һ��Batch Normalization
���ģ�https://arxiv.org/pdf/1502.03167.pdf
Դ�룺 link.
Batch Normalization��google�Ŷ���2015�����ġ�Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift������ġ�
������Ϊ��ʱһƪ�����Ž����ѧϰǰʮ��һƪ������Ŀǰ�ֵ������㷨��ģ�Ͷ����õ�BN���������ӿ�ģ�͵������ٶ���ѵ��ʹ��BN��ģ�������Ȳ�ʹ��BN��ģ�Ϳ�10�������Ҹ���Ҫ������һ���̶Ȼ�������������С��ݶ���ɢ�������ֲ���ɢ�������������ڴ��������ǻ����ϻ�Ĭ��ʹ��Conv + BN + activation function����ϣ�����bn��������������ĺ������ἰ��
������ֱ���Ͽ�����ôʹ��Batch Normalization��

1������֪ʶ
ʲô������Normaliztion��Scaling ��һ����������?
���ݵĹ�һ��normalization���ǽ����ݰ��������ţ�ʹ֮����һ��С���ض����䡣
�ɷ�Ϊ���Ժ�����һ����Min-Max Scaling�������ֵ��һ����Zero-Score Normalization������
���Ժ�����һ����Min-Max Scaling��
��ʽ��
���У�XΪԭʼ���� ��Xmean Ϊԭʼ���ݾ�ֵ ��XmaxΪԭʼ���ݵ����ֵ ��XminΪԭʼ���ݵ���Сֵ
���Ժ�����һ����Min-Max Scaling��
��ʽ��
���У���Ϊԭʼ�����ľ�ֵ����Ϊԭʼ�����ı�������
���Ὣԭʼ����ӳ�䵽��ֵΪ0������Ϊ1�ķֲ��ϣ���˹�ֲ�/��̬�ֲ���
feature map ΪʲôҪ��Normaliztion����һ����?
1������ѵ�������ѵ���ٶ�
2����ֹģ���ݶȱ�ը
3������ģ�͵ľ���
����ѵ������������ٶ�

����ͼ���Ҵ��������ʦ��BN������Ƶ.�н�ȡ��һ��ͼ����ߵ�ͼ��ʾû����Normalization���������ݣ������������ݵ�ֵ�����ϴ�ģ������������� x2>>x1x2 >> x1x2>>x1����ô���� wx+bwx+bwx+b ����ͨ��������õ�Ԥ��ֵ aaa��ͨ��Ԥ��ֵ����ʵֵ�õ���ʧ���� LossL��
��Ϊ x2>>x1x2 >> x1x2>>x1�� ����W2��LossL��Ӱ��dz���W1��LossL��Ӱ���С������ ��ʧ����������Ȩ��W1 �� W2��ͼ��������ͼ����Բ�εȸ��ߣ�����W2������grad�ܴ� ��W1��grad��С����ô��ѵ����ʱ�������Ҫ�ı�ϴ�Ļ�������Ҫ��W2����һ����С��learning_rate����W1����һ����С��learning_rate��������ǵ�ѵ����˵�϶������������Ѷȵġ�
ͬ���������������������Normalization��ʹ�������������ֵΪ0������Ϊ1�ķֲ����Ļ�����ô x1x1x1�� x2x2x2����W1��W2��Loss����ʧ������ô�ͻ��������ͼ��ԭ�εȸ��ߣ�����W2��W1������grad������ô���ǾͿ���ֻ��һ��learning_rate����ѵ������ʹ�������ǵ�ѵ���Ѷȡ�
��ֹģ���ݶȱ�ը

����ͼ�Ǿ�ֵΪ0������Ϊ1�ı���̬�ֲ�ͼ������ͼ��֪��64%�ĸ���x��ֵ����[-1,1]�ķ�Χ�ڣ�95%�ĸ���x��ֵ������[-2,2]�ķ�Χ�ڡ���ô����ʲô�����أ����Ƕ�֪������ֵ�ھ�����Ȩ��wx+b���ᾭ���������sigmoid ��tanh��relu�ȣ������������Ժ�����sigmoid����ô����sigmoid(x)�������䵼��ͼ�Σ�

��û�о���Normalizationǰ��95%��ֵ������[-8,4]֮�䣬��sigmoid����ͼ���Կ�������[-8, -2] �� [2, 4]����������ݶȱ�����������������ݶȼ�����ʧ���dz�����ѵ����ѵ�������ٶ��ر��������������BN��Ŀǰ��Activation��ֵ��������Ժ������������ڣ����Ӧ�ĵ���Զ�뵼��������������������ѵ���������̣���ֹ�ݶȱ�ը��
����ģ�͵ľ���
ÿ��ά�ȵ�������ʵ�Ѿ��ȼ��ˣ�ÿ��ά�ȶ����Ӿ�ֵΪ0,������Ϊ1����̬�ֲ����ڼ�������ʱ��ÿ��ά�ȶ���ȥ���ٻ��ģ������˲�ͬ���ٵ�ѡȡ�Ծ����������ľ�Ӱ�졣
ΪʲôҪ������Batch�����ͽ�ģ�ͣ�
1��Batch֮����Խ�һ��Batch�����ݷŵ�һ�������У�ʹ��GPU���о������㣬��������
2��Batch�ڴ���ʱ������Ҫ�����ܵĴ���һ��Batch�ľ�ֵ�ͷ�����Ϊ���������ݼ���ֵ�ͷ���Ĺ���
���Ǹո���˵��feature map����ijһ�ֲ����ɣ���������ָ����ѵ������������Ӧfeature map������Ҫ����ֲ����ɣ�Ҳ����˵Ҫ���������ѵ������feature mapȻ���ڽ��б�������������һ�����͵����ݼ������Dz����ܵģ�����������˵����Batch Normalization��Ҳ�������Ǽ���һ��Batch���ݵ�feature mapȻ���ڽ��б�����batchԽ��Խ�ӽ��������ݼ��ķֲ���Ч��Խ�ã���
ʲô��Internal Covariate Shift(�ڲ�Э����ƫ��)��
�ڲ�Э����ƫ��ָ���ǵ�ǰ���һЩ�㣨������������С�ı仯����Ժ���IJ���ɺܴ��Ӱ�졣����IJ���Ҫ���ϵ���Ӧǰ���ı仯�����·dz�����ѵ����
�������ʹ��BN����Ե��Ը���
ΪʲôҪ��ģ�͵�ÿһ��������ʹ��Normalization?
���������潲��Normalization(����Ҫ����ֲ�����)�ĺô�����Ȼ����������ݽ�����Normalization�����Ƕ���Conv2���������feature map�Ͳ�һ������ijһ�ֲ������ˡ���������������ÿһ���ڽ��м�Ȩ����֮������Normalization����������뼤�����
ע��������˵����ijһ�ֲ����ɲ�����ָijһ��feature map������Ҫ����ֲ����ɣ���������ָ����ѵ������������Ӧfeature map������Ҫ����ֲ�����
��������Ҳ���Լ��������Internal Covariate Shift(�ڲ�Э����ƫ��)����
2��ѵ��������

BN������Ϊ�������һ�㣬���ڼ��������Relu��֮ǰ��
��ͼ��ԭ���Ľ�ȡ��һ��ͼ����������ѵ���IJ���(��ÿһ��mini-batch)��
- ���һ��mini-batch�ľ�ֵmean
- ���һ��mini-batch�ķ���/���� variance
- ʹ����õľ�ֵ�ͷ���Ը����ε�ѵ����������һ�������0-1�ֲ������Ц���Ϊ�˱������Ϊ0ʱ��ʹ�õ�С����
- �߶ȱ任��ƫ�ƣ���xix_ixi?������\gamma��������ֵ��С���ټ��Ϧ�����ƫ�ƺ�õ�yiy_iyi?���������\gamma���dz߶����ӣ�����ƽ�����ӡ���һ����BN�ľ��裬���ڹ�һ�����xix_ixi? �����ᱻ��������̬�ֲ��£�ʹ������ı��������½���Ϊ��������⣬�������������µIJ�������\gamma�� �� �¡� ��\gamma���ͦ�����ѵ��ʱ�����Լ�ѧϰ�õ��ġ�
��ô����ʱ�ָ���ô��BN�أ�
���Խβ���Ҫÿһ�����������ֵ�ͷ�����ǻ�ѡ��ѵ��ʱ���д����Եľ�ֵ�ͷ�����빫ʽ������������Եľ���ָ����ѵ�����м���������о�ֵ�ͷ����ƽ������Ϊ������ÿһ��mini-batch�����ֵ�ͷ����ʱ�ᱣ�����Ӧ�ľ�ֵ�ͷ���ģ����Կ��Ժܷ���ļ������֮�����BN���Ǻ�ѵ��ʱ�Ĺ�ʽһ�������ﲻ������
3������ʾ��
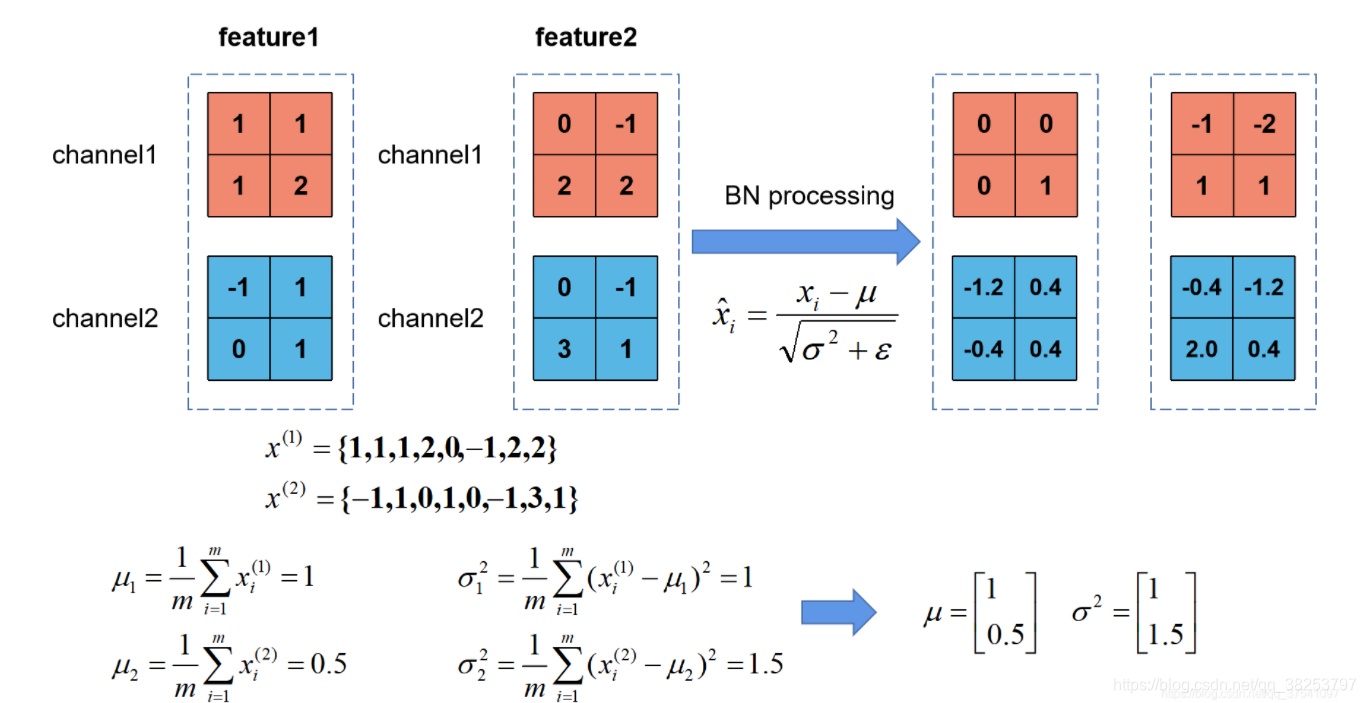
- �����u1u_1u1?�Ƕ�����batch��channel1���������ݶ��Եģ�ͬ��Ҳ�ɼ��������batch��channel2���������ݵľ�ֵu2u_2u2?������ϳ�uuu
- ���þ�ֵ�ͷ��ʽ�����������2\sigma^2��2
- ��mini-batch��ÿһ��channel��ÿһ��Ԫ�أ����ü���ľ�ֵuuu�ͷ�����2\sigma^2��2����BN��ʽ���Ϳ������Ӧλ�õ�ֵ��
4������ʵ��
import randomimport torch.nn as nn
import torchdef BN(feature, mean, var):feature_shape = feature.shape # (2, 2, 2, 2) = (batch_size, C, H, W)for i in range(feature_shape[1]): # feature_shape[1] = 2 = C: channel# [batch, channel, height, width]feature_t = feature[:, i, :, :]mean_t = feature_t.mean() # �������channel��mean# ѵ�����������std_t1 = feature_t.std() # �������channel��std# ���ԣ���������std_t2 = feature_t.std(ddof=1)# bn �Ե�i��channel��ÿһ��Ԫ�� ����norm ��ʼ٤��=1 ����=0feature[:, i, :, :] = (feature[:, i, :, :] - mean_t) / std_t1# update calculating mean and var ��¼��mean��var���ڲ��Լ���# ѵ��ʱʹ��������� ����ʱʹ����������# 0.1Ϊmomentummean[i] = mean[i] * (1-0.1) + mean_t * 0.1var[i] = var[i] * (1-0.1) + (std_t2 ** 2) * 0.1return feature, mean, varif __name__ == '__main__':random.seed(1)# �������һ��batchΪ2��channelΪ2��height=width=2����������# [batch, channel, height, width]feature = torch.randn(2, 2, 2, 2)print("=============feature================")print(feature)# ��ʼ��ͳ�ƾ�ֵ�ͷ���mean = [0.0, 0.0]variance = [1.0, 1.0]# print(feature1.numpy())# # ע��Ҫʹ��copy()���feature_bn, mean_bn, variance_bn = BN(feature.numpy().copy(), mean, variance)print("================feature_bn_myself================")print(feature_bn)print("================mean================")print(mean_bn)print("================variance================")print(variance_bn)#bn = nn.BatchNorm2d(2)output = bn(feature)print("================feature_bn_pytorch================")print(output)
���룺

����ľ�ֵ�ͷ��

�Լ�д��BN�����

���ùٷ���BN�����

5��BN���ŵ��ܽ�
- ���μ��ˣ�����Ȩ�س�ʼ��Ҫ��û��ô��
- ��������Ч�������Բ���ʹ��Dropout��Ҳ���Բ���ʹ��L2����
- ����ʹ�ô��ѧϰ�ʶ�û���κθ����ã����ļ�����ѵ��
- һ���̶Ȼ�������������С��ݶ���ɢ�������ֲ���ɢ����������
- ������Internal Covariate Shift(�ڲ�Э����ƫ��)����
- ������������ģ�;��ȡ�
�ܶ���֮��������ô�ı任�������ĺô���úܣ���Ҳ��Ϊ������BN��ô������������ԭ��
6��ʹ��BN��ע������
- ѵ��ʱҪ��traning��������ΪTrue������֤ʱ��trainning��������ΪFalse����pytorch�п�ͨ������ģ�͵�model.train()��model.eval()�������ơ�
- batch size���������ô�㣬����С����ֿ��ܺ���⣬���õ�Խ����ľ�ֵ�ͷ���Խ�ӽ�����ѵ�����ľ�ֵ�ͷ��
- ���齫bn����ھ����㣨Conv���ͼ���㣨����Relu��֮�䣬�Ҿ����㲻Ҫʹ��ƫ��bias����Ϊû���ã�����������������

����CBN
���ģ�https://arxiv.org/abs/2002.05712.
Դ�룺CBN.py.
2.1������
���Ͻ�BN��ѧϰ���ǿ���֪��BN�кܶ�ܶ���ŵ㣬���磺
- ��Ȩ�س�ʼ����Ҫ��û��ô����
- ����ʹ�ø����ѧϰ�ʽ���ѵ�����Ӵ���ѵ�����ٶ�
- һ���̶��ϻ������ݶ���ʧ������
- ������ڲ�Э����ƫ�Ƶ�����
- ������һ�����������ã����Բ���ʹ��DropOut
- ��������������ģ�͵ľ���
���ǣ�BN��һ��������ȱ�ݣ��Ǿ������������BN��ʱ����һ��ǰ���������ǵ�batch_size�㹻���ʱ����mini-batch�����BN��������\mu������\sigma���������Ƶ����������ݼ���BN���������ǵ�batch_size��С��ʱ��BN��Ч����ܲ����ͼ1��BN�ߣ�����batch_size�ļ�С��BN�ı��������
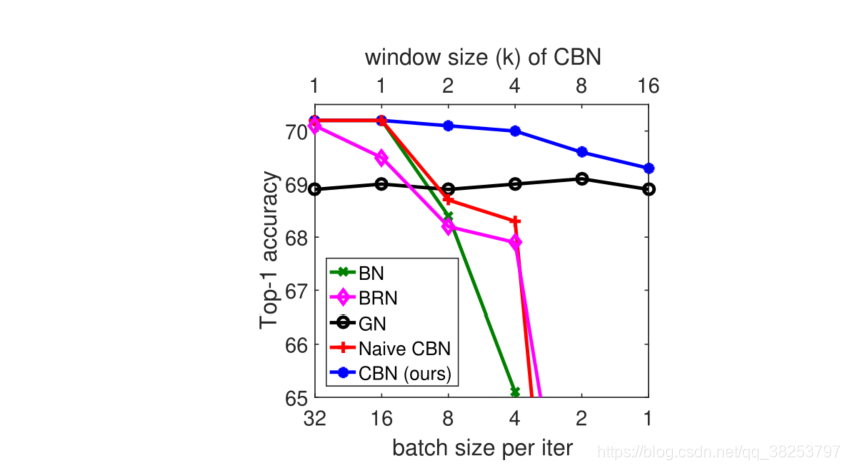
���������⣬�ܶ�ѧ�ߴӿռ�Ƕ����˺ܶ�ij��ԣ�����LN��IN��GN�ȣ�������Щ����������Բ�ͬ������ģ����߱�һ���������ԡ�����CBN�ı���˼·��ϣ����ʱ��ά�ȳ��Խ��������⣺batch_size̫С�������ϻ�������̫�ٲ����Խ�������ѵ������BN�������Ǿ�ͨ������ǰ����iteration����õ�BN��������\mu������\sigma������һ�����������iter��BN������
����1��������ǰ����iteration����õ�BN��������\mu������\sigma�������������iter��BN�����ķ�������һ�����⣺��ȥ��BN�������ɹ�ȥ����������������feature map�ټ���õ��ģ������ֵ���ʱ����BN����ʱ�ҵIJ�����ʵ�Ѿ���ʱ�ˣ���ͼ1�� Native CBN��ֱ������ǰ�����������������ǰ��BN����Ч�������ã�
Ϊ�˽��������⣬����������̩�չ�ʽ����Ϊ�����ݶ��½��Ļ��ƣ�ģ����ѵ�������������iteration����Ӧ��ģ�Ͳ����ı仯��ƽ���ģ��������ǿ�����̩�չ�ʽ��������ǰ�����������
2.2��̩�չ�ʽ����
����BN��
x^t,i(��t)=xt,i(��t)?��t(��t)��(��t)2+��(1)\hat{x}_{t,i}(\theta_t)=\frac{x_{t,i}(\theta_t)-\mu_t(\theta_t)}{\sqrt{\sigma(\theta_t)^2+\varepsilon}}\qquad (1)x^t,i?(��t?)=��(��t?)2+��?xt,i?(��t?)?��t?(��t?)?(1) ��t(��t)=1m��i=1mxt,i(��t)(2)\mu_t(\theta_t)=\frac{1}{m}\sum_{i=1}^m {x}_{t,i}(\theta_t)\qquad (2)��t?(��t?)=m1?i=1��m?xt,i?(��t?)(2) ��(��t)=1m��i=1m(xt,i(��t)?��t(��t))2=��t(��t)?��t(��t)2(3)\sigma(\theta_t)=\sqrt{\frac{1}{m}\sum_{i=1}^m({x}_{t,i}(\theta_t)-\mu_t(\theta_t))^2} = \sqrt{\nu_t(\theta_t)-\mu_t(\theta_t)^2}\qquad (3)��(��t?)=m1?i=1��m?(xt,i?(��t?)?��t?(��t?))2?=��t?(��t?)?��t?(��t?)2?(3)
��t(��t)=1m��i=1mxt,i(��t)2(4)\nu_t(\theta_t)=\frac{1}{m}\sum_{i=1}^m x_{t,i}(\theta_t)^2 \qquad (4)��t?(��t?)=m1?i=1��m?xt,i?(��t?)2(4)
yt,i(��t)=��x^t,i(��t)+��(5)y_{t,i}(\theta_t)=\gamma \hat{x}_{t,i}(\theta_t)+\beta \qquad (5)yt,i?(��t?)=��x^t,i?(��t?)+��(5)
����:
��t\theta_t��t?��ʾ�� ttt ��mini-batch �����������
xt,i(��t)x_{t,i}(\theta_t)xt,i?(��t?)��ʾ��ttt��mini-batch�е�i������������õ���feature map��
x^t,i(��t)\hat{x}_{t,i}(\theta_t)x^t,i?(��t?)��ʾfeature map�е�i��������BN��õ�����������feature map����ֵΪ0�� ����Ϊ1����
��t(��t)\mu_t(\theta_t)��t?(��t?)����(��t)\sigma(\theta_t)��(��t?)��ʾ��ǰmini-batch��������ľ�ֵ�ͷ��� ��\varepsilon��Ϊ��0ϵ��;
��\gamma���� ��\beta����BN��Ҫѧϰ�IJ�����
m��ʾmini-batch����m������
ʹ��̩�չ�ʽ����֮ǰiter�ľ�ֵ�ͷ��
���������ǵ� ttt �ε���������Ҫ��֮ǰ�ĵ� (t?��)(t-\tau)(t?��) �ε����ľ�ֵ�ͷ���
����֮ǰ��������ľ�ֵ�ͷ������֮ǰ�������������t?��\theta_{t-\tau}��t?��?������õ��� => ��t(��t)\mu_t(\theta_t)��t?(��t?)����t(��t)\nu_t(\theta_t)��t?(��t?)
��Ϊ�����ַ����������ε�������������ı仯��ƽ���ģ����Ը���̩�չ�ʽչ��ʽ���Թ���������������
��t?��(��t)=��t?��(��t?��)+?��t?��(��t?��)?��t?��(��t?��t?��)+O(�O�O��t?��t?�ӨO�O2)(6)\mu_{t-\tau(\theta_t)}= \mu_{t-\tau}(\theta_{t-\tau})+ \frac{\partial \mu_{t-\tau}(\theta_{t-\tau})}{\partial \theta_{t-\tau}} (\theta_t-\theta_{t-\tau}) +O(|| \theta_t-\theta_{t-\tau} ||^2) \qquad (6)��t?��(��t?)?=��t?��?(��t?��?)+?��t?��??��t?��?(��t?��?)?(��t??��t?��?)+O(�O�O��t??��t?��?�O�O2)(6)
��t?��(��t)=��t?��(��t?��)+?��t?��(��t?��)?��t?��(��t?��t?��)+O(�O�O��t?��t?�ӨO�O2)(7)\nu_{t-\tau}(\theta_t)= \nu_{t-\tau}(\theta_{t-\tau})+\frac{\partial \nu_{t-\tau}(\theta_{t-\tau})}{\partial \theta_{t-\tau}} (\theta_t-\theta_{t-\tau}) +O(|| \theta_t-\theta_{t-\tau} ||^2) \qquad (7)��t?��?(��t?)=��t?��?(��t?��?)+?��t?��??��t?��?(��t?��?)?(��t??��t?��?)+O(�O�O��t??��t?��?�O�O2)(7)
����?��t?��(��t?��)?��t?��\frac{\partial \mu_{t-\tau}(\theta_{t-\tau})}{\partial \theta_{t-\tau}}?��t?��??��t?��?(��t?��?)?��?��t?��(��t?��)?��t?��\frac{\partial \nu_{t-\tau}(\theta_{t-\tau})}{\partial \theta_{t-\tau}}?��t?��??��t?��?(��t?��?)?Ϊ��(t?��)(t-\tau)(t?��)�ε�����BN�����Ե�(t?��)(t-\tau)(t?��)�ε��������������ƫ����
��O(�O�O��t?��t?�ӨO�O2)O(|| \theta_t-\theta_{t-\tau} ||^2)O(�O�O��t??��t?��?�O�O2)��ʾ̩��չ��ʽ�ĸ߽��������t?��t?�ӣ���\theta_t-\theta_{t-\tau}������t??��t?��?����Сʱ���߽�����Ժ��Բ���
����Ҫ��ȷ�����?��?��(��t?��)?��t?��\frac{\partial \mu- \tau(\theta_{t-\tau})}{\partial \theta_{t-\tau}}?��t?��??��?��(��t?��?)?��?��?��(��t?��)?��t?��\frac{\partial \nu- \tau(\theta_{t-\tau})}{\partial \theta_{t-\tau}}?��t?��??��?��(��t?��?)?�ļ�������ܴ���Ϊ��t?��l(��t?��)\mu^l_{t-\tau}(\theta_{t-\tau})��t?��l?(��t?��?)�� ��t?��l(��t?��)\nu^l_{t-\tau}(\theta_{t-\tau})��t?��l?(��t?��?)������֮ǰ���в������Ȩ�أ�Ҫ��l���Ҫ����l��֮ǰ�����в㣩
ʵ���ϣ�����ͨ��ʵ�鷢�֣���r<=lr<=lr<=l��?��tl(��t)��tr\frac{\partial \mu^l_t(\theta_{t})}{ \theta^r_{t}}��tr??��tl?(��t?)?��?��tl(��t)��tr\frac{\partial \nu^l_t(\theta_{t})}{ \theta^r_{t}}��tr??��tl?(��t?)? ����ٵĺܿ�
���ԣ���������?��tl(��t)��tr\frac{\partial \mu^l_t(\theta_{t})}{ \theta^r_{t}}��tr??��tl?(��t?)?��?��tl(��t)��tr\frac{\partial \nu^l_t(\theta_{t})}{ \theta^r_{t}}��tr??��tl?(��t?)?ʱ������ֱ�Ӻ��� l ��֮ǰ�IJ�� l ���Ӱ��
���գ�����̩�չ�ʽ���Խ���Ϊ��
��t?��l(��t)�֦�t?��(��t?��)l+?��t?��l(��t?��)?��t?��l(��tl?��t?��l)(8){\mu^l_{t-\tau}(\theta_t) \approx \mu^l_{t-\tau(\theta_{t-\tau})}+ \frac{\partial \mu^l_{t-\tau}(\theta_{t-\tau})}{\partial \theta^l_{t-\tau}} (\theta^l_t-\theta^l_{t-\tau}) \qquad (8)} ��t?��l?(��t?)����t?��(��t?��?)l?+?��t?��l??��t?��l?(��t?��?)?(��tl??��t?��l?)(8)
��t?��l(��t)�֦�t?��l(��t?��)+?��t?��l(��t?��)?��t?��l(��tl?��t?��l)(9){ \nu^l_{t-\tau}(\theta_t) \approx \nu^l_{t-\tau}(\theta_{t-\tau})+\frac{\partial \nu^l_{t-\tau}(\theta_{t-\tau})}{\partial \theta^l_{t-\tau}} (\theta^l_t-\theta^l_{t-\tau}) \qquad (9) } ��t?��l?(��t?)����t?��l?(��t?��?)+?��t?��l??��t?��l?(��t?��?)?(��tl??��t?��l?)(9)

2.3��CBNϸ��
Cross-Iteration Batch Normalizationϸ��:
��������֮ǰ�IJ������Ƴ���ǰ������ l ����(t?��)(t-\tau)(t?��)�ε����IJ���ֵ��������Щ����ֵ���Լ������ǰ����ʱ��BN��������\mu������\nu������
�̡�t,kl(��t)=1k�Ʀ�=0k?1��t?��l(��t)(10){\bar{\mu}^l_{t,k} (\theta_t) = \frac{1}{k}\sum_{\tau=0}^{k-1}\mu^l_{t-\tau}(\theta_t) } \qquad (10) ����?t,kl?(��t?)=k1?��=0��k?1?��t?��l?(��t?)(10)
�͡�t,kl(��t)=1k�Ʀ�=0k?1max[��t?��l(��t),��t?��l(��t)2](11){\bar \nu^l_{t,k}(\theta_t) = \frac{1}{k}\sum_{\tau=0}^{k-1}max[\nu^l_{t-\tau}(\theta_t), \mu^l_{t-\tau}(\theta_t)^2]}\qquad (11) ����t,kl?(��t?)=k1?��=0��k?1?max[��t?��l?(��t?),��t?��l?(��t?)2](11)
�ҡ�t,kl(��t)=�͡�t,kl(��t)?�̡�t,kl(��t)2(12)\bar\sigma^l_{t,k}(\theta_t)= \sqrt{\bar\nu^l_{t,k}(\theta_t)-\bar\mu^l_{t,k}(\theta_t)^2} \qquad (12) ����t,kl?(��t?)=����t,kl?(��t?)?����?t,kl?(��t?)2?(12)
����ʽ10������iteration[t?�ӣ�t]iteration[t-\tau��t]iteration[t?����t]�ֵ�����ֵ��ƽ����
ʽ11������Чͳ������t?��l(��t)�ݦ�t?��l(��t)2\nu^l_{t-\tau}(\theta_t) \geq \mu^l_{t-\tau}(\theta_t)^2��t?��l?(��t?)����t?��l?(��t?)2��һֱ����ģ���������̩��չ��ʽ����Ͳ�һ�������ˣ������ڴ�������Ĭ�Ϲ��˵������������ģ������г��������Ի�ȡ��Ϣ�������塣
���CBN����featute map����ͬCN:
x^t,il(��t)=xt,il(��t)?u��t,kl(��t)�ҡ�t,kl(��t)2+?(13)\hat{x}^l_{t,i}(\theta_t)=\frac{x^l_{t,i}(\theta_t)-\bar{u}^l_{t,k}(\theta_t)}{\sqrt{\bar{\sigma}^l_{t,k}(\theta_t)^2 + \epsilon}} \qquad (13)x^t,il?(��t?)=����t,kl?(��t?)2+??xt,il?(��t?)?u��t,kl?(��t?)?(13)

ͬʱ����ָ��CBN������������Ƚϴ���ڴ濪����ѵ���ٶȲ���Ӱ��ܶ࣬����һ��㡣
2.4������ʵ��
class CBatchNorm2d(nn.Module):def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,track_running_stats=True,buffer_num=0, rho=1.0,burnin=0, two_stage=True,FROZEN=False, out_p=False):super(CBatchNorm2d, self).__init__()self.num_features = num_featuresself.eps = epsself.momentum = momentumself.affine = affineself.track_running_stats = track_running_statsself.buffer_num = buffer_numself.max_buffer_num = buffer_numself.rho = rhoself.burnin = burninself.two_stage = two_stageself.FROZEN = FROZENself.out_p = out_pself.iter_count = 0self.pre_mu = []self.pre_meanx2 = [] # mean(x^2)self.pre_dmudw = []self.pre_dmeanx2dw = []self.pre_weight = []self.ones = torch.ones(self.num_features)if self.affine:self.weight = Parameter(torch.Tensor(num_features))self.bias = Parameter(torch.Tensor(num_features))else:self.register_parameter('weight', None)self.register_parameter('bias', None)if self.track_running_stats:self.register_buffer('running_mean', torch.zeros(num_features))self.register_buffer('running_var', torch.ones(num_features))else:self.register_parameter('running_mean', None)self.register_parameter('running_var', None)self.reset_parameters()def reset_parameters(self):if self.track_running_stats:self.running_mean.zero_()self.running_var.fill_(1)if self.affine:self.weight.data.uniform_()self.bias.data.zero_()def _check_input_dim(self, input):if input.dim() != 4:raise ValueError('expected 4D input (got {
