Ŀ¼
- ǰ��
- 0��������Ҫ�İ��ͻ�������
- 1������opt����
- 2��ִ��main����
- 3��ִ��run����
-
- 3.1���������
- 3.2����ʼ������1
- 3.3������ģ��
- 3.4����ʼ������2
- 3.5������val���ݼ�
- 3.6����ʼ������3
- 3.7����ʼ��֤
-
- 3.7.1��Ԥ����ͼƬ��target
- 3.7.2��model ǰ������
- 3.7.3��������֤����ʧ
- 3.7.4��Run NMS
- 3.7.5��ͳ��ÿ��ͼƬ����ʵ��Ԥ�����Ϣ
- 3.7.6������Ԥ����Ϣ��image_name.txt�ļ�
- 3.7.7������Ԥ����Ϣ��wandb_logger
- 3.7.8����Ԥ����Ϣ���浽coco��ʽ��json�ֵ�
- 3.7.9���������������correct������stats
- 3.7.10������ǰ����batchͼƬ��gt��pred��
- 3.7.11������mAP
- 3.7.12��print��ӡ����ָ��
- 3.7.13����������������wandb_logger��
- 3.7.14��Save JSON
- 3.7.15�� Return results
- �ܽ�
ǰ��
Դ�룺 YOLOv5Դ��.
����: ��YOLOV5-5.x Դ�뽲�⡿������Ŀ�ļ�����.
ע�Ͱ�ȫ����Ŀ�ļ����ϴ���GitHub: yolov5-5.x-annotations.
����ļ���Ҫ����ÿһ��ѵ����������֤��ǰģ�͵�mAP�����������ָ�ꡣ����ļ������ǽ�test.py�ģ����Ҿ��ý�val.py���ܸ���ǡ��Щ�����Ը��ˡ�
ʵ��������ű���õ�Ӧ����ͨ��train.py���� run ������������ͨ��ִ�� val.py �ġ��������˽�����ű���ʱ����ʵ����Ҫ�ľ��� run ������
0��������Ҫ�İ��ͻ�������
import argparse # ���������в���ģ��
import json # ʵ���ֵ��б���JSON�ַ���֮��������
import os # �����ϵͳ���н�����ģ�� �����ļ�·�������ͽ���
import sys # sysϵͳģ�� ��������Python�����������Ļ����йصĺ���
from pathlib import Path # Path��strת��ΪPath���� ʹ�ַ���·�����ڲ�����ģ��
from threading import Thread # �̲߳���ģ��import numpy as np
import torch
import yaml
from tqdm import tqdmFILE = Path(__file__).absolute() # FILE = WindowsPath 'F:\yolo_v5\yolov5-U\val.py'
# ��'F:/yolo_v5/yolov5-U'����ϵͳ�Ļ������� �ýű�������ʧЧ
sys.path.append(FILE.parents[0].as_posix()) # add yolov5/ to pathfrom models.experimental import attempt_load
from utils.datasets import create_dataloader
from utils.general import coco80_to_coco91_class, check_dataset, check_file, check_img_size, check_requirements, \box_iou, non_max_suppression, scale_coords, xyxy2xywh, xywh2xyxy, set_logging, increment_path, colorstr
from utils.metrics import ap_per_class, ConfusionMatrix
from utils.plots import plot_images, output_to_target, plot_study_txt
from utils.torch_utils import select_device, time_synchronized
1������opt����
def parse_opt():"""opt�������data: ���ݼ������ļ���ַ �������ݼ���·���������������������ص�ַ����Ϣweights: ģ�͵�Ȩ���ļ���ַ weights/yolov5s.ptbatch_size: ǰ�������δ�С Ĭ��32imgsz: ���������ͼƬ�ֱ��� Ĭ��640conf-thres: object���Ŷ���ֵ Ĭ��0.001iou-thres: ����NMSʱIOU����ֵ Ĭ��0.6task: ���ò��Ե����� ��train, val, test, speed or study���� Ĭ��valdevice: ���Ե��豸single-cls: ���ݼ��Ƿ�ֻ��һ����� Ĭ��Falseaugment: �����Ƿ�ʹ��TTA Test Time Augment Ĭ��Falseverbose: �Ƿ��ӡ��ÿ������mAP Ĭ��False��������������auto-labelling(�е���RNN�е�teaching forcing)��ز������:https://github.com/ultralytics/yolov5/issues/1563 �������������ԭ��save-txt: traditional auto-labellingsave-hybrid: save hybrid autolabels, combining existing labels with new predictions before NMS (existing predictions given confidence=1.0 before NMS.save-conf: add confidences to any of the above commandssave-json: �Ƿ���coco��json��ʽ����Ԥ�����ʹ��cocoapi����������Ҫͬ��coco��json��ʽ�ı�ǩ�� Ĭ��Falseproject: ���Ա����Դ�ļ� Ĭ��runs/testname: ���Ա�����ļ���ַ Ĭ��exp ������runs/test/exp��exist-ok: �Ƿ���ڵ�ǰ�ļ� Ĭ��False һ���� no exist-ok ���� ����һ�㶼Ҫ���´����ļ���half: �Ƿ�ʹ�ð뾫������ Ĭ��False"""parser = argparse.ArgumentParser(prog='val.py')parser.add_argument('--data', type=str, default='data/coco128.yaml', help='dataset.yaml path')parser.add_argument('--weights', nargs='+', type=str, default='weights/yolov5s.pt', help='model.pt