- ? �������python3
- ? ���ߣ�Kͬѧ��
- ? ��ѡר���������ѧϰ100����
- ? �Ƽ�ר�����������������ѧϰ��
- ? ��Ʒר������Matplotlib�̡̳�
- ? ѡ��ר��������Ȼ���Դ���NLP-ʵ���̡̳�
- ? ����ר������Python����100�⡷
��Һã�����Kͬѧ����
����һƪ�����У���ʹ��LSTM�Ե�����������һ����Ϊ���ӵ���з��������ľͼ����ϴεĹ�������һ���ֵķ�����������Ҫ��������ָ��metrics��������Precision��Recall��AUC��ֵ��ʵ����ѵ��ģ�͵�ͬʱ��¼��Щָ������ʵ�ַ�ʽ��������Ҳ������ͬ�����ͬʱ������ȫ���Ӳ�Dense�����Ҳ������Ϊ1��֮ǰ�������������ģ����Զ���������ѧϰһ�¡�
����Ŀ¼
-
- һ��ǰ�ڹ���
-
- 1. ��������
- 2. ���ݷ���
- ��������Ԥ����
-
- 1. ��������
- 2. �ִʴ���
- 3. ȥ��ͣ�ô�
- 4. Word2vec����
- 5. ����ѵ��������Լ�
- �����������
- �ġ����Ԥ��
һ��ǰ�ڹ���
1. ��������
#Դ���ڿ��Ķ�
df
| evaluation | label | |
|---|---|---|
| 0 | ����һ��ʱ�䣬�о������������� | ���� |
| 1 | ���ӷdz��ã��Ѿ��Ǽ���ĵڶ�̨�ˡ���һ���µ����ڶ���͵������ˣ�������������˵�����ˣ�һֱ��... | ���� |
| 2 | ���ӱ������еĴ�ö࣬����Ҳ��������ϵͳ�����ܣ�����ܻ��������� | ���� |
| 3 | ���� | ���� |
| 4 | ������ô�����ˣ��о������������յ����ӻ��DZȽϿɿ���ϣ���Ժ�Ƚ����ã������ǿ���������ʱ�� | ���� |
| ... | ... | ... |
| 4278 | һ�㣬��ǿ���⣬��Ū�˵㲻��죬Ͷ���˺þòŽ�� | ���� |
| 4279 | ��Ļ�ս�������ͼ���ߡ�����ʦ���ž�Ȼ˵û���⣡�˻���Ҫ��100Ԫ�Ŀ���ѣ��������ģ�... | ���� |
| 4280 | һ�ֶ�������������������̫ʧ���ˣ���ĵ���û��������˵���˻�����ȡ�����涨�õ�ʱ�䲻ȥ��һ... | ���� |
| 4281 | �µ�����ؼҲ���ʮ���죬����֧��������������ѣ����Ӵ�������ˤ�������ۺ�绰����Աһֱ���Ѳ�... | ���� |
| 4282 | һ��㡣�����λҲ���ᱧ̫�����������ijijTV���Ǻúܶࡣ | ���� |
4283 rows �� 2 columns
2. ���ݷ���
df.groupby('label')["evaluation"].count()
label
���� 1908
���� 2375
Name: evaluation, dtype: int64
df.label.value_counts().plot(kind='pie', autopct='%0.05f%%', colors=['lightblue', 'lightgreen'], explode=(0.01, 0.01))
<AxesSubplot:ylabel='label'>

df['length'] = df['evaluation'].apply(lambda x: len(x))
df.head()
| evaluation | label | length | |
|---|---|---|---|
| 0 | ����һ��ʱ�䣬�о������������� | ���� | 15 |
| 1 | ���ӷdz��ã��Ѿ��Ǽ���ĵڶ�̨�ˡ���һ���µ����ڶ���͵������ˣ�������������˵�����ˣ�һֱ��... | ���� | 97 |
| 2 | ���ӱ������еĴ�ö࣬����Ҳ��������ϵͳ�����ܣ�����ܻ��������� | ���� | 33 |
| 3 | ���� | ���� | 2 |
| 4 | ������ô�����ˣ��о������������յ����ӻ��DZȽϿɿ���ϣ���Ժ�Ƚ����ã������ǿ���������ʱ�� | ���� | 46 |
# Դ���ڿ��Ķ�
plt.show()

# Դ���ڿ��Ķ�
plt.show()
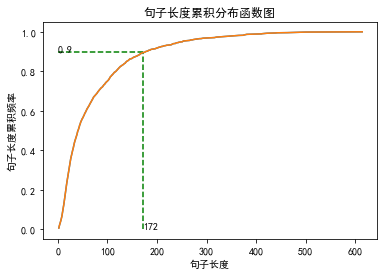
��λ��Ϊ0.9�ľ��ӳ���:172��
��������Ԥ����
1. ��������
�������ı������븺���ı����ݽ��д���
df = df.sample(frac=1)
df.head()
| evaluation | label | length | |
|---|---|---|---|
| 2105 | ���Ӳ�������������ļ۸��ȥ����ˡ��� | ���� | 19 |
| 996 | ���Ӻ�������Ʒ��ֵ������ | ���� | 12 |
| 4171 | ���Ӳ�����û�л��㣬©��Ҳ�������������������µ��Ӿ磬�е���Ӱ�����ϻ����ӿھͺ��ˣ���ʱû��... | ���� | 118 |
| 3206 | ����̫����е�С�������治�Ǻ��Ѻã���̩�ݺ��Ӳ�̫Զ�ˣ�������Ч��ɫ�ʲ�����©��϶� | ���� | 43 |
| 1748 | �ã��ͻ��ٶȿ죬����á�.3333333 | ���� | 20 |
2. �ִʴ���
import jiebaword_cut = lambda x: jieba.lcut(x)
df['words'] = df["evaluation"].apply(word_cut)
df.head()
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.442 seconds.
Prefix dict has been built successfully.
| evaluation | label | length | words | |
|---|---|---|---|---|
| 2105 | ���Ӳ�������������ļ۸��ȥ����ˡ��� | ���� | 19 | [����, ����, ��, ����, ����, ��, �۸��, ȥ��, ��, ��, ��, ��] |
| 996 | ���Ӻ�������Ʒ��ֵ������ | ���� | 12 | [����, ��, ����, ��, Ʒ��, ֵ��, ����] |
| 4171 | ���Ӳ�����û�л��㣬©��Ҳ�������������������µ��Ӿ磬�е���Ӱ�����ϻ����ӿھͺ��ˣ���ʱû��... | ���� | 118 | [����, ����, ��, û��, ����, ��, ©��, Ҳ, ����, ��������, ��, ��, ... |
| 3206 | ����̫����е�С�������治�Ǻ��Ѻã���̩�ݺ��Ӳ�̫Զ�ˣ�������Ч��ɫ�ʲ�����©��϶� | ���� | 43 | [����, ̫, �, ��, �е�, С��, ��, ����, ����, ��, �Ѻ�, ��, ��,... |
| 1748 | �ã��ͻ��ٶȿ죬����á�.3333333 | ���� | 20 | [��, ��, �ͻ�, �ٶ�, ��, ��, ����, ��, ��, ., 3333333] |
3. ȥ��ͣ�ô�
with open("hit_stopwords.txt", "r", encoding='utf-8') as f:stopwords = f.readlines()stopwords_list = []
for each in stopwords:stopwords_list.append(each.strip('\n'))# �����Զ���ͣ�ô�
stopwords_list += ["��","ȥ","��","��","һ��","��","��",".","��"]def remove_stopwords(ls): # ȥ��ͣ�ô�return [word for word in ls if word not in stopwords_list]df['ȥ��ͣ�ôʺ������']=df["words"].apply(lambda x: remove_stopwords(x))
df["y"] = np.array([1 if i=="����" else 0 for i in df['label']])
df.head()
| evaluation | label | length | words | ȥ��ͣ�ôʺ������ | y | |
|---|---|---|---|---|---|---|
| 2105 | ���Ӳ�������������ļ۸��ȥ����ˡ��� | ���� | 19 | [����, ����, ��, ����, ����, ��, �۸��, ȥ��, ��, ��, ��, ��] | [����, ����, ����, �۸��, ȥ��, ��] | 0 |
| 996 | ���Ӻ�������Ʒ��ֵ������ | ���� | 12 | [����, ��, ����, ��, Ʒ��, ֵ��, ����] | [����, ��, ����, ��, Ʒ��, ֵ��, ����] | 1 |
| 4171 | ���Ӳ�����û�л��㣬©��Ҳ�������������������µ��Ӿ磬�е���Ӱ�����ϻ����ӿھͺ��ˣ���ʱû��... | ���� | 118 | [����, ����, ��, û��, ����, ��, ©��, Ҳ, ����, ��������, ��, ��, ... | [����, ����, û��, ����, ©��, ����, ��������, ��, ��, ���Ӿ�, �е�, ... | 0 |
| 3206 | ����̫����е�С�������治�Ǻ��Ѻã���̩�ݺ��Ӳ�̫Զ�ˣ�������Ч��ɫ�ʲ�����©��϶� | ���� | 43 | [����, ̫, �, ��, �е�, С��, ��, ����, ����, ��, �Ѻ�, ��, ��,... | [����, ̫, �, �е�, С��, ����, ����, ��, �Ѻ�, ̩��, ����, ��̫Զ... | 0 |
| 1748 | �ã��ͻ��ٶȿ죬����á�.3333333 | ���� | 20 | [��, ��, �ͻ�, �ٶ�, ��, ��, ����, ��, ��, ., 3333333] | [��, �ͻ�, �ٶ�, ��, ����, ��, 3333333] | 1 |
4. Word2vec����
Word2vec��һ������������������ģ�͡���һ��������ת����������ʽ�Ĺ��ߡ� ͨ��ת�������Ѷ��ı����ݵĴ�����Ϊ�����ռ��е��������㣬����������ռ��ϵ����ƶȣ�����ʾ�ı������ϵ����ƶȡ�
from gensim.models.word2vec import Word2Vecx = df["ȥ��ͣ�ôʺ������"]# ѵ�� Word2Vec dz��������ģ��
w2v = Word2Vec(vector_size=300, #��ָ����������ά�ȣ�Ĭ��Ϊ100��min_count=10) #���Զ��ֵ����ض�. ��Ƶ����min_count�����ĵ��ʻᱻ������, Ĭ��ֵΪ5��
w2v.build_vocab(x)
w2v.train(x, total_examples=w2v.corpus_count, epochs=20)
# ���� Word2Vec ģ�ͼ�������
w2v.save('w2v_model.pkl')# ���ı�ת��Ϊ����
def average_vec(text):vec = np.zeros(300).reshape((1, 300))for word in text:try:vec += w2v.wv[word].reshape((1, 300))except KeyError:continuereturn vec# ������������Ϊ Ndarray
x_vec = np.concatenate([average_vec(z) for z in x])
y = df['y']
5. ����ѵ��������Լ�
from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(x_vec,y,test_size=0.2)
from keras.models import Sequential
from keras.layers import Dense,LSTM,Bidirectional,Embedding
import tensorflow as tf#����ģ��
model = Sequential()
model.add(Embedding(100000, 100))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))METRICS = [tf.keras.metrics.TruePositives(name='tp'),tf.keras.metrics.FalsePositives(name='fp'),tf.keras.metrics.TrueNegatives(name='tn'),tf.keras.metrics.FalseNegatives(name='fn'), tf.keras.metrics.BinaryAccuracy(name='accuracy'), # ע����Ҫ����loss�ı�tf.keras.metrics.Precision(name='precision'),tf.keras.metrics.Recall(name='recall'),tf.keras.metrics.AUC(name='auc'),tf.keras.metrics.AUC(name='prc', curve='PR'), # precision-recall curve
]model.compile(loss='binary_crossentropy', optimizer='adam', metrics=METRICS)model.summary()
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 100) 10000000
_________________________________________________________________
lstm (LSTM) (None, 100) 80400
_________________________________________________________________
dense (Dense) (None, 1) 101
=================================================================
Total params: 10,080,501
Trainable params: 10,080,501
Non-trainable params: 0
_________________________________________________________________
epochs = 30
batch_size = 64history = model.fit(X_train, y_train,epochs=epochs,batch_size=batch_size,validation_split=0.2)
Epoch 1/30
43/43 [==============================] - 40s 879ms/step - loss: 0.6343 - tp: 691.0000 - fp: 397.0000 - tn: 1132.0000 - fn: 520.0000 - accuracy: 0.6653 - precision: 0.6351 - recall: 0.5706 - auc: 0.6972 - prc: 0.6335 - val_loss: 0.5641 - val_tp: 194.0000 - val_fp: 76.0000 - val_tn: 304.0000 - val_fn: 112.0000 - val_accuracy: 0.7259 - val_precision: 0.7185 - val_recall: 0.6340 - val_auc: 0.7814 - val_prc: 0.7354
......
Epoch 29/30
43/43 [==============================] - 37s 869ms/step - loss: 0.4196 - tp: 985.0000 - fp: 279.0000 - tn: 1250.0000 - fn: 226.0000 - accuracy: 0.8157 - precision: 0.7793 - recall: 0.8134 - auc: 0.8859 - prc: 0.8316 - val_loss: 0.4754 - val_tp: 244.0000 - val_fp: 74.0000 - val_tn: 306.0000 - val_fn: 62.0000 - val_accuracy: 0.8017 - val_precision: 0.7673 - val_recall: 0.7974 - val_auc: 0.8592 - val_prc: 0.8097
Epoch 30/30
43/43 [==============================] - 37s 855ms/step - loss: 0.4189 - tp: 992.0000 - fp: 301.0000 - tn: 1228.0000 - fn: 219.0000 - accuracy: 0.8102 - precision: 0.7672 - recall: 0.8192 - auc: 0.8852 - prc: 0.8336 - val_loss: 0.4716 - val_tp: 247.0000 - val_fp: 73.0000 - val_tn: 307.0000 - val_fn: 59.0000 - val_accuracy: 0.8076 - val_precision: 0.7719 - val_recall: 0.8072 - val_auc: 0.8589 - val_prc: 0.8040
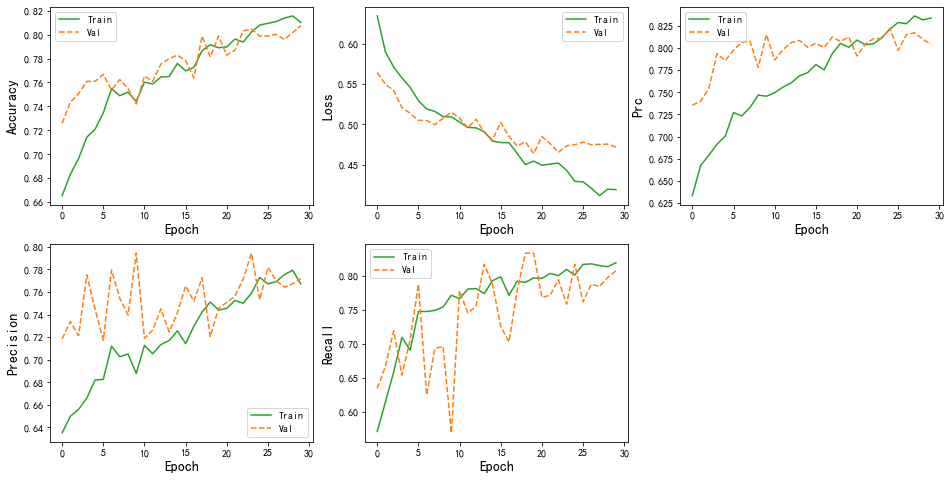
�����������
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (16, 8)
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']def plot_metrics(history):metrics = ['accuracy','loss', 'prc', 'precision', 'recall']for n, metric in enumerate(metrics):name = metric.replace("_"," ").capitalize()plt.subplot(2,3,n+1)plt.plot(history.epoch, history.history[metric], color=colors[2], label='Train')plt.plot(history.epoch, history.history['val_'+metric],color=colors[1], linestyle="--", label='Val')plt.xlabel('Epoch',fontsize=14)plt.ylabel(name,fontsize=14)plt.legend()plot_metrics(history)
�ġ����Ԥ��
# ��ȡ Word2Vec ������������д���������
def average_vec(words):# ��ȡ Word2Vec ģ��w2v = Word2Vec.load('w2v_model.pkl')vec = np.zeros(300).reshape((1, 300))for word in words:try:vec += w2v.wv[word].reshape((1, 300))except KeyError:continuereturn vec# �Ե�Ӱ���۽�������ж�
def model_predict(string):# �����۷ִ�words = jieba.lcut(str(string))words_vec = average_vec(words)# ��ȡ֧��������ģ��# model = joblib.load('svm_model.pkl')result = np.argmax(model.predict(words_vec))# ʵʱ���ػ������������if int(result) == 1:# print(string, '[����]')return "����"else:# print(string, '[����]')return "����"comment_sentiment = []# ��10������������
for index, row in df.iloc[:10].iterrows():print(row["evaluation"],end=" | ")result = model_predict(row["ȥ��ͣ�ôʺ������"])comment_sentiment.append(result)print(result)#�����������ԭ���ݺϲ�Ϊ������
merged = pd.concat([df, pd.Series(comment_sentiment, name='�û�����')], axis=1)
# �����ļ�
pd.DataFrame.to_csv(merged,'comment_sentiment.csv',encoding="utf-8-sig")
print('done.')
���Ӳ�������������ļ۸��ȥ����ˡ��� | ����
���Ӻ�������Ʒ��ֵ������ | ����
���Ӳ�����û�л��㣬©��Ҳ�������������������µ��Ӿ磬�е���Ӱ�����ϻ����ӿھͺ��ˣ���ʱû�ԡ�������ԤԼ�ͷ����Ҫ��������û������ͬ�������ͻ�ʱ��ĵ������壬���ͻ��������ˡ�����Ҫ���ͻ���������30���ȵ�������������ѵ��ӿ���5¥ | ����
����̫����е�С�������治�Ǻ��Ѻã���̩�ݺ��Ӳ�̫Զ�ˣ�������Ч��ɫ�ʲ�����©��϶� | ����
�ã��ͻ��ٶȿ죬����á�.3333333 | ����
��ĵ�һ̨������ �о��ܲ��� ϵͳ������ ������Ҳ���� ���Ǹ��˸о�ң�ص�ʱ����ж��ݵ��ӳ� ��۸����滹�Ǹо�ͦ�õ� �����λ�Լ۱Ȼ����� | ����
6.18��ģ�����ȴ�����д���ߣ�Ŀǰû���������⣬���۲� | ����
ͦ�õģ�����������ײ����ȣ��ۺ�װ220Ԫ��������һ��HIDMI������99Ԫ������58Ԫ�����ߵ����ߣ�һ�����˿�400��Ǯ���е㱻�ۺ�����ˣ���������һ�����������40�죡���ϸ����Żݣ������뷨���㣡 | ����
ͦ�õ� ���ǿ���Ʊ̫���� ���˺þõ����ڻ�û���� | ����
ͼ���Ӿ�ijߴ���Լ۱Ƚϸߣ�����Ҫ�ľ��Ǹ���ʱ��۸�Ҳ����̫���� | ����
done.