1、线性代数
本文借鉴至:https://github.com/exacity/deeplearningbook-chinese
1、标量、向量、矩阵和张量
-
- 标量(scalar):一个标量就是一个单独的数,它不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。 我们用斜体表示标量。标量通常被赋予小写的变量名称。 当我们介绍标量时,会明确它们是哪种类型的数。 比如,在定义实数标量时,我们可能会说”让 s ∈ R 表示一条线的斜率”;在定义自然数标量时,我们可能会说”让 n ∈ N 表示元素的数目”。
-
向量(vector):一个向量是一列数。 这些数是有序排列的。 通过次序中的索引,我们可以确定每个单独的数。 通常我们赋予向量粗体的小写变量名称,比如 x。 向量中的元素可以通过带脚标的斜体表示。 向量 x的第一个元素是 x 1,第二个元素是 x 2 ,等等。 我们也会注明存储在向量中的元素是什么类型的。 如果每个元素都属于 R,并且该向量有n个元素,那么该向量属于实数集 R的n次笛卡尔乘积构成的集合,记为 Rn。 当需要明确表示向量中的元素时,我们会将元素排列成一个方括号包围的纵列:
我们可以把向量看作空间中的点,每个元素是不同坐标轴上的坐标。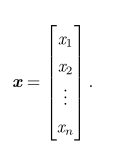
有时我们需要索引向量中的一些元素。 在这种情况下,我们定义一个包含这些元素索引的集合,然后将该集合写在脚标处。 比如,指定指定 x 1 ,x 3 和 x 6 ,我们定义集合S={1,3,6},然后写作x S。我 们用符号-表示集合的补集中的索引。 比如 x ?1 表示 x 中除 x 1 外的所有元素,x ?S 表示 x 中除 x 1 ,x 3 ,x 6外所有元素构成的向量。
-
矩阵 (matrix):矩阵是一个二维数组,其中的每一个元素被两个索引(而非一个)所确定。 我们通常会赋予矩阵粗体的大写变量名称,比如 A。 如果一个实数矩阵高度为m,宽度为n,那么我们说 A ∈ R m×n 。 我们在表示矩阵中的元素时,通常以不加粗的斜体形式使用其名称,索引用逗号间隔。 比如,A 1,1 表示 A 左上的元素,A m,n 表示 A 右下的元素。 我们通过用”:”表示水平坐标,以表示垂直坐标i中的所有元素。 比如,A i,: 表示 A 中垂直坐标i上的一横排元素。 这也被称为 A 的第 i行 (row)。 同样地,A :,i 表示 A 的第 i列 (column)。 当我们需要明确表示矩阵中的元素时,我们将它们写在用方括号括起来的数组中:
有时我们需要索引矩阵值表达式,而这些表达式不是单个字母。 在这种情况下,我们在表达式后面接下标,但不必将矩阵的变量名称小写化。 比如,f(A) i,j表示函数f作用在A上输出的矩阵的第 (i,j) 个元素。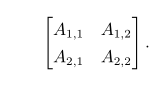
- 张量(tensor):在某些情况下,我们会讨论坐标超过两维的数组。 一般地,一个数组中的元素分布在若干维坐标的规则网格中,我们称之为张量。 我们使用字体 A来表示张量”A”。 张量张量 A 中坐标为 (i,j,k) 的元素记作 A i,j,k。
转置是矩阵的重要操作之一。 矩阵的转置是以对角线为轴的镜像,这条从左上角到右下角的对角线被称为主对角线。下图显示了这个操作。 我们将矩阵 A的转置表示为 A ? ,定义如下
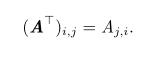
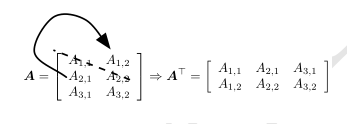
-
向量可以看作只有一列的矩阵。 对应地,向量的转置可以看作是只有一行的矩阵。 有时,我们通过将向量元素作为行矩阵写在文本行中,然后使用转置操作将其变为标准的列向量,来定义一个向量,比如 x = [x 1 ,x 2 ,x 3 ] ? .
标量可以看作是只有一个元素的矩阵。 因此,标量的转置等于它本身,a = a ?。
只要矩阵的形状一样,我们可以把两个矩阵相加。 两个矩阵相加是指对应位置的元素相加,比如 C = A + B,其中 C i,j = A i,j + B i,j。
标量和矩阵相乘,或是和矩阵相加时,我们只需将其与矩阵的每个元素相乘或相加,比如D = a ・ B + c,其中 D i,j = a ・ B i,j + c。
在深度学习中,我们也使用一些不那么常规的符号。 我们允许矩阵和向量相加,产生另一个矩阵:C = A + b,其中 C i,j = A i,j + b j 。 换言之,向量b和矩阵A的每一行相加。 这个简写方法使我们无需在加法操作前定义一个将向量b复制到每一行而生成的矩阵。 这种隐式地复制向量b到很多位置的方式,被称为广播。
2、矩阵和向量相乘
如果矩阵 A 的形状是 m×n,矩阵 B 的形状是 n×p,那么矩阵C的形状是 m × p
C = AB
具体地,该乘法操作定义为:
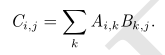
需要注意的是,两个矩阵的标准乘积不是指两个矩阵中对应元素的乘积,那样的矩阵操作确实是存在的,被称为元素对应乘积 (element-wise product) 或者哈达玛乘积 (Hadamard product),表示为 A ⊙ B。
两个相同维数的向量 x 和 y 的点积 (dot product) 可看作是矩阵乘积 x ? y
矩阵乘法的性质:
-
-
- 分配率:A(B+C)=AB+AC.
