�ֱ������W*
1.5���Ż�����Ż�
�������������Ż�������ָֻ����һ�����Ž���Ż����⣬�����κ�һ���ֲ����Ž⼴ȫ�����Ž⣬��ͼ��ʾ��

�������Ż���ָ�ڽ�ռ���ڶ���ֲ����Ž⣬��ȫ�����Ž������е�ijһ���ֲ����Ž⣬��ͼ
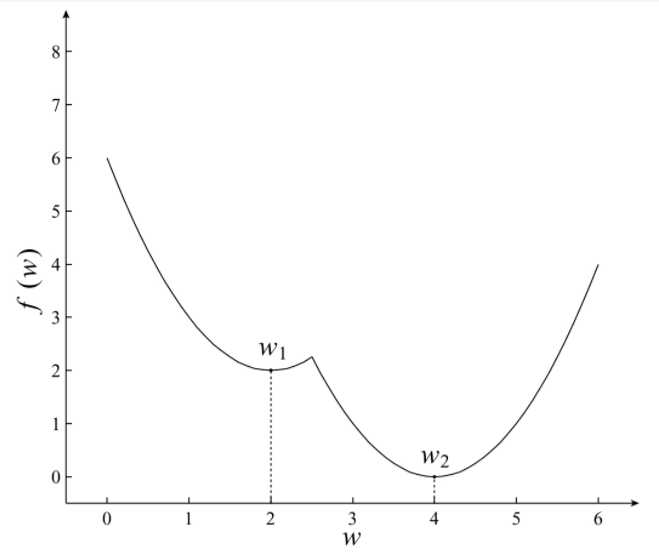
������С���̣�Least Sqares������ع飨Ridge Regression����Logistics�ع飨Logistics Regression������ʧ���������Ż����⡣
1.6�������ݶ��½���ѵ��Logistics Regressionģ��
��������������Logistics Regression�㷨����ʧ��������ͨ���ݶ��½������������⣬���ݶ�Ϊ��
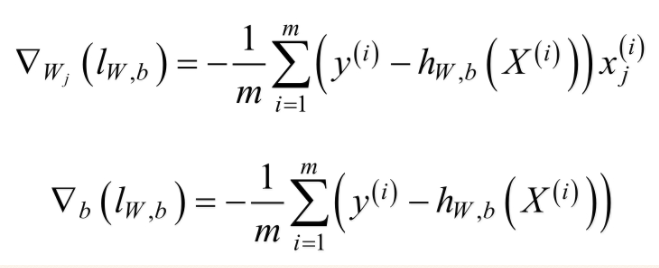
��������xj��i����ʾ��������X��i���ĵ�j��������ȡw0=b���ҽ�ƫ����ı���x0����Ϊ1������Խ��������ݶȺϲ�Ϊ��

�����ݶ��½������õ����¸��¹�ʽ��
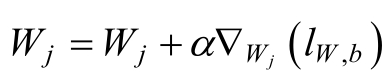
��������������Logistics Regression�е�Ȩ�صĸ��¹�ʽ������ʵ��Logistics Regressionģ�͵�ѵ���������������ݶ��½���ѵ���ľ�����̣��������£�
def lr_train_bgd(feature,label,maxCycle,alpha):''':param feature: ����:param label: ��ǩ:param maxCycle: ����������:param alpha: ѧϰ��:return w:Ȩ��'''n = np.shape(feature)[1] #��������w = np.mat(np.ones((n,1)))#��ʼ��Ȩ��i = 0while i<=maxCycle:#�������������ķ�Χ��i += 1#��ǰ�ĵ������h = sig(feature*w) #����Sigmoidֵerr = label - hif i%100==0:print("\t----------iter="+str(i)+\",train error rate="+str(error_rate(h,label)))w = w+alpha*feature.T*err#����Ȩ��return w
����������
def error_rate(h,label):'''���㵱ǰ����ʧ����ֵ:param h: Ԥ��ֵ:param label: ʵ��ֵ:returnsum_ree / m: ������'''m = np.shape(h)(0)sum_err = 0.0for i in range(m):if h[i,0]>0 and (1 - h[i,0])>0:sum_err -= (label[i,0]*np.log(h[i,0]) + \(1-label[i,0]) * np.log(1-h[i,0]))else:sum_err -= 0return sum_err / m
1.7�ݶ��½�������������
����1.Ϊ������Ż�����f��w������Сֵ������ϣ��ÿ�ε����Ľ���ܹ��ӽ�����ֵW*������һά���������ͼ��ʾ��
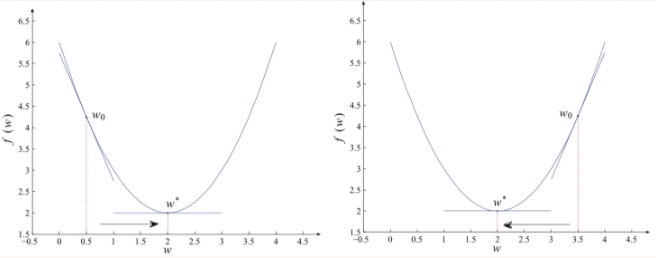
������������ǰ���ݶ�Ϊ��������Сֵ�ڵ�ǰ����Ҳ࣬����ǰ����ݶ�Ϊ��������Сֵ�ڵ�ǰ�����࣬�����ݶȼ�Ϊ�½��ķ�����������һά��������������ĸ��¹���
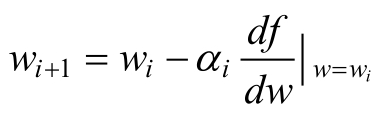
���У���iΪ���������ڶ�ά���������ʱ���µĹ������£�
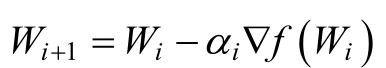
�������ĺ�����ʸ����ƫ��
����2.������ѡ��
�����������ڲ�����ѡ����ѡ��̫С���ᵼ�������ٶȱȽ�������ѡ��ϴ��������������������Ž⣬�����Ž⸽���ǻ�����ͼ��

����ѡ����� ����ѡ���С
��ˣ�ѡ����ʵIJ��������ݶ��½�������Ч���Ե���Ϊ��Ҫ����ͼ��
