Ŀ¼
- ǰ��
- 0��������Ҫ�İ�
- 1��smooth_BCE
- 2��BCEBlurWithLogitsLoss
- 3��FocalLoss
- 4��QFocalLoss
- 5��ComputeLoss��
-
- 5.1��__init__����
- 5.2��build_targets
- 5.3��__call__����
- �ܽ�
- Reference
ǰ��
Դ�룺 YOLOv5Դ��.
����: ��YOLOV5-5.x Դ�뽲�⡿������Ŀ�ļ�����.
ע�Ͱ�ȫ����Ŀ�ļ����ϴ���GitHub: yolov5-5.x-annotations.
����ļ���yolov5����ʧ�������֡����������ֻ࣬��300���У���ȴ��������Ŀ���ѣ�����IJ��֡��ڿ�����ļ�֮ǰ��������ϸ����������ƪ����BCE��������ʧ���������ݣ� ��PyTorch ���ۡ���������ʧ���������� �� ��PyTorch�����ֳ��õĽ�������ʧ����BCELoss��BCEWithLogitsLoss �����⣬����ļ��漰������ʧ�����ļ��㡢��������ȡ����ƽ����ǩ��ǿ��Focalloss��QFocalloss�Ȳ��������DZȽϳ��õ�trick��һ����ҪŪ����
0��������Ҫ�İ�
import torch
import torch.nn as nnfrom utils.metrics import bbox_iou
from utils.torch_utils import is_parallel
1��smooth_BCE
���������һ����ǩƽ���IJ���(trick)����һ���� ����/��� �����У���ֹ����ϵķ��������Ҫ��ϸ����������Ե�ԭ�������Կ����ҵ���һƪ����: ��trick 1��Label Smoothing����ǩƽ�������� ���������д����ע��һ�ֽ������.
smooth_BCE��������:
def smooth_BCE(eps=0.1):"""����ComputeLoss���б�ǩƽ������ [1, 0] => [0.95, 0.05]https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441:params eps: ƽ������:return positive, negative label smoothing BCE targets ����ֵ�ֱ�����������������ı�ǩȡֵԭ�ȵ�������=1 ������=0 ��Ϊ ������=1.0 - 0.5 * eps ������=0.5 * eps"""return 1.0 - 0.5 * eps, 0.5 * eps
ͨ�������ڷ�����ʧ���У�����ComputeLoss���__init__�������壺

ComputeLoss���__call__�������ã�

2��BCEBlurWithLogitsLoss
���������BCE������һ���������yolov5���ߵ�һ��ʵ���Եĺ����������Լ�����Ч����
class BCEBlurWithLogitsLoss(nn.Module):"""����ComputeLoss���__init__������BCEwithLogitLoss() with reduced missing label effects.https://github.com/ultralytics/yolov5/issues/1030The idea was to reduce the effects of false positive (missing labels) ���Ǽ����������� ���Ǽ�����"""def __init__(self, alpha=0.05):super(BCEBlurWithLogitsLoss, self).__init__()self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()self.alpha = alphadef forward(self, pred, true):loss = self.loss_fcn(pred, true)pred = torch.sigmoid(pred) # prob from logits# dx = [-1, 1] ��pred=1 true=0ʱ(����Ԥ��˵�����и�obj����gt˵����û��), dx=1 => alpha_factor=0 => loss=0# ���־��Ǽ����������˵��Ǽ����ˣ�false positive������missing label����� ���������Ӧ�ù���ijͷ�->loss=0dx = pred - true # reduce only missing label effects# �����������ֵ�Ļ� �����pred��gt����������ɵ�Ӱ��# dx = (pred - true).abs() # reduce missing label and false label effectsalpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))loss *= alpha_factorreturn loss.mean()
ʹ������ֱ����ComputeLoss���__init__�����������ͳ��BCE�������ɣ�

3��FocalLoss
FocalLoss��ʧ�������� Kaiming He��2017�귢����һƪ���ģ�Focal Loss for Dense Object Detection. ��ƪ������Ƶ���Ҫ˼·: ϣ����Щhard examples����ʧ�Ĺ��ױ��ʹ����������ڴ���Щ������ѧϰ����ֹ����easy examples���࣬����������ʧ������
�ŵ㣺
- �����one-stage object detection��ͼƬ������������ǰ���ͱ���������������⣻
- ���ͼ�������Ȩ�أ�ʹ��ʧ��������ע����������
������ʽ��

����ϸ���뿴�ҵ���һƪ���ͣ� ��trick 4��Focal Loss ���� ���one-stageĿ�������������������������.
FocalLoss�������룺
class FocalLoss(nn.Module):"""���ڴ���ԭ����BCEcls��������ʧ����BCEobj�����Ŷ���ʧ��Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)����: https://arxiv.org/abs/1708.02002https://blog.csdn.net/qq_38253797/article/details/116292496TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py"""def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):super(FocalLoss, self).__init__()self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()=Sigmoid+BCELoss ����Ϊ����ཻ������ʧ����self.gamma = gamma # ����gamma ����������������loss�Ĺ��׳̶�self.alpha = alpha # ����alpha ����ƽ�������������������������# self.reduction: ����FocalLoss��ʧ���ģʽ sum/mean/none Ĭ����Meanself.reduction = loss_fcn.reduction# focalloss�е�BCE������reduction='None' BCE��ʹ��Sum����Meanself.loss_fcn.reduction = 'none' # ��Ҫ��Focal lossӦ����ÿһ������֮��def forward(self, pred, true):loss = self.loss_fcn(pred, true) # ����BCE��loss: loss = -log(p_t)# p_t = torch.exp(-loss)# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stabilitypred_prob = torch.sigmoid(pred) # prob from logits# true=1 p_t=pred_prob true=0 p_t=1-pred_probp_t = true * pred_prob + (1 - true) * (1 - pred_prob) # p_t# true=1 alpha_factor=self.alpha true=0 alpha_factor=1-self.alphaalpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha) # alpha_tmodulating_factor = (1.0 - p_t) ** self.gamma # �������Focal loss�е�ָ����# �������յ�loss=BCE * �������� (������ʽ������ ��ʽһģһ��)loss *= alpha_factor * modulating_factor# ���ѡ��focalloss���ص����� Ĭ����meanif self.reduction == 'mean':return loss.mean()elif self.reduction == 'sum':return loss.sum()else: # 'none'return loss
����������ڴ���ԭ����BCEcls��BCEobj:

4��QFocalLoss
QFocalLoss��ʧ��������20���һƪ���£� Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection.
��ƪ��������ʱ��û�п��꣬��Ϊ�漰̫���anchor free�����ݣ�����ѧ��anchor free��һЩ���������ٻ�����д��
�������ƪ���ĸ���Ȥ���Կ������ͣ� ��� Generalized Focal Loss.
��ʽ��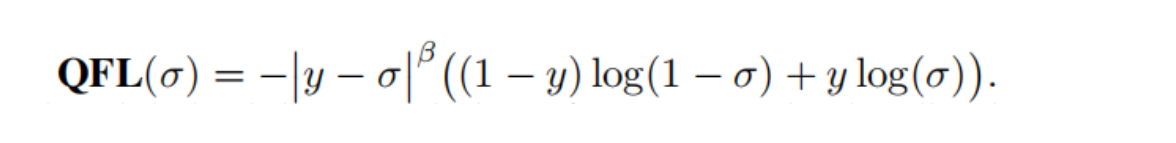
QFocalLoss�������룺
class QFocalLoss(nn.Module):"""��������FocalLossQFocalLoss ����General Focal Loss����: https://arxiv.org/abs/2006.04388Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)"""def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):super(QFocalLoss, self).__init__()self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()self.gamma = gammaself.alpha = alphaself.reduction = loss_fcn.reductionself.loss_fcn.reduction = 'none' # required to apply FL to each elementdef forward(self, pred, true):loss = self.loss_fcn(pred, true)pred_prob = torch.sigmoid(pred) # prob from logitsalpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)# ��FocalLoss���ֻ��������modulating_factor = torch.abs(true - pred_prob) ** self.gammaloss *= alpha_factor * modulating_factorif self.reduction == 'mean':return loss.mean()elif self.reduction == 'sum':return loss.sum()else: # 'none'return loss
�÷�����ֱ����ComputeLossʱ����FocalLoss���ɣ�

5��ComputeLoss��
5.1��__init__����
����������Ƕ���һЩ����Ҫ�õ��ı����������������ȡ�
def __init__(self, model, autobalance=False):super(ComputeLoss, self).__init__()self.sort_obj_iou = False # ����ɸѡ���Ŷ���ʧ��������ʱ���Ƿ��ȶ�iou����device = next(model.parameters()).device # get model deviceh = model.hyp # hyperparameters# Define criteria ���������ʧ�����Ŷ���ʧ# BCEcls = BCEBlurWithLogitsLoss()# BCEobj = BCEBlurWithLogitsLoss()# h['cls_pw']=1 BCEWithLogitsLossĬ�ϵ�������Ȩ��Ҳ��1BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))# ��ǩƽ�� eps=0����������ǩƽ��-> cp=1 cn=0 eps!=0��������ǩƽ�� cp����positive�ı�ǩֵ cn����negative�ı�ǩֵself.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets# Focal loss g=0 ��������focal lossg = h['fl_gamma'] # focal loss gammaif g > 0:# g>0 ��������ʧ�����Ŷ���ʧ(BCE)������focalloss��ʧ����BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)# BCEcls, BCEobj = QFocalLoss(BCEcls, g), QFocalLoss(BCEobj, g)# det: ���ص���ģ�͵ļ��ͷ Detector 3�� �ֱ��Ӧ�����������feature mapdet = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module# balance������������feature map��Ӧ��������Ŷ���ʧϵ��(ƽ������feature map�����Ŷ���ʧ)# �����ҷֱ��Ӧ��feature map(���СĿ��)��Сfeature map(����Ŀ��)# ˼·: It seems that larger output layers may overfit earlier, so those numbers may need a bit of adjustment# һ����˵�����С������Ѷȴ�һ�㣬���Ի����Ӵ�����ͼ����ʧϵ������ģ���Ӳ���С����ļ��# ���det.nl=3�ͷ���[4.0, 1.0, 0.4]����[4.0, 1.0, 0.25, 0.06, .02]# self.balance = {3: [4.0, 1.0, 0.4], 4: [4.0, 1.0, 0.25, 0.06], 5: [4.0, 1.0, 0.25, 0.06, .02]}[det.nl]self.balance = {
3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, .02]) # P3-P7# ����Ԥ��ͷ���²�����det.stride: [8, 16, 32] .index(16): ����²�����stride=16������# ��������������Զ��������3��feature map�����Ŷ���ʧϵ��self.balanceself.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index# self.BCEcls: �����ʧ���� self.BCEobj: ���Ŷ���ʧ���� self.hyp: ������# self.gr: ������ʵ������Ŷȱ���iou ratio self.autobalance: �Ƿ��Զ����¸�feature map�����Ŷ���ʧƽ��ϵ�� Ĭ��Falseself.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, model.gr, h, autobalance# na: number of anchors ÿ��grid_cell��anchor���� = 3# nc: number of classes ���ݼ�������� = 80# nl: number of detection layers Detect�ĸ��� = 3# anchors: [3, 3, 2] 3��feature map ÿ��feature map����3��anchor(w,h) �����anchor�ߴ������feature map��for k in 'na', 'nc', 'nl', 'anchors':# setattr: ������self������k��ֵΪgetattr(det, k)# getattr: ����det�����k����# ������仰����˼: ��det��k���Ը�ֵ��self.k���� ����k in 'na', 'nc', 'nl', 'anchors'setattr(self, k, getattr(det, k))
5.2��build_targets
�������������Ϊ����GTɸѡ��Ӧ��anchor��������ɸѡ�����DZȽ�GT��anchor�Ŀ��Ⱥ߱ȣ�����һ������ֵ���Ǹ���������֮��������ɸѡ������������Ϣ��image_index, anchor_index, gridy, gridx��������__call__������ͨ�������Ϣȥɸѡpredÿ��gridԤ��õ�����Ϣ��������Ӧgrid_cell�ϵ���������ͨ��build_targetsɸѡ��GT�е���������predɸѡ���Ķ�Ӧλ�õ�Ԥ���������м�����ʧ��
�������⣺���������Ŀ����Ϊ��ÿ��gtƥ����Ӧ�ĸ�����anchor������������ʧ���㣬j = torch.max(r, 1. / r).max(2)[0] < self.hyp[��anchor_t��]�ⲽ�ıȽ���Ϊ�˽�gt���䵽��ͬ����ȥ��⣨����˵�IJ�ࣩ������IJ�����Ϊ�˽�ȷ����������gt�������꣬����ȷ�����gt������ĸ�grid cell���м�⡣������һ��Ҳ��������Ϊÿ��gtƥ��anchor��������Ŀ�ġ�
def build_targets(self, p, targets):"""����GTɸѡ��Ӧ��anchor������Build targets for compute_loss():params p: p[i]������ֻ�ǵõ�ÿ��feature map��shapeԤ��� ��ģ�����е��������ͷDetector���ص�����yolo������tensor��ʽ list�б� �������tensor ��Ӧ��������yolo��������: [4, 3, 112, 112, 85]��[4, 3, 56, 56, 85]��[4, 3, 28, 28, 85][bs, anchor_num, grid_h, grid_w, xywh+class+classes]���Կ����������Ԥ��ֵp������yolo��ÿ��grid_cell(ÿ��grid_cell������Ԥ��ֵ)��Ԥ��ֵ,����϶�Ҫ����������ɸѡ:params targets: ������ǿ�����ʵ�� [63, 6] [num_target, image_index+class+xywh] xywhΪ��һ����Ŀ�:return tcls: ��ʾ���target������class indextbox: xywh ����xyΪ���target�Ե�ǰgrid_cell���Ͻǵ�ƫ����indices: b: ��ʾ���target���ڵ�image indexa: ��ʾ���targetʹ�õ�anchor indexgj: ����ɸѡ��ȷ��ij��target��ij�������н���Ԥ��(������ʧ) gj��ʾ�����������Ͻ�y����gi: ��ʾ�����������Ͻ�x����anch: ��ʾ���target��ʹ��anchor�ij߶ȣ���������feature map�� ע�����һ��target��ʹ�ô�С��ͬanchor���м���"""na, nt = self.na, targets.shape[0] # number of anchors 3, targets 63tcls, tbox, indices, anch = [], [], [], [] # ��ʼ��tcls tbox indices anch# gain��Ϊ�˺��潫targets=[na,nt,7]�еĹ�һ���˵�xywhӳ�䵽���feature map�߶���# 7: image_index+class+xywh+anchor_indexgain = torch.ones(7, device=targets.device)# ��Ҫ��3��anchor�϶�����ѵ�� ���Խ���ǩ��ֵna=3�� ai����3��anchor�������е�target��Ӧ��anchor���� ������������µ�ǰ���target�����ĸ�anchor# [1, 3] -> [3, 1] -> [3, 63]=[na, nt] ���� ��һ��63��0 �ڶ���63��1 ������63��2ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)# [63, 6] [3, 63] -> [3, 63, 6] [3, 63, 1] -> [3, 63, 7] 7: [image_index+class+xywh+anchor_index]# ��ÿһ��feature map: ��һ���ǽ�target�������� ��Ӧһ��feature map������anchor# �ȼ������е�target������������anchor���м��(��������) �ٽ���ɸѡ ����ai�ӽ�ȥ��ǵ�ǰ���ĸ�anchor��targettargets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices# ������������������չ�������� ��ΪԤ���Ԥ�target�п��ܲ�ֹ��ǰ�ĸ���Ԥ���# ������Χ�ĸ���ҲԤ��˸����������� ����ҲҪ���ⲿ�ֵ�Ԥ����Ϣ������������g = 0.5 # bias ����ƫ�� ��������target���ĵ����ĸ����Ӹ���# ������ + ��Χ��������4������ = 5������ ��������offsetsoff = torch.tensor([[0, 0],[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm], device=targets.device).float() * g # offsets# ��������feature ɸѡgt��anchor������for i in range(self.nl): # self.nl: number of detection layers Detect�ĸ��� = 3# anchors: ��ǰfeature map��Ӧ������anchor�ߴ�(���feature map) [3, 2]anchors = self.anchors[i]# gain: ����ÿ�����feature map�Ŀ��� -> gain[2:6]=gain[whwh]# [1, 1, 1, 1, 1, 1, 1] -> [1, 1, 112, 112, 112,112, 1]=image_index+class+xywh+anchor_indexgain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain# t = [3, 63, 7] ��target�е�xywh�Ĺ�һ���߶ȷ�������Ե�ǰfeature map������߶�# [3, 63, image_index+class+xywh+anchor_index]t = targets * gainif nt: # ��ʼƥ�� Matches# t=[na, nt, 7] t[:, :, 4:6]=[na, nt, 2]=[3, 63, 2]# anchors[:, None]=[na, 1, 2]# r=[na, nt, 2]=[3, 63, 2]# ���е�gt�뵱ǰ�������anchor�Ŀ��߱�(w/w h/h)r = t[:, :, 4:6] / anchors[:, None] # wh ratio (w/w h/h)# ɸѡ���� GT��anchor�Ŀ��Ȼ�߱ȳ���һ������ֵ �͵���������# torch.max(r, 1. / r)=[3, 63, 2] ɸѡ������w1/w2 w2/w1 �߱�h1/h2 h2/h1�������Ǹ�# .max(2)���ؿ��� �߱������нϴ��һ��ֵ���������� [0]���ؽϴ��һ��ֵ# j: [3, 63] False: ��ǰanchor�ǵ�ǰgt�ĸ����� True: ��ǰanchor�ǵ�ǰgt��������j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare# yolov3 v4��ɸѡ����: wh_iou GT��anchor��wh_iou����һ������ֵ����������# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))# ����ɸѡ����j, ���˸�����, �õ�����gt��anchor������(batch_size��ͼƬ)# ֪����ǰgt������ ��������ͼƬ ��������Ӧ��idx Ҳ�͵õ��˵�ǰgt��������anchor# t: [3, 63, 7] -> [126, 7] [num_Positive_sample, image_index+class+xywh+anchor_index]t = t[j] # filter# Offsets ɸѡ��ǰ������Χ���� �ҵ�2����target����������������� ������Χ�ĸ���ҲԤ��˸����������� ����ҲҪ���ⲿ�ֵ�Ԥ����Ϣ������������# ����target���ڵĵ�ǰ������, ����2�����Ӷ�Ŀ����м��(������ʧ) Ҳ����˵һ��Ŀ����Ҫ3������ȥԤ��(������ʧ)# ���ȵ�ǰ����������1�� �ٴӵ�ǰ���ӵ����������ĸ�������ѡ��2�� ������������ȥԤ�����Ŀ��(������ʧ)# feature map�ϵ�ԭ�������Ͻ� ����Ϊx�������� ����Ϊy��������gxy = t[:, 2:4] # grid xy ȡtarget���ĵ�����xy(���feature map���Ͻǵ�����)gxi = gain[[2, 3]] - gxy # inverse �õ�target���ĵ���������½ǵ����� gain[[2, 3]]Ϊ��ǰfeature map��wh# ɸѡ�������� ���뵱ǰgrid_cell�����Ϸ�ƫ��С��g=0.5 �� ��������������1(���겻���ڱ��� ��ʱ��û��4��������)# j: [126] bool �����True��ʾ��ǰtarget���ĵ����ڵĸ��ӵ���߸���Ҳ�Ը�target���лع�(�������м�����ʧ)# k: [126] bool �����True��ʾ��ǰtarget���ĵ����ڵĸ��ӵ��ϱ߸���Ҳ�Ը�target���лع�(�������м�����ʧ)j, k = ((gxy % 1. < g) & (gxy > 1.)).T# ɸѡ�������� ���뵱ǰgrid_cell���ҡ��·�ƫ��С��g=0.5 �� ��������������1(���겻���ڱ��� ��ʱ��û��4��������)# l: [126] bool �����True��ʾ��ǰtarget���ĵ����ڵĸ��ӵ��ұ߸���Ҳ�Ը�target���лع�(�������м�����ʧ)# m: [126] bool �����True��ʾ��ǰtarget���ĵ����ڵĸ��ӵ��±߸���Ҳ�Ը�target���лع�(�������м�����ʧ)l, m = ((gxi % 1. < g) & (gxi > 1.)).T# j: [5, 126] torch.ones_like(j): ��ǰ����, ����Ҫɸѡȫ��True j, k, l, m: �������¸��ӵ�ɸѡ���j = torch.stack((torch.ones_like(j), j, k, l, m))# �õ�ɸѡ�����и��ӵ������� ������<=3*126 �����ڱ��ϵȺų���# t: [126, 7] -> ����5��target[5, 126, 7] �ֱ��Ӧ��ǰ���Ӻ��������¸���5������# j: [5, 126] + t: [5, 126, 7] => t: [378, 7] ��������С�ڵ���3����126 ���ҽ���û�б߽�ĸ��ӵȺų���t = t.repeat((5, 1, 1))[j]# torch.zeros_like(gxy)[None]: [1, 126, 2] off[:, None]: [5, 1, 2] => [5, 126, 2]# jɸѡ��: [378, 2] �õ�����ɸѡ��������������������ҪԤ�����ʵ����������߽磨�������±߿�ƫ����offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]else:t = targets[0]offsets = 0# Defineb, c = t[:, :2].long().T # image_index, classgxy = t[:, 2:4] # target��xygwh = t[:, 4:6] # target��whgij = (gxy - offsets).long() # Ԥ����ʵ����������ڵ����Ͻ�����(���������µ�����) gi, gj = gij.T # grid xy indices# Appenda = t[:, 6].long() # anchor index# b: image index a: anchor index gj: ��������Ͻ�y���� gi: ��������Ͻ�x����indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1)))# tbix: xywh ����xyΪ���target�Ե�ǰgrid_cell���Ͻǵ�ƫ����tbox.append(torch.cat((gxy - gij, gwh), 1)) # boxanch.append(anchors[a]) # ��Ӧ������anchorstcls.append(c) # classreturn tcls, tbox, indices, anch
5.3��__call__����
��������൱��forward����������������н�����ʧ������ǰ����
def __call__(self, p, targets): # predictions, targets, model""":params p: Ԥ��� ��ģ�����е��������ͷDetector���ص�����yolo������tensor��ʽ list�б� �������tensor ��Ӧ��������yolo��������: [4, 3, 112, 112, 85]��[4, 3, 56, 56, 85]��[4, 3, 28, 28, 85][bs, anchor_num, grid_h, grid_w, xywh+class+classes]���Կ����������Ԥ��ֵp������yolo��ÿ��grid_cell(ÿ��grid_cell������Ԥ��ֵ)��Ԥ��ֵ,����϶�Ҫ����������ɸѡ:params targets: ������ǿ�����ʵ�� [63, 6] [num_object, batch_index+class+xywh]:params loss * bs: ����batch������ʧ ���з���:params torch.cat((lbox, lobj, lcls, loss)).detach(): �ع���ʧ�����Ŷ���ʧ��������ʧ������ʧ �������ֻ�������ӻ���������Ϣ"""device = targets.device # ȷ�����е��豸# ��ʼ��lcls, lbox, lobj������ʧֵ tensor([0.])lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)# ÿһ������append�� ��feature map�� ÿ�����ǵ�ǰ���feature map��3��anchorɸѡ�������е�target(3��grid_cell����Ԥ��)# tcls: ��ʾ���target������class index# tbox: xywh ����xyΪ���target�Ե�ǰgrid_cell���Ͻǵ�ƫ����# indices: b: ��ʾ���target���ڵ�image index# a: ��ʾ���targetʹ�õ�anchor index# gj: ����ɸѡ��ȷ��ij��target��ij�������н���Ԥ��(������ʧ) gj��ʾ�����������Ͻ�y����# gi: ��ʾ�����������Ͻ�x����# anch: ��ʾ���target��ʹ��anchor�ij߶ȣ���������feature map�� ע�����һ��target��ʹ�ô�С��ͬanchor���м���tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets# ���α�������feature map��Ԥ�����pifor i, pi in enumerate(p): # layer index, layer predictionsb, a, gj, gi = indices[i] # image_index, anchor_index, gridy, gridxtobj = torch.zeros_like(pi[..., 0], device=device) # ��ʼ��target���Ŷ�(��ȫ�Ǹ����� ������ɸѡ��������ֵ)n = b.shape[0] # number of targetsif n:# ��ȷ�õ���b��ͼƬ�ĵ�a��feature map��grid_cell(gi, gj)��Ӧ��Ԥ��ֵ# �����Ԥ��ֵ������ɸѡ�����grid_cell����ʵ�����Ԥ��(������ʧ)ps = pi[b, a, gj, gi] # prediction subset corresponding to targets# Regression loss ֻ���������������Ļع���ʧ# �µĹ�ʽ: pxy = [-0.5 + cx, 1.5 + cx] pwh = [0, 4pw] ��������ڶ���������# Get more positive samples, accelerate convergence and be more stablepxy = ps[:, :2].sigmoid() * 2. - 0.5 # һ����һ������ �������ﲻͬ# https://github.com/ultralytics/yolov3/issues/168pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i] # �������ﲻͬ �����������Լ�����Ĺ�ʽpbox = torch.cat((pxy, pwh), 1) # predicted box# �����tbox[i]�е�xy�����target�Ե�ǰgrid_cell���Ͻǵ�ƫ����[0,1] ��pbox.T��һ����һ����ֵ# ����Ҫ�����ַ�ʽѵ�� ����loss ���ݶ� ��pboxԽ��Խ�ӽ�tbox(ƫ����)iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)lbox += (1.0 - iou).mean() # iou loss# Objectness loss stpe1# iou.detach() �������iou�ݶ� iou�����Ƿ����IJ��� ���Բ���Ҫ�����ݶ���Ϣscore_iou = iou.detach().clamp(0).type(tobj.dtype) # .clamp(0)������ڵ���0# �����iou������������һ���Ż�����һ�����������ֶ��GT�����Ҳ����ͬһ��grid��������gt(�ܼ�������״�������)# There maybe several GTs match the same anchor when calculate ComputeLoss in the scene with dense targetsif self.sort_obj_iou:# https://github.com/ultralytics/yolov5/issues/3605# There maybe several GTs match the same anchor when calculate ComputeLoss in the scene with dense targetssort_id = torch.argsort(score_iou) # score��С�������� �õ���Ӧindex# ����֮�� ���ͬһ��grid��������gt ��ô���Ǿ�������֮��ÿ��grid�е�score_iou���ܱ�֤������# (С�Ļᱻ���� ��Ϊͬһ��grid����϶���ͬ)��ô��ʱ��˳��Ļ�, ���1�����Ǻ�����IOUȥ����LOSS, �ݶȴ���b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]# Ԥ����Ϣ�����Ŷ� ������ʵ����Ϣ��û�����Ŷȵ� ������Ҫ������Ϊ�ĸ�һ�������Ŷ�# self.gr��iou ratio [0, 1] self.grԽ�����Ŷ�Խ�ӽ�iou self.grԽС���Ŷ�Խ�ӽ�1(��Ϊ�Ӵ�ѵ���Ѷ�)tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio# tobj[b, a, gj, gi] = 1 # �������Ԥ���score���� ���ݼ�Ŀ��̫С̫ӵ�� ������������ �����������# Classification loss ֻ���������������ķ�����ʧif self.nc > 1: # cls loss (only if multiple classes)# targets ԭ����������0 ����ʹ��smooth label ����cnt = torch.full_like(ps[:, 5:], self.cn, device=device)t[range(n), tcls[i]] = self.cp # ɸѡ������������Ӧλ��ֵ��cplcls += self.BCEcls(ps[:, 5:], t) # BCE# Append targets to text file# with open('targets.txt', 'a') as file:# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]# Objectness loss stpe2 ���Ŷ���ʧ������������(������ + ������)һ�������ʧ��obji = self.BCEobj(pi[..., 4], tobj)# ÿ��feature map�����Ŷ���ʧȨ�ز�ͬ Ҫ������Ӧ��Ȩ��ϵ��self.balance[i]# һ����˵�����С������Ѷȴ�һ�㣬���Ի����Ӵ�����ͼ����ʧϵ������ģ���Ӳ���С����ļ��lobj += obji * self.balance[i] # obj lossif self.autobalance:# �Զ����¸���feature map�����Ŷ���ʧϵ��self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()if self.autobalance:self.balance = [x / self.balance[self.ssi] for x in self.balance]# ���ݳ����е���ʧȨ�ز��� �Ը�����ʧ����ƽ�� ��ֹ����ʧ��ij����ʧ������lbox *= self.hyp['box']lobj *= self.hyp['obj']lcls *= self.hyp['cls']bs = tobj.shape[0] # batch sizeloss = lbox + lobj + lcls # ƽ��ÿ��ͼƬ������ʧ# loss * bs: ����batch������ʧ# .detach() ������ʧֵ���з��� �����ݶ���Ϣ���µ�����ʧ�����IJ��� ��������ʧ���ֵ�Dz���Ҫ�ݶȷ�����return loss * bs, torch.cat((lbox, lobj, lcls, loss)).detach()
train.py��ʼ����ʧ�����ࣺ

����ִ����ʧ������������ʧ��

�ܽ�
����ű���������Ҫ�ľ���ComputeLoss���ˡ����˺ܾã���������дϸһ��ģ����ǿ�����뷢���Լ�����˵�Ķ��Ѿ�д�ڴ����ע�͵����ˡ�������ʵ����ͦ�ѵģ�����build_target���ֻ�����ڵľ�������϶࣬pytorch������˻ῴ�ıȽ�ʹ�࣬����������ֿ������ҵ�ע���ټ����Լ���debug�Ļ���Ӧ�����ܶ����ġ����һ��Ҫϸ��ComputeLoss��������
��������ű���Ƶ��ļ��������ĺ�������������鿴������YOLOV5-5.x Դ�뽲�⡿������Ŀ�ļ�����.
�C2021.08.09 19:55
Reference
����1: ����1.
����2: ����2.
����3: ����3.
����4: ����4.
����5: ����5.