文章目录
-
- Deep Interest Network for Click-Through Rate Prediction(2018)
-
- (0) 个人小结
- (1) 研究目标
- (2) 背景 & 问题描述
- (3) 研究方法
- (4) 结论与展望
Deep Interest Network for Click-Through Rate Prediction(2018)
(0) 个人小结
在一般的深度学习模型中,将用户的行为特征处理为定长的Embedding,这限制了模型表示的信息量,如果增加Embedding的长度,则对计算和存储带来压力。除此之外,**用户的兴趣具有多样性,**应针对不同的目标Item,改变用户历史记录中各行为的权重。由此,该文提出了DIN模型,该模型中引入了局部激活单元来学习各特征的Embedding在预测目标Item时的重要程度(即给各Embedding赋予不同的权重,具体通过求和池化或平均池化)。同时提出了Mini-batch Aware Regularization来减小计算量,提出了自适应激活函数Dice来根据数据的分布适应地调整修整点。
该模型的整体思路:对于不同的用户,针对不同的目标Item有着不同的向量表征。
(1) 研究目标
提出DIN模型,有效学习用户多样化的兴趣,针对不同的Item,从用户行为中学习到不同的用户表征。同时提出两个训练技术:MBA Reg. 和自适应激活函数Dice。
(2) 背景 & 问题描述
一般深度学习是Embedding&MLP的思想,该思想是将用户行为特征学习并通过look up操作得到定长的Embedding,这使得用户行为信息不能够充分地表达,同时用户的兴趣是多样性的,在面对不同的目标Item时,以前的方法只是简单的将Embedding拼接在一起,不能区分在面对不同目标Item时,用户历史行为数据中各记录的重要性。由此,提出了DIN来解决以上问题。
(3) 研究方法
该模型架构图如下:

最底层是Embedding层,它将输入特征映射为稠密定长的Embedding,然后通过局部激活单元来为每个Embedding学习得到一个权重,最后通过求和池化将各Embedding映射为定长Embedding,喂给深度模型。右边是局部激活单元。
局部激活单元:
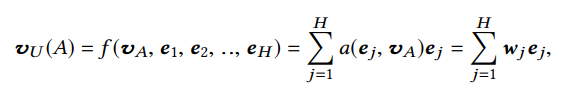
局部激活单元通过加权和池化来自适应地计算用户关于某个目标Item(vAv_AvA?)的表征(vUv_UvU?)。其中,e1,e2,...,eH{e_1,e_2,...,e_H}e1?,e2?,...,eH?是用户行为的Embedding列表,α\alphaα是输出的激活权重。
局部激活效果: 与候选Item越相关的行为的Attention分数越高,如下图:

两个训练技巧:
-
Mini-batch Aware Regularization:
为了防止过拟合,一般会加入正则项,而L1,L2正则,在参数更新时,对每个参数都要进行一轮计算,使得计算复杂度变高。由此提出该正则化,只对batch中出现的稀疏特征来进行L2正则,并更新参数。
-
Data Adaptive Activation Function(Dice)
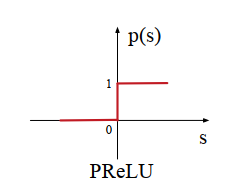
激活函数PReLU在0点有突变,如下图所示:
当每层的输入服从不同的分布时,该激活函数便不再适合,由此提出Dice激活函数,其形状如下:
其表达式为:
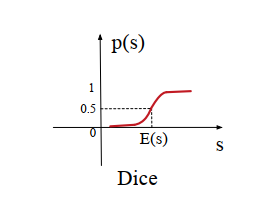
其中,p(s)p(s)p(s)是一个控制函数,负责控制f(s)=sf(s)=sf(s)=s 还是$f(s)=\alpha s $ ,E[s]E[s]E[s] 和 Var[s]Var[s]Var[s]分别为每个小批量输入的均值和偏置,?\epsilon? 是一个很小的常量,如:10?810^{-8}10?8。
Dice 对每个特征以mini-batch为单位计算均值和方差,然后将rectified point调整到均值位置。
(4) 结论与展望
提出了DIN模型,该模型根据不同的目标Item,从用户历史行为中得到不同的表征向量,从而更加真实地反映用户兴趣的多样性。