}D input)'.format(input.dim()))def _update_buffer_num(self):if self.two_stage:if self.iter_count > self.burnin:self.buffer_num = self.max_buffer_numelse:self.buffer_num = 0else:self.buffer_num = int(self.max_buffer_num * min(self.iter_count / self.burnin, 1.0))def forward(self, input, weight):# deal with wight and grad of self.pre_dxdw!self._check_input_dim(input)y = input.transpose(0, 1)return_shape = y.shapey = y.contiguous().view(input.size(1), -1)# burninif self.training and self.burnin > 0:self.iter_count += 1self._update_buffer_num()if self.buffer_num > 0 and self.training and input.requires_grad: # some layers are frozen!# cal current batch mu and sigmacur_mu = y.mean(dim=1)cur_meanx2 = torch.pow(y, 2).mean(dim=1)cur_sigma2 = y.var(dim=1)# cal dmu/dw dsigma2/dwdmudw = torch.autograd.grad(cur_mu, weight, self.ones, retain_graph=True)[0]dmeanx2dw = torch.autograd.grad(cur_meanx2, weight, self.ones, retain_graph=True)[0]# update cur_mu and cur_sigma2 with presmu_all = torch.stack([cur_mu, ] + [tmp_mu + (self.rho * tmp_d * (weight.data - tmp_w)).sum(1).sum(1).sum(1) fortmp_mu, tmp_d, tmp_w in zip(self.pre_mu, self.pre_dmudw, self.pre_weight)])meanx2_all = torch.stack([cur_meanx2, ] + [tmp_meanx2 + (self.rho * tmp_d * (weight.data - tmp_w)).sum(1).sum(1).sum(1) fortmp_meanx2, tmp_d, tmp_w inzip(self.pre_meanx2, self.pre_dmeanx2dw, self.pre_weight)])sigma2_all = meanx2_all - torch.pow(mu_all, 2)# with considering countre_mu_all = mu_all.clone()re_meanx2_all = meanx2_all.clone()re_mu_all[sigma2_all < 0] = 0re_meanx2_all[sigma2_all < 0] = 0count = (sigma2_all >= 0).sum(dim=0).float()mu = re_mu_all.sum(dim=0) / countsigma2 = re_meanx2_all.sum(dim=0) / count - torch.pow(mu, 2)self.pre_mu = [cur_mu.detach(), ] + self.pre_mu[:(self.buffer_num - 1)]self.pre_meanx2 = [cur_meanx2.detach(), ] + self.pre_meanx2[:(self.buffer_num - 1)]self.pre_dmudw = [dmudw.detach(), ] + self.pre_dmudw[:(self.buffer_num - 1)]self.pre_dmeanx2dw = [dmeanx2dw.detach(), ] + self.pre_dmeanx2dw[:(self.buffer_num - 1)]tmp_weight = torch.zeros_like(weight.data)tmp_weight.copy_(weight.data)self.pre_weight = [tmp_weight.detach(), ] + self.pre_weight[:(self.buffer_num - 1)]else:x = ymu = x.mean(dim=1)cur_mu = musigma2 = x.var(dim=1)cur_sigma2 = sigma2if not self.training or self.FROZEN:y = y - self.running_mean.view(-1, 1)# TODO: outside **0.5?if self.out_p:y = y / (self.running_var.view(-1, 1) + self.eps) ** .5else:y = y / (self.running_var.view(-1, 1) ** .5 + self.eps)else:if self.track_running_stats is True:with torch.no_grad():self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * cur_muself.running_var = (1 - self.momentum) * self.running_var + self.momentum * cur_sigma2y = y - mu.view(-1, 1)# TODO: outside **0.5?if self.out_p:y = y / (sigma2.view(-1, 1) + self.eps) ** .5else:y = y / (sigma2.view(-1, 1) ** .5 + self.eps)y = self.weight.view(-1, 1) * y + self.bias.view(-1, 1)return y.view(return_shape).transpose(0, 1)def extra_repr(self):return '{
num_features}, eps={
eps}, momentum={
momentum}, affine={
affine}, ' \'buffer={
max_buffer_num}, burnin={
burnin}, ' \'track_running_stats={
track_running_stats}'.format(**self.__dict__)
����CmBN(������)

- BN���Ե�ǰmini-batch���й�һ��
- CBN: �Ե�ǰ�Լ���ǰ��ǰ��3��mini-batch�Ľ�����й�һ��
- CmBN: CmBN ������������ʹ��Cross min-batch Normalization �ռ�ͳ�����ݣ������ڵ�����mini-batch���ռ�ͳ������
Reference
- BN1.
- BN2.
- BN3.
- BN4.
- CBN1.
- CBN2.