path(s)')parser.add_argument('--batch-size', type=int, default=4, help='batch size')parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')parser.add_argument('--task', default='val', help='train, val, test, speed or study')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')parser.add_argument('--augment', action='store_true', help='augmented inference')parser.add_argument('--verbose', action='store_true', help='report mAP by class')parser.add_argument('--save-txt', default=True, action='store_true', help='save results to *.txt')parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')parser.add_argument('--save-conf', default=True, action='store_true', help='save confidences in --save-txt labels')parser.add_argument('--save-json', action='store_true', help='save a cocoapi-compatible JSON results file')parser.add_argument('--project', default='runs/test', help='save to project/name')parser.add_argument('--name', default='exp', help='save to project/name')parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')opt = parser.parse_args() # ������������opt.save_json |= opt.data.endswith('coco.yaml') # |�� ��������������һ��ΪTrue ��߱�����ΪTrueopt.save_txt |= opt.save_hybridopt.data = check_file(opt.data) # check filereturn opt
2��ִ��main����
def main(opt):# ��ʼ����־ ����logging�ĵȼ�level�������ʽ������format�Ȼ�����Ϣset_logging()# ��ӡ��Ϣ test(����): opt��������ֵprint(colorstr('test: ') + ', '.join(f'{
k}={
v}' for k, v in vars(opt).items()))# ���requirements�ļ�����Ҫ�İ��Ƿ�װ����check_requirements(exclude=('tensorboard', 'thop'))# ���task in ['train', 'val', 'test']���������� ѵ����/��֤��/���Լ�if opt.task in ('train', 'val', 'test'): # run normallyrun(**vars(opt))# ���opt.task == 'speed' �Ͳ���yolov5ϵ�к�yolov3-spp����ģ�͵��ٶ�����elif opt.task == 'speed': # speed benchmarksfor w in opt.weights if isinstance(opt.weights, list) else [opt.weights]:run(opt.data, weights=w, batch_size=opt.batch_size, imgsz=opt.imgsz, conf_thres=.25, iou_thres=.45,save_json=False, plots=False)# ���opt.task = ['study']������yolov5ϵ�к�yolov3-spp����ģ���ڸ����߶��µ�ָ�겢���ӻ�elif opt.task == 'study': # run over a range of settings and save/plot# python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5s.pt yolov5m.pt yolov5l.pt yolov5x.ptx = list(range(256, 1536 + 128, 128)) # x axis (image sizes)for w in opt.weights if isinstance(opt.weights, list) else [opt.weights]:f = f'study_{
Path(opt.data).stem}_{
Path(w).stem}.txt' # filename to save toy = [] # y axisfor i in x: # img-sizeprint(f'\nRunning {
f} point {
i}...')r, _, t = run(opt.data, weights=w, batch_size=opt.batch_size, imgsz=i, conf_thres=opt.conf_thres,iou_thres=opt.iou_thres, save_json=opt.save_json, plots=False)y.append(r + t) # results and timesnp.savetxt(f, y, fmt='%10.4g') # saveos.system('zip -r study.zip study_*.txt')# ���ӻ�����ָ��plot_study_txt(x=x) # plot
���Կ������ģ�����opt.task���Է�Ϊ������֧��������Ҫ�ķ�֧������ opt.task in (��train��, ��val��, ��test��)����������������֧����Ҵ�ſ����ڸ�ʲô�Ϳ����ˣ�ûʲô�á�һ�����Ƕ���ֱ�ӽ����һ����֧��ִ��run������
3��ִ��run����
run ������ʵ��train.pyִ�еģ�������ִ��val.py��
train.py���ã�ÿ��ѵ��epoch����֤��ǰģ�ͣ�:
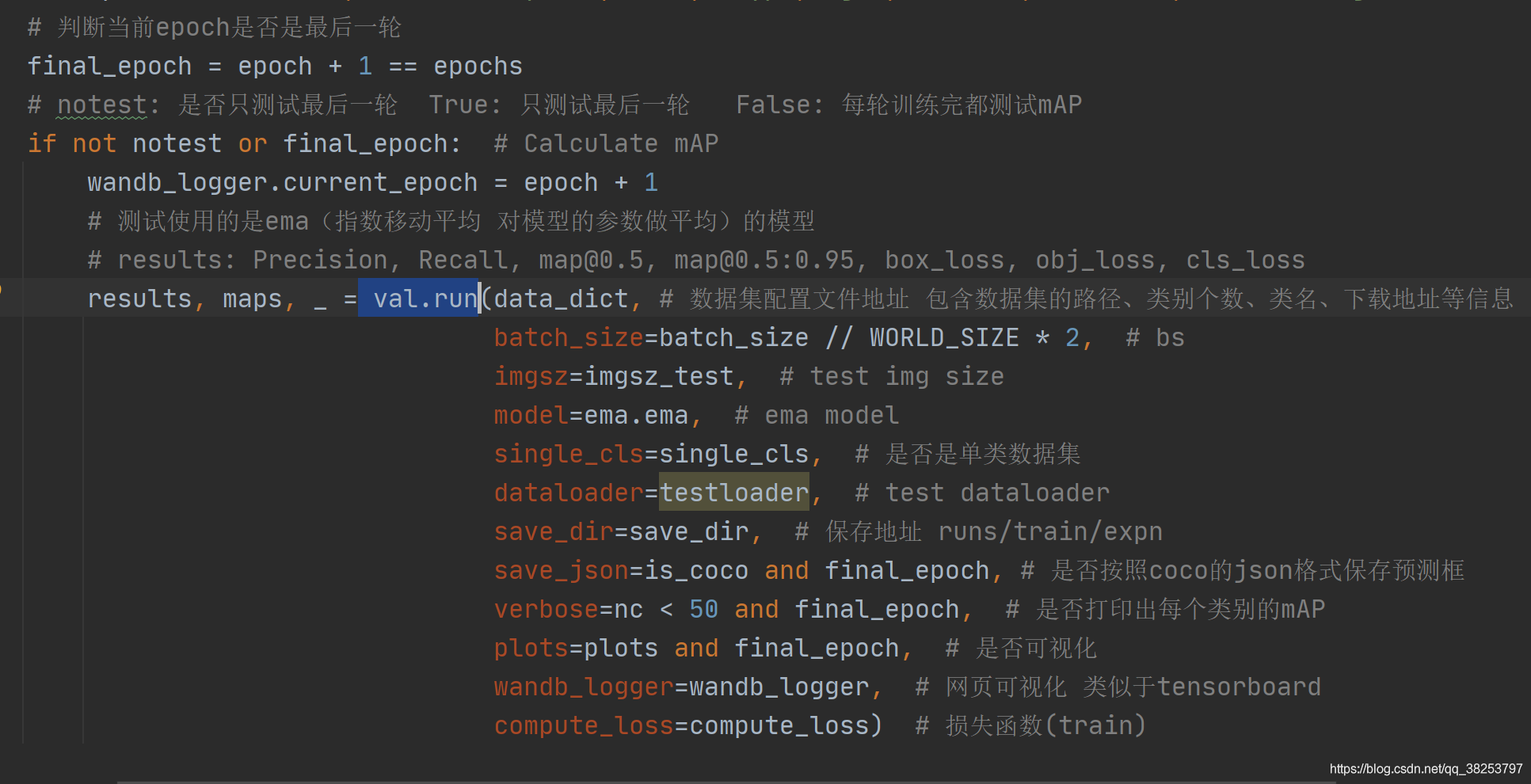
3.1���������
@torch.no_grad() # �����뷴��
def run(data, weights=None, batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6,task='val', device='', single_cls=False, augment=False, verbose=False, save_txt=False,save_hybrid=False, save_conf=False, save_json=False, project='runs/test', name='exp',exist_ok=False, half=True, model=None, dataloader=None, save_dir=Path(''), plots=True,wandb_logger=None, compute_loss=None,):""":params data: ���ݼ������ļ���ַ �������ݼ���·���������������������ص�ַ����Ϣ train.pyʱ����data_dict:params weights: ģ�͵�Ȩ���ļ���ַ ����train.py=None ����test.py=Ĭ��weights/yolov5s.pt:params batch_size: ǰ�������δ�С ����test.py����Ĭ��32 ����train.py����batch_size // WORLD_SIZE * 2:params imgsz: ���������ͼƬ�ֱ��� ����test.py����Ĭ��640 ����train.py����imgsz_test:params conf_thres: object���Ŷ���ֵ Ĭ��0.25:params iou_thres: ����NMSʱIOU����ֵ Ĭ��0.6:params task: ���ò��Ե����� ��train, val, test, speed or study���� Ĭ��val:params device: ���Ե��豸:params single_cls: ���ݼ��Ƿ�ֻ��һ����� ����test.py����Ĭ��False ����train.py����single_cls:params augment: �����Ƿ�ʹ��TTA Test Time Augment Ĭ��False:params verbose: �Ƿ��ӡ��ÿ������mAP ����test.py����Ĭ��Fasle ����train.py����nc < 50 and final_epoch:params save_txt: �Ƿ���txt�ļ�����ʽ����ģ��Ԥ�������� Ĭ��True:params save_hybrid: �Ƿ�save label+prediction hybrid results to *.txt Ĭ��False:params save_conf: �Ƿ�Ԥ��ÿ��Ŀ������Ŷȵ�Ԥ��tx�ļ��� Ĭ��True:params save_json: �Ƿ���coco��json��ʽ����Ԥ�����ʹ��cocoapi����������Ҫͬ��coco��json��ʽ�ı�ǩ������test.py����Ĭ��Fasle ����train.py����is_coco and final_epoch(һ��Ҳ��False):params project: ���Ա����Դ�ļ� Ĭ��runs/test:params name: ���Ա�����ļ���ַ Ĭ��exp ������runs/test/exp��:params exist_ok: �Ƿ���ڵ�ǰ�ļ� Ĭ��False һ���� no exist-ok ���� ����һ�㶼Ҫ���´����ļ���:params half: �Ƿ�ʹ�ð뾫������ FP16 half-precision inference Ĭ��False:params model: ģ�� ���ִ��test.py��ΪNone ���ִ��train.py�ͻᴫ��ema.ema(emaģ��):params dataloader: ���ݼ����� ���ִ��test.py��ΪNone ���ִ��train.py�ͻᴫ��testloader:params save_dir: �ļ�����·�� ���ִ��test.py��Ϊ���� ���ִ��train.py�ͻᴫ��save_dir(runs/train/expn):params plots: �Ƿ���ӻ� ����test.py����Ĭ��True ����train.py����plots and final_epoch:params wandb_logger: ��ҳ���ӻ� ������tensorboard ����test.py����Ĭ��None ����train.py����wandb_logger(train):params compute_loss: ��ʧ���� ����test.py����Ĭ��None ����train.py����compute_loss(train):return (Precision, Recall, map@0.5, map@0.5:0.95, box_loss, obj_loss, cls_loss)"""
3.2����ʼ������1
ѵ��ʱ��train.py�����ã���ʼ��ģ�Ͳ�����ѵ���豸
��֤ʱ��val.py�����ã���ʼ���豸��save_dir�ļ�·����make dir������ģ�͡�check imgsz�� ����+check data������Ϣ
# ============================================== 1����ʼ������1 ==================================================# ��ʼ��ģ�Ͳ�ѡ����Ӧ�ļ����豸# �ж��Ƿ���ѵ��ʱ����run����(ִ��train.py�ű�), ����Ǿ�ʹ��ѵ��ʱ���豸 һ�㶼��traintraining = model is not Noneif training: # called by train.pydevice = next(model.parameters()).device # get model device# �������trin.py����run����(ִ��val.py�ű�)�͵���select_deviceѡ����õ��豸# ������save_dir + make dir + ����ģ��model + check imgsz + ����data������Ϣelse:device = select_device(device, batch_size=batch_size)# ����save_dir�ļ�·�� run\test\expnsave_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run# make dir run\test\expn\labels(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True)# ����ģ�� load FP32 model ֻ������test.py����Ҫ�Լ�����modelmodel = attempt_load(weights, map_location=device)# gs: ģ�������²���stride һ��[8, 16, 32] ����gsһ����32gs = max(int(model.stride.max()), 32) # grid size (max stride)# �������ͼƬ�ķֱ���imgsz�Ƿ��ܱ�gs���� ֻ������test.py����Ҫ�Լ�����check imgsz# imgsz_testimgsz = check_img_size(imgsz, s=gs) # check image size# Multi-GPU disabled, incompatible with .half() https://github.com/ultralytics/yolov5/issues/99# if device.type != 'cpu' and torch.cuda.device_count() > 1:# model = nn.DataParallel(model)# Data ��������������Ϣ ֻ������test.py����Ҫ��������������Ϣ, ��Ϊ����Ҫ����data�����µ�dataloader# ������train.pyʱ��ֱ�Ӵ���testloader��, ���Բ���Ҫ��������������Ϣwith open(data, encoding='utf-8') as f:data = yaml.safe_load(f)check_dataset(data) # check
3.3������ģ��
�뾫����֤half model + ģ�ͼ�֦prune + ģ���ں�conv+bn
# ============================================== 2������ģ������ ==================================================# Half model ֻ���ڵ�GPU�豸�ϲ���ʹ��# һ��ʹ��half, ����ģ����Ҫ��Ϊhalf, ����ģ�͵�ͼƬҲ��Ҫ��Ϊhalfhalf &= device.type != 'cpu' # half precision only supported on CUDAif half:model.half()# from utils.torch_utils import prune# prune(model, 0.3) # ģ�ͼ�֦# model = model.fuse() # ģ���ں� �ں�conv+bnmodel.eval() # ����ģ����֤ģʽ
3.4����ʼ������2
�Ƿ���coco���ݼ�is_coco + ������nc + ����mAP��ز��� + ��ʼ����־ Logging
# ============================================== 3����ʼ������2 ==================================================# ���������Ƿ���coco���ݼ�is_coco = type(data['val']) is str and data['val'].endswith('coco/val2017.txt') # COCO dataset boolnc = 1 if single_cls else int(data['nc']) # number of classes# ����mAP��ز���# ����iou��ֵ ��0.5-0.95ȡ10��(0.05���) iou vector for mAP@0.5:0.95# # iouv: [0.50000, 0.55000, 0.60000, 0.65000, 0.70000, 0.75000, 0.80000, 0.85000, 0.90000, 0.95000]iouv = torch.linspace(0.5, 0.95, 10).to(device)# mAP@0.5:0.95 iou����=10��niou = iouv.numel()# ��ʼ����־ Logginglog_imgs = 0if wandb_logger and wandb_logger.wandb:log_imgs = min(wandb_logger.log_imgs, 100)
3.5������val���ݼ�
ѵ��ʱ��train.py�����ã�����val���ݼ�
��֤ʱ��val.py�����ã�����Ҫ����val���ݼ� ֱ�Ӵ�train.py �д���testloader
# ============================================== 4������val���ݼ� ==================================================# �������ѵ��(ִ��val.py�ű�����run����)�͵���create_dataloader����dataloader# �����ѵ��(ִ��train.py����run����)�Ͳ���Ҫ����dataloader ����ֱ�ӴӲ����д�����testloaderif not training:if device.type != 'cpu':# ���ﴴ��һ��ȫ�����������ǰ���Ƿ��ܹ���������model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run oncetask = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images# ����dataloader �����rectĬ��ΪTrue �����������ڲ��Լ� �ڲ�Ӱ��mAP������¿��Դ�����������ٶ�dataloader = create_dataloader(data[task], imgsz, batch_size, gs, single_cls, pad=0.5, rect=True,prefix=colorstr(f'{
task}: '))[0]
3.6����ʼ������3
��ʼ���������� + ���ݼ����� + ��ȡcoco���ݼ���������� + ����tqdm������ + ��ʼ��p, r, f1, mp, mr, map50, mapָ���ʱ��t0, t1, t2 + ��ʼ�����Լ�����ʧ + ��ʼ��json�ļ��е��ֵ� ͳ����Ϣ ap��
# ============================================== 5����ʼ������3 ==================================================# ��ʼ��һЩ������Ҫ�IJ���seen = 0 # ��ʼ�����Ե�ͼƬ������# ��ʼ����������confusion_matrix = ConfusionMatrix(nc=nc)# ��ȡ���ݼ�������������names = {
k: v for k, v in enumerate(model.names if hasattr(model, 'names') else model.module.names)}# ��ȡcoco���ݼ����������# coco���ݼ���80���� ������Χ��Ӧ����0~79,�������ﷵ�ص�ȷ��0~90 coco�ٷ����������涨��# coco80_to_coco91_class����Ϊ��������������Ӧ����������һ����Χ��0~80����������coco91class = coco80_to_coco91_class()# ����tqdm����������ʾ��Ϣs = ('%20s' + '%11s' * 6) % ('Class', 'Images', 'Labels', 'P', 'R', 'mAP@.5', 'mAP@.5:.95')# ��ʼ��p, r, f1, mp, mr, map50, mapָ���ʱ��t0, t1, t2p, r, f1, mp, mr, map50, map, t0, t1, t2 = 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.# ��ʼ�����Լ�����ʧloss = torch.zeros(3, device=device)# ��ʼ��json�ļ��е��ֵ� ͳ����Ϣ ap��jdict, stats, ap, ap_class, wandb_images = [], [], [], [], []
3.7����ʼ��֤
# ============================================== 6����ʼ��֤ ==================================================for batch_i, (img, targets, paths, shapes) in enumerate(tqdm(dataloader, desc=s)):
3.7.1��Ԥ����ͼƬ��target
# 6.1��Ԥ����ͼƬ��targett_ = time_synchronized() # ��ȡ��ǰʱ��img = img.to(device, non_blocking=True) # img to device# ���halfΪTrue �Ͱ�ͼƬ��Ϊhalf���� uint8 to fp16/32img = img.half() if half else img.float()img /= 255.0 # 0 - 255 to 0.0 - 1.0targets = targets.to(device) # targets to device# batch size, channels, height, widthnb, _, height, width = img.shapet = time_synchronized() # ��ȡ��ǰʱ��t0 += t - t_ # t0: �ۼƴ�������ʱ��
3.7.2��model ǰ������
# 6.2��Run model ǰ������# out: ������� 1�� [bs, anchor_num*grid_w*grid_h, xywh+c+20classes] = [1, 19200+4800+1200, 25]# train_out: ѵ����� 3�� [bs, anchor_num, grid_w, grid_h, xywh+c+20classes]# ��: [1, 3, 80, 80, 25] [1, 3, 40, 40, 25] [1, 3, 20, 20, 25]out, train_out = model(img, augment=augment) # inference and training outputst1 += time_synchronized() - t # �ۼ�ǰ������ʱ�� t1
3.7.3��������֤����ʧ
# 6.3��������֤����ʧ# compute_loss��Ϊ�� ˵������ִ��train.py ���ݴ����compute_loss������ʧֵif compute_loss:loss += compute_loss([x.float() for x in train_out], targets)[1][:3] # lbox, lobj, lcls
3.7.4��Run NMS
# 6.4��Run NMS# ����ʵ��target��xywh(��Ϊtarget����labelimg�����˹�һ����)ӳ�䵽img(test)�ߴ�targets[:, 2:] *= torch.Tensor([width, height, width, height]).to(device)# save_hybrid: adding the dataset labels to the model predictions before NMS# ����NMS֮ǰ�����ݼ���ǩtargets���ӵ�ģ��Ԥ����# �����������ݼ����Զ����(for autolabelling)��������(��pred�л���gt) ����mAP��ӳ���µĻ�ϱ�ǩ# targets: [num_target, img_index+class_index+xywh] = [31, 6]# lb: {list: bs} ��һ��ͼƬ��target[17, 5] �ڶ���[1, 5] ������[7, 5] ������[6, 5]lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else []t = time_synchronized()out = non_max_suppression(out, conf_thres, iou_thres, labels=lb, multi_label=True, agnostic=single_cls)t2 += time_synchronized() - t # �ۼ�NMSʱ��
3.7.5��ͳ��ÿ��ͼƬ����ʵ��Ԥ�����Ϣ
# 6.5��ͳ��ÿ��ͼƬ����ʵ��Ԥ�����Ϣ Statistics per image# Ϊÿ��ͼƬ��ͳ�ƣ�д��Ԥ����Ϣ��txt�ļ�������json�ļ��ֵ䣬ͳ��tp��# out: list{bs} [300, 6] [42, 6] [300, 6] [300, 6] [:, image_index+class+xywh]for si, pred in enumerate(out):# 6.5��ͳ��ÿ��ͼƬ����ʵ��Ԥ�����Ϣ# ��ȡ��si��ͼƬ��gt��ǩ��Ϣ ����class, x, y, w, h target[:, 0]Ϊ��ǩ��������ͼƬ�ı��labels = targets[targets[:, 0] == si, 1:] # [:, class+xywh]nl = len(labels) # ��si��ͼƬ��gt����# ��ȡ��ǩ���tcls = labels[:, 0].tolist() if nl else [] # target classpath = Path(paths[si]) # ��si��ͼƬ�ĵ�ַ# ͳ�Ʋ���ͼƬ���� +1seen += 1# ���Ԥ��Ϊ�գ������ӿյ���Ϣ��stats��if len(pred) == 0:if nl:stats.append((torch.zeros(0, niou, dtype=torch.bool), torch.Tensor(), torch.Tensor(), tcls))continue# Predictionsif single_cls:pred[:, 5] = 0predn = pred.clone()# ��Ԥ������ӳ�䵽ԭͼimg��scale_coords(img[si].shape[1:], predn[:, :4], shapes[si][0], shapes[si][1]) # native-space pred
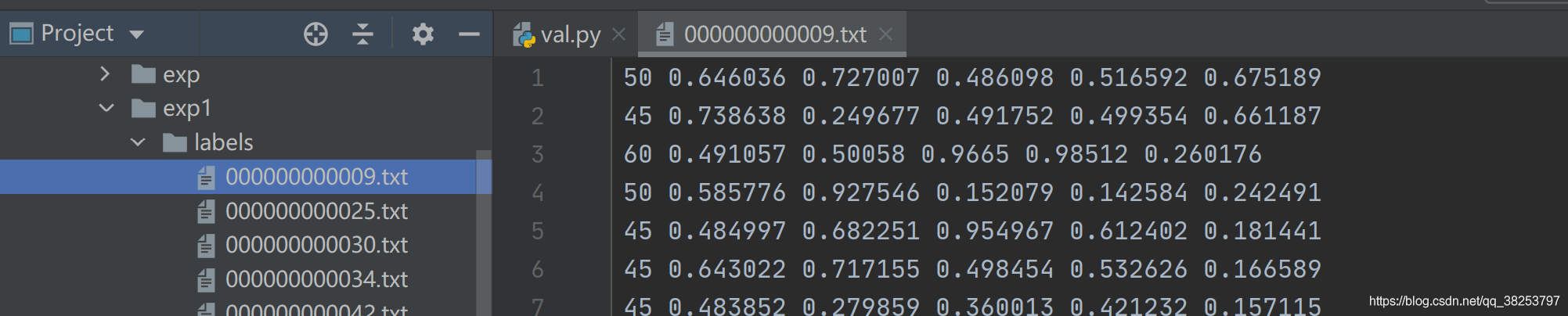
3.7.6������Ԥ����Ϣ��image_name.txt�ļ�
Ԥ����Ϣ��cls, xywh, conf
