- ���⣺��ǰ��NER�Ĵ�����о���������һ��Ԥ�����NER�����ϣ�������������������֯�������ڵȵȣ��ṩ��һ�������ı��������ѵ��ģ�͡�Ȼ������ͬ��Ӧ�ó�����Ҫ�ض���ʵ�����ͣ��������������ġ�Brand������Product����������ҵ����Company�������ǵ��˹���ע�ĸ߳ɱ���Ϊÿ���µ�NER���ͱ�ע���������Dz����еģ�����ʱ����ʹ��С��ģ���ݡ�
- ������Զ�̼�ؿ���Ϊ����NER�Զ����ɴ��ģ�ı�����ݣ������˹���ע��
�������Ȼ��һ����������ʵ���б����ֵ䣬Ȼ�����Ǽ���������ᵽ��ÿ��ʵ�嶼���ֵ��ж�Ӧ���͵���ʵ�����Ӷ��Զ����ɴ��ģ�ı�����ݡ�Ȼ���������Զ����ɵ����ݴ���������Ҫ���⣺
- Incomplete annotations
- noisy annotations

- Distantly Supervised NER Data�����ȣ�������һ��С�ı�ע���ݼ�H,һ������ޱ�ע���ݼ�U�������ռ�����ʵ���������ֵ�D����ʹ��D�е�ʵ��ƥ��U�о��ӵ��ַ�����Ȼ�����ǻ���һ�����Ӽ��ϣ�ÿ�����������ٰ���һ��ƥ�䵽��ʵ�壬��ΪA������������H+A��ΪNERģ�͵�ѵ�����ݡ�
- The Baseline LSTM-CRF
- The input layer: ʹ��Ԥѵ����Word2vec������
- The BiLSTM layer.
- The MLP layer.
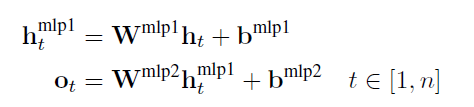
4. The CRF layer

Incomplete annotations
����Щ���ܸ����ֵ����ƥ���ַ���Ϊ��ʵ���Dz����ʵġ�

����Ϊÿһ��Զ����ල�ľ��ӱ�ʾһ���ǩ����z���������Ȼ��z��ÿ�����ܵı�ǩ����y�ĸ���֮�͡���softmaxӦ�������к�ѡ�����ǩ���У��Ӷ������һ��Զ�̼ලʵ���ĸ�������:

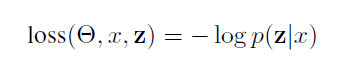
- noisy annotations��
���ǽ���ʼ���ֹ���ǵ����ݼ�H��Զ�̼ල�����ݼ�A�ϲ���һ����ѡ���ݼ�C�С����Ǵ�C���ռ�һ�������С��ʵ����ΪB�����ڵ�ǰ���е�ÿ��Զ�̼��ʵ����agent�Ӽ���{1.0}��ִ��һ��action�������Ƿ�ѡ���ʵ����������actions���ʱ��agent���յ�reward��reward��ʾ�˰��ϵ�actions�����������ڸ���agent��agent��Ŀ���Ǿ���actions�ܹ�ʹ�������
2. State representation��
״̬ st ��ʾ��ǰʵ�������ǩ���С����ǽ�״̬��ʾΪһ������ st������������Ϣ���:(1)��ǰʵ�������л�������ʾ����baselineģ�͵�BiLSTM��õ���(2)�ӹ���������MLP��������ǩ�÷֡�
3. Policy network.
agent����һ��action at �� {0,1} �����Ƿ��ѡ�����ʵ����
4.Reward
Reward����������ǰ��NE taggerԤ��ÿ���ַ���ǩ����������ģ����ɵ�ǰ���е�����ѡ��ʱ��������ӳٵ�ƽ��reward���ڴ�֮ǰ��ÿ��action��rewardΪ 0��
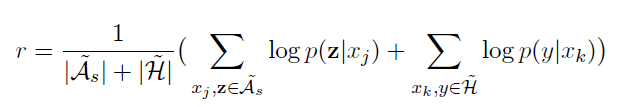
�͡�Reinforcement learning for relation classification from noisy data����ͬ���ǣ����ǵ�selector��������Щ����֪ʶ��ָ���½���ѵ������ȷ����Щ���ӱ���ȷ��ǡ���ˣ�reward����ÿɿ��Ͷ�����������ָ��select�����ѵ�����ݼ�������ʵ���Ŀ����ԡ�
Datasetes:
- EC: �ڵ�����������(EC)�����������͵�ʵ��: Brand, Product, Model, Material, and Specification�������ݰ���2400����ע�ľ��ӣ�ʹ��1200��������Ϊѵ������400��������Ϊ��֤����800��������Ϊ���Լ�����ѵ���������ռ�һ��ʵ���б��������ֵ䡣Ϊ�˼��������Ӱ�죬����ɾ�������ڶ�����͵�ʵ�壬��������һ�����ֻ��ַ����������ֵ���927��ʵ�塣������ԭʼ���ݼ���ִ��Զ�̼ල���ջ��2500�����ӡ�
- NEWS: ����������������ʹ������MSRA��NER���ݡ�ֻ��PERSON�������������ϵͳ���������ѡȡ��3000��������Ϊѵ�����ݼ���3328��������Ϊ�������ݼ���3186��������Ϊ�������ݼ�����������ݼ�����ԭʼ���ݣ���36,602�����ӡ����Ƕ�ԭʼ���ݽ���Զ�̼ල���õ�3722�����ӡ�
Experimental��



���Ǵ��˹���ע������H�������ȡ25%��50%�ľ�����Ϊѵ�����ݣ����ڴ˻����Ϸֱ��µ�ʵ���ֵ䡣ͨ��ʵ����������ʹ�ý�С���˹�ע�����ݣ���������ķ��������ṩ��Խϴ�ĸĽ���