- 结合律:A(BC)=(AB)C
- 两个向量的点积满足交换律:x?y=y?x.
- 矩阵乘积的转置:(AB)?=B?A?.
-
Ax = b其中A是一个已知矩阵,b是一个已知向量x 是一个我们要求解的未知向量
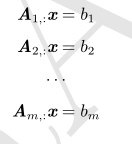
或者,更明确地,写作:
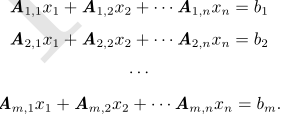
3、单位矩阵和逆矩阵
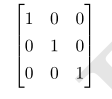
为了描述矩阵逆,我们首先需要定义单位矩阵的概念。 任意向量和单位矩阵相乘,都不会改变。 我们将保持n维向量不变的单位矩阵记作 I n。 形式上,I n ∈ R n×n ,
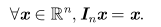
单位矩阵的结构很简单:所有沿主对角线的元素都是1,而所有其他位置的元素都是0:
矩阵A的矩阵逆记作 A ?1,其定义的矩阵满足如下条件:
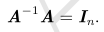
现在我们可以通过以下步骤求解:
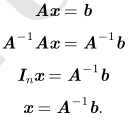
当然,这取决于我们能否找到一个逆矩阵 A ?1 。 在接下来的章节中,我们会讨论逆矩阵A ?1 存在的条件。当逆矩阵A ?1 存在时,有几种不同的算法都能找到它的闭解形式。 理论上,相同的逆矩阵可用于多次求解不同向量b的方程。 然而,逆矩阵A ?1 主要是作为理论工具使用的,并不会在大多数软件应用程序中实际使用。 这是因为逆矩阵A ?1 在数字计算机上只能表现出有限的精度,有效使用向量b的算法通常可以得到更精确的x
4、线性相关和生成子空间
如果逆矩阵A ?1 存在,那么Ax = b肯定对于每一个向量b恰好存在一个解。 但是,对于方程组而言,对于向量b的某些值,有可能不存在解,或者存在无限多个解。 存在多于一个解但是少于无限多个解的情况是不可能发生的;因为如果x和y都是某方程组的解,则
(其中$\alpha$取任意实数)也是该方程组的解。
为了分析方程有多少个解,我们可以将A的列向量看作从原点(元素都是零的向量)出发的不同方向,确定有多少种方法可以到达向量b。 在这个观点下,向量x中的每个元素表示我们应该沿着这些方向走多远,即 x i表示我们需要沿着第$\Si$个向量的方向走多远:
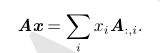
一般而言,这种操作被称为线性组合。 形式上,一组向量的线性组合,是指每个向量乘以对应标量系数之后的和,即:
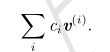
一组向量的生成子空间 (span) 是原始向量线性组合后所能抵达的点的集合
确定 Ax = b 是否有解相当于确定向量 b 是否在 A 列向量的生成子空间中,这个特殊的生成子空间被称为 A 的列空间 (column space) 或者 A 的值域 (range)。
为了让方程 Ax = b 对于任意的向量 b ∈ R m 都有解的话,我们要求 A 的列空间构成整个 R m 。如果 R m 中的某个点不在 A 的列空间中,那么该点对应的 b 会使得该方程没有解。矩阵 A 的列空间是整个 R m 的要求,意味着 A 至少有 m 列,即n ≥ m。否则,A 列空间的维数会小于 m。例如,假设 A 是一个 3 × 2 的矩阵。目标 b 是 3 维的,但是 x 只有 2 维。所以无论如何修改 x 的值,也只能描绘出 R 3 空间中的二维平面。当且仅当向量 b 在该二维平面中时,该方程有解。
不等式 n ≥ m 仅是方程对每一点都有解的必要条件。这不是一个充分条件,因为有些列向量可能是冗余的。假设有一个 R 2×2 中的矩阵,它的两个列向量是相同的。那么它的列空间和它的一个列向量作为矩阵的列空间是一样的。换言之,虽然该矩阵有 2 列,但是它的列空间仍然只是一条线,不能涵盖整个 R 2 空间
正式地,这种冗余被称为线性相关 (linear dependence)。如果一组向量中的任意一个向量都不能表示成其他向量的线性组合,那么这组向量被称为线性无关 (linearlyindependent)。如果某个向量是一组向量中某些向量的线性组合,那么我们将这个向量加入到这组向量后不会增加这组向量的生成子空间。这意味着,如果一个矩阵的列空间涵盖整个 R m ,那么该矩阵必须包含至少一组 m 个线性无关的向量。这是式Ax = b 对于每一个向量 b 的取值都有解的充分必要条件。值得注意的是,这个条件是说该向量集恰好有 m 线性无关的列向量,而不是至少 m 个。不存在一个 m 维向量的集合具有多于 m 个彼此线性不相关的列向量,但是一个有多于 m 个列向量的矩阵却有可能拥有不止一个大小为 m 的线性无关向量集。
要想使矩阵可逆,我们还需要保证式Ax = b 对于每一个 b 值至多有一个解。为此,我们需要确保该矩阵至多有 m 个列向量。否则,该方程会有不止一个解。
综上所述,这意味着该矩阵必须是一个方阵 (square),即 m = n,并且所有列向量都是线性无关的。一个列向量线性相关的方阵被称为奇异的 (singular)。如果矩阵 A 不是一个方阵或者是一个奇异的方阵,该方程仍然可能有解。但是我们不能使用逆矩阵去求解。目前为止,我们已经讨论了逆矩阵左乘。我们也可以定义逆矩阵右乘:
AA ?1 = I.
对于方阵而言,它的左逆和右逆是相等的