论文:Generalizing Person Re-Identification by Camera-Aware Invariance Learning and Cross-Domain Mixup
基于域内相机感知和跨域混合的泛化行人重识别方法
出处:ECCV2020
文章目录
- 1. Motivation
- 2. Introduction
- 3. Overview
- 4. Camera-Aware Neighborhood Invariance
- 5. Cross-Domain Mixup
1. Motivation
当有监督的reid模型部署到一个unseen domain,会出现较大的性能退化,出现这一现象的原因有:目标域内的变化(dramatic variation within the target domain) 和 源域目标域之间的转变(the severe shift between the source and target domain)。其中,第一个原因主要来自相机之间的差异。

针对第一个问题,目前比较好的解决方案有:在嵌入空间中增强最近邻之间的一致性(见ECN系列论文),但是由于相机风格的差异,对近邻的搜索是高度偏差的。作者就提出一种以相机感知的方式施加约束来改进传统的近邻不变性的方法。
针对第二个问题,作者提出一种新的cross-domain mixup方式,引入两个域之间的插值作为过渡状态,来缓解abrupt transfer。
2. Introduction
域内变化:一些研究已经验证了邻域不变性(neighborhood invariance)在处理目标域的域内变化中的有效性。这些方法配备了一个memory bank,在整个数据集上搜索每个探针的邻居,并在它们之间施加一致性约束。然而,由于缺乏对目标域的监控,该模型不能很好地抑制相机间的变化(包括照明、视角和背景等)的影响。在这种情况下,近邻搜索很容易偏向与探针(probe)来自同一摄像机的候选对象。更确切地说,在rank list中,相机间匹配的正样本更有可能排列在很多相机内匹配的负样本之后,这就混淆了模型学习。为了解决这个问题,我们通过对 相机内匹配 和 相机间匹配 分别施加约束来改善邻域不变性。
域间差异:为了减轻域间差异的不利影响,早期的工作使用额外的生成模型跨域传递图像样式,这本质上是源和目标流形之间的高级插值。通过引入风格化图像作为中间域,这些方法期望避免由两个非常不同的域之间突然转变所引起的问题。根据这一观点,我们探索通过直接插值来自两个域的样本来实现相同的目的。与风格迁移不同,像素级的直接混合导致内容的变化,所以身份标签也要做相应的混合。这就是mixup过程。然而,直接使用普通的mixup是不合适的,因为它最初是为闭集问题而制定的。为了使它适用于open-set cross-domain person reID,我们增加了一个动态分类器。它不需要访问目标域的精确标签空间,即可以自适应地覆盖输入source-target pairs 的标签空间。
3. Overview

input包括target data(橙色箭头)和mixed data(绿色箭头),送入backbone提取特征,然后将特征存储在一个memory bank中,每一列都存储相应的图像的特征,并且M是以一种 running-average 的方式进行更新的。
4. Camera-Aware Neighborhood Invariance
没有目标域的label信息,在目标域上直接进行分类任务是不可行的。在这种情况下,目标域样本之间的成对关系是指导表征学习的一个重要线索。在表征学习中,通常会假设每个样本和它的最近邻样本有相同label的概率很高。
在ECN中,提出在整个数据集中最大化每个probe image和它的最近邻之间的概率,因为它会在搜索近邻时同等对待所有的candidates,不管他们是否由相同的相机捕获到。然而,由于摄像机之间的场景变化,摄像机间匹配和摄像机内匹配之间的相似性分布存在显着差异。即使不是positive matches ,相机内的candidates也会更占据top ranking list。
为了解决这个问题,作者就提出了Camera-Aware Neighborhood Invariance ,分别对相机内匹配和相机间匹配执行邻域不变性。Lt = L1 + L2。
5. Cross-Domain Mixup
大多是用GAN来进行风格迁移来缓解domain shift,但是GAN的训练过程不稳定,作者提出了一种更简单的方法mixup来实现同样的目标。
mixup,是一种新的多样本数据增强的方式。给定一个参数a ,我们根据a的贝塔分布,得到参数 λ\lambdaλ,使用参数 λ\lambdaλ 对两张图片和他们的标签进行线性插值。
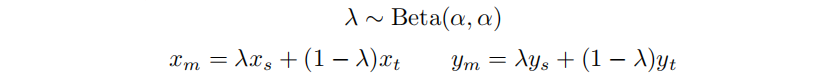
对两张图片进行mixup,λ\lambdaλ的值不同,会得到不同的插值图像。具体的,如下图所示:


但是,要使用mixup来混合源域和目标域的数据有两个问题:目标域的label是不可知的、源域和目标域的label space是不相交的。作者的做法是用加权的输入在两个label上分别计算cross-entropy loss,最后把两个loss加权作为最终的loss。
举个例子,Market-to-Duke的任务,对于 source data 和 target data 我们各取128张,然后对这些图片进行mixup,得到128张新的mixed data,但是label那里我们不做处理(source data有准确的label,target data没有label)。
我们把这128张mixed data送入backbones得到最后的分类结果cls_score是128X751维的(market数据集一共有751个ID),我们对预测进行padding操作,使其成为128X752维的向量(最后一个维度都补0),然后我们将cls_score 和 源域label求一个交叉熵损失,得到loss_1。然后我们将 cls_score 和 目标域虚拟的label(我们将target data的label都置为752) 求一个交叉熵损失,得到 loss_2 ,对这两个损失进行加权得到最终的损失Lm。
总loss:L = Lt +Lm
参考:https://zhuanlan.zhihu.com/p/337081518