A. ������ȷ�ļ����������precision��recall
Ϊ�˼���precision��recall�������л���ѧϰ����һ�������DZ�������True Positives������������False Positives������������True Negatives���渺������ False Negatives���ٸ�������
Ϊ�˻��True Positives and False Positives��������Ҫʹ��IoU������IoU�����ǴӶ�ȷ��һ���������Positive������ȷ�ģ�True�����Ǵ���ģ�False������õ���ֵ��0.5�������IoU> 0.5������Ϊ����True Positive��������Ϊ��False Positive����COCO���ݼ�������ָ�꽨��Բ�ͬ��IoU��ֵ���м��㣬��Ϊ��������������������һ����ֵ0.5������PASCAL VOC���ݼ����õ�ָ�ꡣ
Ϊ�˼���Recall��������ҪNegatives������������ͼƬ������û��Ԥ������ÿ�����ֶ�����ΪNegative����˼���True Negatives�Ƚ��Ѱ졣�������ǿ���ֻ����False Negatives��������ģ����©������塣
����һ����Ҫ���ǵ�������ģ���������ĸ�������������Ŷȡ�ͨ���ı����Ŷ���ֵ�����ǿ��Ըı�һ��Ԥ�����Positive���� Negative�����ı�Ԥ��ֵ��������(����box����ʵ�����ԣ���Ԥ��������)�������ϣ���ֵ���ϵ�����Ԥ�⣨Box + Class��������Ϊ��Positives�����ҵ��ڸ�ֵ�Ķ���Negatives��
����ÿһ��ͼƬ��ground truth���ݻ������ͼƬ�и�������ʵ���������������ǿ��Լ���ÿ��PositiveԤ�����ground truth��IoUֵ����ȡ����IoUֵ����Ϊ��Ԥ�������Ǹ�IoU����ground truth��Ȼ�����IoU��ֵ�����ǿ��Լ����һ��ͼƬ�и���������ȷ���ֵ��True Positives, TP�������Լ�������ֵ������False Positives, FP�����ݴˣ����Լ������������precision��

��Ȼ�����Ѿ��õ�����ȷ��Ԥ��ֵ������True Positives����Ҳ���������©�����������False Negatives, FN�����ݴ˿��Լ����Recall����ʵ��ĸ������ground truth��������

B. ����mAP
mAP��������в�ͬ�Ķ��塣�˶���ָ��ͨ��������Ϣ������Ŀ��������Ȼ���������������mAP�ķ�ʽȴ����ͬ����������̸ֻ��Ŀ�����е�mAP���㷽����
��Ŀ�����У�mAP�Ķ������ȳ�����PASCAL Visual Objects Classes(VOC)�����У����������������ͼ��������������Բο����paper������������������Ľ����Լ������ȣ���
ǰ�������Ѿ���������μ���Precision��Recall�����ǣ�����ǰ������������������������Ӱ��Precision��Recall����IoU�����Ŷ���ֵ��IoU��һ���ļ��ζ��������Ժ����ױ�����������PASCAL VOC�����в��õ�IoU��ֵΪ0.5����COCO�������ڼ���mAP�ϸ��ӣ��������һϵ��IoU��ֵ��0.05��0.95���µ�mAP���������Ŷ�ȴ�ڲ�ͬģ�ͻ����ϴ������ҵ�ģ�������ŶȲ���0.5ȴ�ȼ���������ģ���в���0.8���Ŷȣ���ᵼ��precision-recall���߱仯��Ϊ�ˣ�PASCAL VOC��֯���뵽��һ�ַ��������������⣬��Ҫ����һ�ֿ��������κ�ģ�͵�����ָ�ꡣ��paper�У������Ƽ�ʹ�����·�ʽ����Average Precision��AP����
For a given task and class, the precision/recall curve is computed from a method��s ranked output. Recall is defined as the proportion of all positive examples ranked above a given rank. Precision is the proportion of all examples above that rank which are from the positive class. The AP summarises the shape of the precision/recall curve, and is defined as the mean precision at a set of eleven equally spaced recall levels [0,0.1,��,1]:
���Կ�����Ϊ�˵õ�precision-recall���ߣ�����Ҫ��ģ��Ԥ������������ranked output�����ո���Ԥ��ֵ���ŶȽ������У�����ô����һ��rank��Recall��Precision���ڸ��ڸ�rankֵ��Ԥ�����м��㣬�ı�rankֵ��ı�recallֵ�����ﹲѡ��11����ͬ��recall��[0, 0.1, ��, 0.9, 1.0]����������Ϊ��ѡ����11��rank�����ڰ������Ŷ���������ʵ���ϵ���ѡ����11����ͬ�����Ŷ���ֵ����ô��AP�Ͷ���Ϊ����11��recall��precision��ƽ��ֵ������Ա�������precision-recall���ߣ����������������������һ�£�Ҫ�õ�Precision-Recall����(���¼��PR)���ߣ�����Ҫ�Լ��ģ�͵�Ԥ��������Ŀ�����ŶȽ������С�Ȼ�����һ��rankֵ��Recall��Precision�������Ŷȸ��ڸ�rankֵ��Ԥ�����м��㣬�ı�rankֵ����Ӧ�ĸı�Recallֵ��Precisionֵ������ѡ����11����ͬ��rankֵ��Ҳ�͵õ���11��Precision��Recallֵ��Ȼ��APֵ������Ϊ����11��Recall��Precisionֵ��ƽ��ֵ������Ա�������PR�����·����������
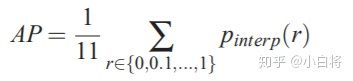
���⣬�ڼ���precisionʱ����һ�ֲ�ֵ������interpolate����
The precision at each recall level r is interpolated by taking the maximum precision measured for a method for which the corresponding recall exceeds r:
The intention in interpolating the precision/recall curve in this way is to reduce the impact of the ��wiggles�� in the precision/recall curve, caused by small variations in the ranking of examples.
������ij��recallֵr��precisionֵȡ����recall>=r�е����ֵ��������֤��p-r�����ǵ����ݼ��ģ��������߳���ҡ�ڣ�:
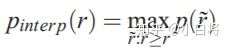
��������VOC���ݼ���2007�������mAP���㷽��������2010֮��ȴʹ�����������ݵ㣬�����ǽ�ʹ��11��recallֵ������AP����ϸ�ο���ƪpaper����
Up until 2009 interpolated average precision (Salton and Mcgill 1986) was used to evaluate both classification and detection. However, from 2010 onwards the method of computing AP changed to use all data points rather than TREC-style sampling (which only sampled the monotonically decreasing curve at a fixed set of uniformly-spaced recall values 0, 0.1, 0.2,��, 1). The intention in interpolating the precision�Crecall curve was to reduce the impact of the ��wiggles�� in the precision�Crecall curve, caused by small variations in the ranking of examples. However, the downside of this interpolation was that the evaluation was too crude to discriminate between the methods at low AP.
���ڸ�����𣬷ֱ���������ʽ����AP��ȡ��������APƽ��ֵ����mAP���������Ŀ����������mAP�ļ��㷽����������ʱ�ᷢ��Щ���仯����COCO���ݼ����õļ��㷽ʽ���ϸ�������˲�ͬIoU��ֵ�������С�µ�AP������ο�COCO Detection Evaluation����
���Ƚ�mAPֵ����ס����Ҫ�㣺
- mAPͨ������һ�����ݼ��ϼ���õ��ġ�
- ��Ȼ����ģ������ľ��������������ף���mAP��Ϊһ����ԽϺõĶ���ָ����������ǡ� �����������еĹ������ݼ��ϼ����������ʱ���ö������Ժ����������Ƚ�Ŀ����������¾ɷ�����
- ����ѵ�������и�����ķֲ������mAPֵ������ijЩ�ࣨ�������õ�ѵ�����ݣ��dz��ߣ��������ࣨ���н���/�������ݣ�ȴ�Ƚϵ͡��������mAP�������еȵģ��������ģ�Ϳ��ܶ�ijЩ��dz��ã���ijЩ��dz����á���ˣ������ڷ���ģ�ͽ��ʱ�鿴�������APֵ����ЩֵҲ����ʾ����Ҫ���Ӹ����ѵ��������
C. PR����
���ǵ�Ȼϣ�����Ľ��PԽ��Խ�ã�RҲԽ��Խ�ã�����ʵ����������ijЩ�������ì�ܵġ����缫������£�����ֻ������һ�����������ȷ�ģ���ôPrecision����100%������Recall�ͺܵͣ���������ǰ����н�������أ���ô��ȻRecall��Ȼ�ܴ���Precision�ܵ͡�
����ڲ�ͬ�ij�������Ҫ�Լ��ж�ϣ��P�Ƚϸ���R�Ƚϸߡ��������ʵ���о������Ի���Precision-Recall����������������
�������Ǿ�һ�������ӣ��������ǵ����ݼ��й���������������壬���ǵ�ģ������10����ѡ�����ǰ���ģ���������Ŷ��ɸߵ��ͶԺ�ѡ���������

����ڶ��б�ʾ�ú�ѡ���Ƿ�Ԥ����ȷ�����Ƿ����ij��������������ú�ѡ���iouֵ����0.5�������к͵����б�ʾ�Ը������ں�ѡ�����Ŷ�Ϊ��ֵʱ��Precision��Recall��ֵ�������Ա���ĵ�����Ϊ�����м��㣺

���ϱ���RecallֵΪ���ᣬPrecisionֵΪ���ᣬ���ǾͿ��Եõ�PR���ߡ����ǻᷢ�֣�Precision��Recall��ֵ���ָ���أ��ھֲ���������²�����

D. AP(Average Precision)
����˼��AP����ƽ�����ȣ�����˵���Ƕ�PR�����ϵ�Precisionֵ���ֵ������pr������˵������ʹ�û��������м��㡣

��ʵ��Ӧ���У����Dz���ֱ�ӶԸ�PR���߽��м��㣬���Ƕ�PR���߽���ƽ������������PR�����ϵ�ÿ���㣬Precision��ֵȡ�õ��Ҳ�����Precision��ֵ��

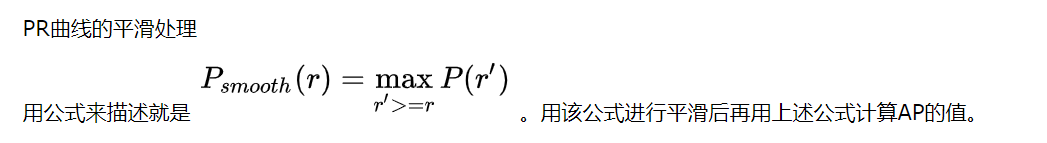
E. Interplolated AP��Pascal Voc 2008 ��AP���㷽ʽ��
Pascal VOC 2008������IoU����ֵΪ0.5�����һ��Ŀ�걻�ظ���⣬�����Ŷ���ߵ�Ϊ����������һ��Ϊ����������ƽ��������PR�����ϣ�ȡ����0-1��10�ȷֵ㣨�����ϵ㹲11���㣩��Precision��ֵ��������ƽ��ֵΪ����AP��ֵ��

F. Area under curve
��������������ȱ�ݣ���һ����ʹ��11���������ھ��ȷ��������ʧ���ڶ����ǣ��ڱȽ�����APֵ��С��ģ��ʱ���������ֳ����ߵIJ���������ַ�����2009���Pascalvoc֮��㲻�ٲ����ˡ���Pascal voc 2010֮�㿪ʼ�������־��ȸ��ߵķ�ʽ�����Ƴ�ƽ�����PR���ߺ��û��ֵķ�ʽ����ƽ�������·��������Ϊ���յ�APֵ��

�����
- https://zhuanlan.zhihu.com/p/37910324
- https://www.cnblogs.com/hanhao970620/p/12422473.html