# 6.6������Ԥ����Ϣ��txt�ļ� runs\test\exp7\labels\image_name.txtif save_txt:# gn = [w, h, w, h] ��ӦͼƬ�Ŀ��� ���ں����һ��gn = torch.tensor(shapes[si][0])[[1, 0, 1, 0]] # normalization gain whwhfor *xyxy, conf, cls in predn.tolist():# xyxy -> xywh ������һ������xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywhline = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format# ����Ԥ����������ֵ����ӦͼƬimage_name.txt�ļ���with open(save_dir / 'labels' / (path.stem + '.txt'), 'a') as f:f.write(('%g ' * len(line)).rstrip() % line + '\n')# with open(save_dir / 'labels' / ('test' + '.txt'), 'a') as f:# f.write(('%g ' * len(line)).rstrip() % line + '\n')
����ͼ��
3.7.7������Ԥ����Ϣ��wandb_logger
# 6.7������Ԥ����Ϣ��wandb_logger(����tensorboard)��if len(wandb_images) < log_imgs and wandb_logger.current_epoch > 0: # Check for test operationif wandb_logger.current_epoch % wandb_logger.bbox_interval == 0:box_data = [{
"position": {
"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},"class_id": int(cls),"box_caption": "%s %.3f" % (names[cls], conf),"scores": {
"class_score": conf},"domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]boxes = {
"predictions": {
"box_data": box_data, "class_labels": names}} # inference-spacewandb_images.append(wandb_logger.wandb.Image(img[si], boxes=boxes, caption=path.name))wandb_logger.log_training_progress(predn, path, names) if wandb_logger and wandb_logger.wandb_run else None
3.7.8����Ԥ����Ϣ���浽coco��ʽ��json�ֵ�
jdict�ֵ䣨Ԥ����Ϣ����image_id + category_id + bbox + score
# 6.8����Ԥ����Ϣ���浽coco��ʽ��json�ֵ�(�������json�ļ�) Append to pycocotools JSON dictionary# ����: [{"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}, ...if save_json:# ��ȡͼƬidimage_id = int(path.stem) if path.stem.isnumeric() else path.stem# ��ȡԤ��� ����xyxyתΪxywh��ʽbox = xyxy2xywh(predn[:, :4]) # xywh# ֮ǰ�ĵ�xyxy��ʽ�����Ͻ����½����� xywh�����ĵ�����Ϳ���# ��coco��json��ʽ�Ŀ�������xywh(���Ͻ����� + ����)# �������д����ǽ����ĵ����� -> ���Ͻ����� xy center to top-left cornerbox[:, :2] -= box[:, 2:] / 2# image_id: ͼƬid ����������ͼƬ# category_id: ��� coco91class()������0~79ӳ�䵽����0~90# bbox: Ԥ�������# score: Ԥ��÷�for p, b in zip(pred.tolist(), box.tolist()):jdict.append({
'image_id': image_id,'category_id': coco91class[int(p[5])] if is_coco else int(p[5]),'bbox': [round(x, 3) for x in b],'score': round(p[4], 5)})
3.7.9���������������correct������stats
correct(TP)�������
for gt���������
- ѡ��pred�����ڸ���������Ԥ���
- ѡ��gt�����ڸ���������gt��
- �����ѡ��������Ԥ��� �� ѡ��������gt�� ious
- ɸѡ������ious > 0.5��Ԥ��� ����TP
- �������TP ��ͳ������TP�в�ͬiou��ֵ�µ�TP ͬʱͳ�Ƽ���Ŀ��(detected)
- �ظ�������� ֱ������Ŀ�����len(detected) = gt����
# 6.9���������������correct������stats# ��ʼ��Ԥ������ niouΪiou��ֵ�ĸ��� Assign all predictions as incorrect# correct = [pred_obj_num, 10] = [300, 10] ȫ��Falsecorrect = torch.zeros(pred.shape[0], niou, dtype=torch.bool, device=device)if nl:detected = [] # target indices ���ڴ���Ѽ���Ŀ��tcls_tensor = labels[:, 0] # ��ǰͼƬ������gt�����tbox = xywh2xyxy(labels[:, 1:5]) # gt boxes ���xyxy��ʽ�Ŀ�# ��Ԥ���ӳ�䵽ԭͼimgscale_coords(img[si].shape[1:], tbox, shapes[si][0], shapes[si][1]) # native-space labelsif plots:# ����������� confusion_matrixconfusion_matrix.process_batch(predn, torch.cat((labels[:, 0:1], tbox), 1))# Per target class# ��ͼƬ��ÿ���������for cls in torch.unique(tcls_tensor):# gt�и��������� target indices nonzero: ��ȡ�б���ΪTrue��indexti = (cls == tcls_tensor).nonzero(as_tuple=False).view(-1)# Ԥ����и��������� prediction indicespi = (cls == pred[:, 5]).nonzero(as_tuple=False).view(-1)# Search for detectionsif pi.shape[0]:# Prediction to target ious# predn[pi, :4]: ���ڸ����Ԥ���[144, 4] tbox[ti]: ���ڸ����gt��[13, 4]# box_iou: [144, 4] + [13, 4] => [144, 13] �������ڸ����Ԥ��������ڸ����gt���iou# .max(1): [144] ѡ��ÿ��Ԥ���������gt box������iouֵ, iΪ���iouֵʱ��Ӧ��gt����ious, i = box_iou(predn[pi, :4], tbox[ti]).max(1) # best ious, indices# Append detectionsdetected_set = set() # �����������ûʲô��for j in (ious > iouv[0]).nonzero(as_tuple=False): # j: ious��>0.5������ ֻ��iou>=0.5����TP# ��ü���Ŀ��d = ti[i[j]] # detected targetif d.item() not in detected_set:detected_set.add(d.item()) # ûʲô��detected.append(d) # ����ǰ����gt��d���ӵ�detected()# iouvΪ��0.05Ϊ���� 0.5-0.95������# ͳ������TP�в�ͬiou��ֵ�µ�TP true positive ����correct�м�¼���ĸ�Ԥ������ĸ�iou��ֵ�µ�TP# correct: [pred_num, 10] = [300, 10] ��¼���ĸ�Ԥ������ĸ�iou��ֵ����TPcorrect[pi[j]] = ious[j] > iouv # iou_thres is 1xnif len(detected) == nl: # �������Ŀ��ֵ����gt��ĸ��� �ͽ���break# ��ÿ��ͼƬ��Ԥ����ͳ�Ƶ�stats��# Append statistics(correct, conf, pcls, tcls) bs��(correct, conf, pcls, tcls)# correct: [pred_num, 10] bool ��ǰͼƬÿһ��Ԥ�����ÿһ��iou�������Ƿ���TP# pred[:, 4]: [pred_num, 1] ��ǰͼƬÿһ��Ԥ����conf# pred[:, 5]: [pred_num, 1] ��ǰͼƬÿһ��Ԥ�������# tcls: [gt_num, 1] ��ǰͼƬ����gt���classstats.append((correct.cpu(), pred[:, 4].cpu(), pred[:, 5].cpu(), tcls))
3.7.10������ǰ����batchͼƬ��gt��pred��
# 6.10��Plot images# ����ǰ����batch��ͼƬ��ground truth��Ԥ���predictions(����ͼ)һ�𱣴�if plots and batch_i < 3:# ground truthf = save_dir / f'test_batch{
batch_i}_labels.jpg'# Thread ��ʾ�ڵ����Ŀ����߳������еĻ ����һ�����߳�(���߳�)��ִ�к��� ������ӽ���ȫȨ�����������# target: ִ�еĺ��� args: ����ĺ������� daemon: �����߳̽�����, �������������߳�ThreadҲ�Ѿ��Զ�������# .start(): �����߳� ��threadһ������ʱ��, �ͻ����������Լ�������������plot_images# �����plot_images����ϵ����, ���Է������߳���ͣ, �������̻߳�����������ѵ��(������������)Thread(target=plot_images, args=(img, targets, paths, f, names), daemon=True).start()# predictions ����plot_images����֮ǰ��Ҫ�ı�pred�ĸ�ʽ target����Ҫ��f = save_dir / f'test_batch{
batch_i}_pred.jpg'Thread(target=plot_images, args=(img, output_to_target(out), paths, f, names), daemon=True).start()
test_batch0_labels.jpg

test_batch0_pred.jpg:

3.7.11������mAP
# 6.11������mAP# ͳ��stats������ͼƬ��ͳ�ƽ�� ��stats�б�����Ϣƴ�ӵ�һ��# stats(concat��): list{4} correct, conf, pcls, tcls ͳ�Ƴ����������ݼ���GT# correct [img_sum, 10] �������ݼ�����ͼƬ������Ԥ�����ÿһ��iou�������Ƿ���TP [1905, 10]# conf [img_sum] �������ݼ�����ͼƬ������Ԥ����conf [1905]# pcls [img_sum] �������ݼ�����ͼƬ������Ԥ������� [1905]# tcls [gt_sum] �������ݼ�����ͼƬ����gt���class [929]stats = [np.concatenate(x, 0) for x in zip(*stats)] # to numpy# stats[0].any(): stats[0]�Ƿ�ȫ��ΪFalse, ���� False, �����һ��Ϊ True, �� Trueif len(stats) and stats[0].any():# ���������ͳ��Ԥ��������p, r, ap, f1, ap_class��ap_per_class�����Ǽ���ÿ�����mAP��ָ��ģ���ָ��# p: [nc] ���ƽ��f1ʱÿ������precision# r: [nc] ���ƽ��f1ʱÿ������recall# ap: [71, 10] ���ݼ�ÿ�������10��iou��ֵ�µ�mAP# f1 [nc] ���ƽ��f1ʱÿ������f1# ap_class: [nc] �������ݼ������е����indexp, r, ap, f1, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)# ap50: [nc] ��������mAP@0.5 ap: [nc] ��������mAP@0.5:0.95ap50, ap = ap[:, 0], ap.mean(1)# mp: [1] ��������ƽ��precision(���f1ʱ)# mr: [1] ��������ƽ��recall(���f1ʱ)# map50: [1] ��������ƽ��mAP@0.5# map: [1] ��������ƽ��mAP@0.5:0.95mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()# nt: [nc] ͳ�Ƴ��������ݼ���gt�������ݼ��������ĸ���nt = np.bincount(stats[3].astype(np.int64), minlength=nc) # number of targets per classelse:nt = torch.zeros(1)
3.7.12��print��ӡ����ָ��
# 6.12��print��ӡ����ָ��# Print results ���ݼ�ͼƬ���� + ���ݼ�gt������� + ��������ƽ��precision + # ��������ƽ��recall + ��������ƽ��mAP@0.5 + ��������ƽ��mAP@0.5:0.95pf = '%20s' + '%11i' * 2 + '%11.3g' * 4 # print formatprint(pf % ('all', seen, nt.sum(), mp, mr, map50, map))# Print results per class# ϸ��չʾÿ�����ĸ���ָ�� ��� + ���ݼ�ͼƬ���� + �������gt������ + �������precision +# �������recall + �������mAP@0.5 + �������mAP@0.5:0.95if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):for i, c in enumerate(ap_class):print(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))# Print speeds ��ӡǰ���ķѵ���ʱ�䡢nms�ķ���ʱ�䡢��ʱ��t = tuple(x / seen * 1E3 for x in (t0, t1, t2)) # speeds per imageif not training:shape = (batch_size, 3, imgsz, imgsz)print(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {
shape}' % t)
�����ͼ��

3.7.13����������������wandb_logger��
# 6.13����������������wandb_logger��# Plots confusion_matrix + wandb_loggerif plots:confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))if wandb_logger and wandb_logger.wandb:val_batches = [wandb_logger.wandb.Image(str(f), caption=f.name) for f in sorted(save_dir.glob('test*.jpg'))]wandb_logger.log({
"Validation": val_batches})if wandb_images:wandb_logger.log({
"Bounding Box Debugger/Images": wandb_images})
confusion_matrix.png:

3.7.14��Save JSON
# 6.14��Save JSON# ����֮ǰ�����json�ļ���ʽԤ���� ͨ��cocoapi��������ָ��# ��Ҫע����� ���Լ��ı�ǩҲҪתΪcoco��json��ʽif save_json and len(jdict):w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weightsanno_json = str(Path(data.get('path', '../coco')) / 'annotations/instances_val2017.json') # annotations json# ��ȡԤ����json�ļ�·������pred_json = str(save_dir / f"{
w}_predictions.json") # predictions jsonprint('\nEvaluating pycocotools mAP... saving %s...' % pred_json)with open(pred_json, 'w') as f:json.dump(jdict, f)try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynbcheck_requirements(['pycocotools'])from pycocotools.coco import COCOfrom pycocotools.cocoeval import COCOeval# ��ȡ����ʼ�����Լ���ǩ��json�ļ�anno = COCO(anno_json) # init annotations api# ��ʼ��Ԥ�����ļ�pred = anno.loadRes(pred_json) # init predictions api# ����������eval = COCOeval(anno, pred, 'bbox')if is_coco:eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.img_files] # image IDs to evaluate# ����eval.evaluate()eval.accumulate()# չʾ���eval.summarize()map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)except Exception as e:print(f'pycocotools unable to run: {
e}')
3.7.15�� Return results
# 6.15�����ز���ָ���� Return resultsmodel.float() # for trainingif not training:s = f"\n{
len(list(save_dir.glob('labels/*.txt')))} labels saved to {
save_dir / 'labels'}" if save_txt else ''print(f"Results saved to {
save_dir}{
s}")maps = np.zeros(nc) + map # [80] 80��ƽ��mAP@0.5:0.95for i, c in enumerate(ap_class):maps[c] = ap[i] # maps [80] ��������mAP@0.5:0.95# (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()): {tuple:7}# 0: mp [1] ��������ƽ��precision(���f1ʱ)# 1: mr [1] ��������ƽ��recall(���f1ʱ)# 2: map50 [1] ��������ƽ��mAP@0.5# 3: map [1] ��������ƽ��mAP@0.5:0.95# 4: val_box_loss [1] ��֤���ع���ʧ# 5: val_obj_loss [1] ��֤�����Ŷ���ʧ# 6: val_cls_loss [1] ��֤��������ʧ# maps: [80] ��������mAP@0.5:0.95# t: {tuple: 3} 0: ��ӡǰ���ķѵ���ʱ�� 1: nms�ķ���ʱ�� 2: ��ʱ��return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
һ��Ὣ���ݷ��ص�train.py�У�

�ܽ�
����ű��Ĵ��뻹�DZȽϼģ���Ҫ���ѵ����ڵ�3.7.9�ں�3.7.11�ڼ��� ��������+����correct+����mAP �ϡ�����Ҫ��ȫ����������ű���һ��Ҫ���metrics.py�ű�һ��
�C2021.8.12