����Ŀ¼
- ���±��⣺���ܣ����������ĸɾ���ǩ���ж�����-NeurIPS 2018
-
- ժҪ
- 1. ����
-
- 1.1 ��ع���
- 1.2 ����
- 2. һ�ּĸɾ���ǩ����
-
- 2.1 ͨ��������ײ�����к�����
- 2.2 �Ż�����
- 3. Ǩ��ѧϰ�е��ж�����
-
- 3.1 һ��һ����ɱ�Ĺ���
- 4. �Զ˵���ѵ�����ж�����
-
- 4.1 ����ʵ������
- 4.2 ˮӡ��һ����ǿ�ж����������ķ���
-
- 4.2.1 ���ж�ʵ������
- 5. ����
- 6. ��л
- �����
���±��⣺���ܣ����������ĸɾ���ǩ���ж�����-NeurIPS 2018
ժҪ
�����ж��ǶԻ���ѧϰģ�͵Ĺ����������߽��������ӵ�ѵ�����У��Ա��ڲ���ʱ����ģ�͵ı��֡�����̽���˶���������ж�����������Ĺ���ʹ�á��ɾ��ı�ǩ�������Dz�Ҫ���߶�ѵ�����ݵı�ǩ���κο��ơ�����Ҳ����Ŀ�ĵģ����ǿ����ض�����ʵ���Ϸ������ı��֣������ή�����������������ܡ����磬�����߿���������ʶ�������ѵ����������һ����������ͼ�����DZ���ȷ��ǵģ������ڲ���ʱ���Ʊ�ѡ�е��˵����ݡ����ڹ����߲���Ҫ���Ʊ�ǩ���ܣ����ֻ�轫�������������ϣ��ȴ����DZ������ռ������ˣ����棩ץȡ���Ϳ��Խ��������뵽ѵ�����С�
�����һ�ֻ����Ż��Ķ������ɷ�������֤������Ǩ��ѧϰ������£���������ͼ����ܿ��Ʒ���������Ϊ�����������Ķ˵���ѵ�������������һ�֡�ˮӡ�����ԣ�ʹ�ö������50���ж���ѵ����������֤�����Ŀɿ��ԡ�����ͨ����CIFAR���ݼ������ж�������ͼ��ʹ������������ͼ�����������֤���ǵķ�����
1. ����
�ڽ����ѧϰ�㷨���߷��ա���ȫ�ؼ���Ӧ�ó�����֮ǰ������������ǶԶԿ��Թ�����³���ԡ���������磨DNNs���д��ڶԿ������������˹�����Щ�������İ�ȫ�Եı���[Szegedy���ˣ�2013�ꣻGoodFelet al.��2015�ꣻBiggio���ˣ�2013��]���Կ��Ե���������һ�౻��Ϊ�ӱܹ�����evasion attacks���Ĺ������ӱܹ�������������ʱ�����ĸɾ���Ŀ��ʵ�����ӱܷ������ļ�⣬���´�����ࡣ���ǣ���Щ����������ӳ�䵽�ض�����ʵ����������Щ�����й����������Ʋ���ʱ�����ݡ����磬����������ͨ������ML�������ʼ����������������ֵĵ����ʼ����Ϊ�����ʼ������ݹ��������ã���Ϊ�����������ܺ��ߵĵ����ʼ���ͬ�������˿������ı��ڼල�����¹���������ʶ����������룬�簲��̨���¥��ڴ�������ϵͳ��Ȼ�����ܵ������ж���������Щ����������ѵ��ʱ�䣻���ǵ�Ŀ����ͨ����ѵ�������в��뾫�Ĺ���Ķ�������������ϵͳ�����ܡ�
�����о��������������ж�����������ζ�����ǵ�Ŀ������һ���ض��IJ���ʵ���Ͽ��Ʒ���������Ϊ�����磬���Dz�������ʶ�������������ض���Ա�����ݣ����߲��������ʼ�������������/�ܾ�������ѡ����ض������ʼ�����������˲���Ҫ���Ʊ�ǩ���ܵĸɾ���ǩ��������һλר�ҹ۲���˵���ж���ѵ�������ƺ�����ȷ�������˱�ǩ���ⲻ��ʹ�������Լ�⣬����Ϊ�����ߴ��˳ɹ��Ĵ��ţ�����������κ��ڲ������ռ�/��ǹ��̡����磬���ֿ��Խ��ж���ͼ��ŵ����ϣ�Ȼ��ȴ�һ���������ռ����ݵĻ����˶����ǽ���ץȡ�����������������̿���ͨ������֯�е���Ա�������ʼ����������ʼ����˹������ݼ���
1.1 ��ع���
������ж�������������ؽ����˲��Ե�ȷ�ԣ�����������ض������ӣ�ʹ���Ǹ����ױ����֡���Ȼ�й���֧���������ϵ��ж��������о�[Biggio���ˣ�2012��]��Bayes������[Nelson���ˣ�2008��]�����������������ж�����(DNN)���ٱ��о��������е������о��У�DNN�ѱ�֤���������ж��������������Ե�ʧЧ��Steinhardt����[2017]����˵����ʹ��ǿ��ķ����£��������߱�������ѵ��������3%����ʱ�����Ե�ȷ��Ҳ�ή��11%��Muoz-Gonz��lez����[2017]�����һ�ֻ��ں��ݶȵIJ�������ķ�����Ϊ�˼ӿ�����ж������Ĺ��̣�Yang����[2017]����һ�ֲ�������ķ�������
��Σ�յķ����ǹ��������ض��IJ���ʵ�������磬�����ᵽ�������̣����˴ﵽ����Ŀ��֮�⣬�����������ʼ�������ʧЧ��Ҳ�������ܺ���֪�����Ĺ������ڡ�������Եĺ��Ź���(Chen���ˣ�2017)ʹ��������Դ(?50ѵ��ʾ��)�������֤�����·��������������ʾ����ʧ�ܡ��˵�[2017]ʹ�ô�������ͼ����ǵĴ����ǩ���ͼ��ѵ�����磬ʹ�������˽�ͼ�������ǩ֮��Ĺ�������������[2017]�����������Ӧ��������ľ����������ѵ����
**��Щ�������ӱܹ���������ͬ��ȱ�㣻������Ҫ�IJ���ʱʵ���Դ���Ԥ��ʧ��**���⣬�ڴ������ǰ�Ĺ����У������߱��ٶ���ѵ�����е������ı�ǹ�����ij�̶ֳȵĿ��ơ����������ų�����ʵ�ij�������ѵ�������˹������Ա��ˣ������Ա����ÿ��ʾ������ʱΪ�����ϱ�ǩ�����߱�ǩ���ⲿ���̷��䣨���羭���ռ��ɵ�������������ǵ�ground-truth�Ķ�����������������Ա�ǩ���ܵĿ��Ƶ�����һ�μ�һ���Թ��������д��з�ת��ǩ��Ŀ��ʵ������Ϊ�������ӡ��Զ���Ĺ���Ͻ�ȷ��Ŀ��ʵ��������ʱ��������ࡣ��������������صĹ�����Suciu��������[2018]���о������������Ĺ�����Ȼ�������ֹ���Ҫ��ҩ��ÿһС��������ռ12.5%(���100%)������ʵ���п����Dz���ʵ�ġ��෴�����ǵĹ�������Ҫ��С�����ι��̽����κο��ƣ����Ҽ����ж�Ԥ��ҪС�ö�(<0.1%��>12.5%)��
�������ע��м������״����۵ĽǶ�̽�����ж����⡣Mahloujifar��Mahmoody[2017]��Mahloujifar����[2017]�����۵ĽǶ��о��ж���вģ�ͣ���Diakonikolas���˰���[2016��]�����˷�������ѵ�������Ŷ���³���ԡ�
1.2 ����
��������У������о���һ���µĹ������ͣ��Ӵ��Ժ��Ϊ�ɾ���ǩ������������ע���ѵ��ʾ������֤���������ر�ǣ������DZ��������Լ���������ϱ�ǩ�����ǵIJ��Լ��蹥���߲��˽�ѵ�����ݣ������˽�ģ�ͼ������������һ�������ļ��裬��Ϊ�����ڱ����ݼ���Ԥ����ѵ���ľ������磬������Imagenet����ѵ����Resnet[He et al.��2015]��Inception[Szegedy et al.��2014]����������������ȡ���������ߵ�Ŀ���ǵ������ڰ����ж�ʵ������ǿ���ݼ��Ͻ�������ѵ����ʹ����ѵ�������罫һ���ض�����ʵ����һ���ࣨ����һ����������������ط���Ϊ��ѡ�����һ���ࣨ��������Ӧ�ó�������Ŀ���Ԥ��Ԥ�����֮�⣬�ܺ��ķ������������½��������ԡ���ʹ�����Ƚ��ĺ���ѵ��ʵ��(��Barreno���ˣ�[2010])������Ӱ����ж�������ʩ��Ч��
ʹ��Ӱ�캯��(Koh����[2017])��ʾ���������͵Ĺ���������������£�ֻ����������ȫ���Ӳ����ж����ݼ��ϱ�����ѵ�����ɹ���Ϊ57%����Koh����(2017)�о���Ǩ��ѧϰ�����£�������ʾ��һ�ֻ����Ż��ĸɾ���ǩ��������������ͬ�Ĺ�������������ϣ����ǻ����100%�Ĺ����ɹ��ʡ����⣬���ǵ�һ���о��˸ɾ���ǩ�ж��ڶ˵���ѵ�������е����ã�����������£���������в㶼��������ѵ����ͨ�����ӻ������ǽ�ʾ��Ϊʲô�����������ı��������������Ҫ���ѵöࡣ����Щ���ӻ���ָ���£�������һ���������Ͻ�����һ��50���ж�ʵ���Ĺ������ڶ˵��˵�ѵ�������дﵽ�˸ߴ�60%�ijɹ��ʡ�
2. һ�ּĸɾ���ǩ����
�������������һ�ֻ����Ż��Ĺ��̣�������������ʵ���������ӵ�ѵ��������ʱ�����ݷ������IJ���ʱ�ı��֡��Ժ����ǽ��������������ּ�����������
���������ȴӲ��Լ���ѡ��һ��Ŀ��ʵ����һ�γɹ����ж����������´�Ŀ��ʵ���ڲ����ڼ䱻������ࡣ�������������ߴӻ����в���һ������ʵ�������������DZ��Ĭ���ĸ��ģ��Դ���һ���ж�ʵ����Ϊ����ƭģ�ͣ��ڲ���ʱ��Ŀ��ʵ�����Ϊ������ǩ�����ģ�ͽ����ж����ݼ����ɾ����ݼ�+��ʵ������ѵ��������ڲ���ʱ��ģ�ͽ�Ŀ��ʵ������ض�λ�ڻ����У���ô�ж������ͱ���Ϊ�dzɹ��ġ�
2.1 ͨ��������ײ�����к�����
��f(x)��ʾ������xͨ�����紫���������ڶ���(SoftMax��֮ǰ)�ĺ��������ǽ���һ��ļ����Ϊ����������ռ��ʾ����Ϊ�������˸���������������f�ĸ߶ȸ����Ժͷ����ԣ������������ռ����ҵ���Ŀ�ꡰ��ײ��������x��ͬʱ��������ռ���ͬʱ�ӽ���ʵ��b��ͨ�����㣺
p=argminx�O�Of(x)?f(t)�O�O22+�¨O�Ox?b�O�O22ʽ(1)p = \underset{x}{argmin} || f(x) - f(t)||^2_2 + \beta || x - b ||_2 ^2 \space \space \space \space ʽ(1)p=xargmin?�O�Of(x)?f(t)�O�O22?+���O�Ox?b�O�O22? ʽ(1)
����1������һ��ʹ�ж�ʵ��p����һ����������Ա��˵�Ե�����һ���������ʵ����(�²���������һ��ij̶�)��������ᱻ������ǡ�ͬʱ������1�ĵ�һ��ʹ��ʵ���������ռ�������Ŀ��ʵ������Ƕ��Ŀ����ֲ��С���һ���ɾ���ģ���ϣ��������ʵ�������������ΪĿ�ꡣ���ǣ����ģ���ڸɾ�������+����ʵ������ѵ������ô�����ռ��е����Ծ��߽߱罫����ת������ʵ�����Ϊ���ࡣ����Ŀ��ʵ���ڸ��������Ծ��߽߱���ת���ܻ������а��������е�Ŀ��ʵ���Լ�����ʵ����ע�⣬ѵ����Ϊ����ȷ�ط����ʵ����������Ŀ�꣬��Ϊ���߲���ѵ������һ���֣���������δ�ܸ��ŵ�Ŀ��ʵ��������ڲ���ʱ������ط��ൽ�����У���ȡ����������еġ����š���
2.2 �Ż�����
�������㷨1��չʾ�ڵ�ʽ1��ִ���Ż��Ĺ��̣��Ի��p�����㷨����ǰ�����ѵ�����[Goldstein���ˣ�2014]����һ��(��ǰ)ֻ��һ���ݶ��½����£����������ռ���С����Ŀ��ʵ����L2���롣�ڶ���(����)��������ռ��н�Frobenius���ʵ��֮��ľ�����С���Ľ��˸��¡�������ռ��У�����ϵ���� ��ʹ�ö���ʵ��������ռ俴������ʵ��������ƭ�����ĵ�����۲�����Ϊ����ʸ��ͼ��û�б��۸ġ�

3. Ǩ��ѧϰ�е��ж�����
���������о�Ǩ��ѧϰ�����������������£�ʹ��Ԥ��ѵ����������ȡ���磬ֻ�����յ�����(Softmax)�㱻ѵ������ʹ������Ӧ�ض���������������ڹ�ҵ�кܳ���������ϣ��������������ѵ��һ����׳�ķ�����������������£��ж������Ƿdz���Ч�ġ��ڵ��Ľ��У����ǽ���Щ��������Ϊ�˵���ѵ���������
�������������ж�ʵ�顣���ȣ����ǹ���Ԥ��ѵ����Inception V3 [Szegedy���ˣ�2016]���磬�ڲ��������һ������в��Ȩ�ر����������¡����ǵ���������ݼ�(ImageNet [Russakovsky���ˣ�2015] dog-VS-fish)��Koh����[2017]����������ݼ���ͬ����Σ����ǹ�����krizhevsky��Hinton[2009]ΪCIFAR-10���ݼ��ĵ�AlexNet��ϵ�ṹ������������£����в㶼������ѵ����1
3.1 һ��һ����ɱ�Ĺ���
�������������һ������ת��ѧϰ�����е��ж�����������������£���һǹɱ���������ǿ��ܵģ�ͨ����ѵ����������һ������ʵ��(���ɿɿ���ר�ұ��)�����Ǿ�����100%�ijɹ��ʶ�Ŀ����д�����ࡣ������Koh����[2017]һ�������ǻ���������Inception V3��Ϊһ��������ȡ����������ѵ��������ȫ���Ӳ��Ȩ�أ��Ա��ڹ�����֮����з��ࡣ���Ǵ�ImageNet�е�ÿ������ѡ��900��ʵ����Ϊѵ�����ݣ�����ѵ��������ɾ�����������е��ظ�����ΪԤ�������衣
֮�����ǽ�����1099������ʵ������Թ����698������ʵ����401���������IJ���ʵ���������ǴӲ��Լ���ѡ��Ŀ��ʵ���ͻ���ʵ������ʹ��maxIters=1000���㷨1����һ����ʵ��������ImageNet�е�ͼ����в�ͬ��ά����������������=��0?20482/(dimb)2\beta = \beta_0 * 2048^2 / (dim_b)^2��=��0??20482/(dimb?)2������ʽ1�Ħ£��������˻�ʵ��(dimbdim_bdimb?)��ά����Inception V3�������ռ���ֲ㣨2048����ά���������ڡ�������ʵ����ʹ����0=0.25��_0=0.25��0?=0.25��Ȼ�����ǽ���ʵ�����ӵ�ѵ�������У���ִ��������ѵ��(����δ�����Ȩֵ��ʼ��Ϊ���ֵ)������ʹ�þ���0.01��ѧϰ���ʵ�ADAM�Ż�����100��epochs���������ѵ����
ʵ�������1099��-ÿ���Բ�ͬ�IJ��Լ�ͼƬ��ΪĿ��ʵ��-�����100%�Ĺ����ɹ��ʡ���Ϊ�Ƚϣ�KOH����[2017]�о���Ӱ�캯�����ijɹ���Ϊ57%����λ����������Ŷ�Ϊ99.6%(ͼ1b)�����⣬��������ȷ�ȼ��������ж�Ӱ�죬ƽ���½�0.2%��������Ϊ0.4%�������������д�ԭ����99.5%��һЩ����Ŀ��ʵ��������Ӧ���ж�ʵ����ͼ1a��ʾ��
��ע�⣬��Ǩ��ѧϰ�����ϻ��100%�ijɹ���ͨ���Dz����ܵġ�����֮�����ܹ���dog-VS-fish������ʹ��inception v3�����˸ߵijɹ��ʣ�����Ϊ�и���Ŀ�ѵ��Ȩ��(2048)����ڱ�ѵ������(1801)��ֻҪ���ݾ������ظ�ͼ������Ҫ������ҵ�Ȩ�������ķ����飬��������ѵ�����ݽ��й�����ϡ�����Ҫ���ķ�����������е�ѵ�����ݶ���Ƿȷ���ģ�������ѵ�����ݵĹ�������ǿ϶��ᷢ���ġ�

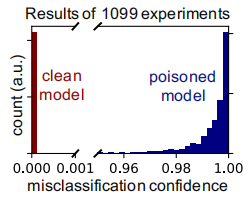
(b)����ȷ��������ֱ��ͼԤ���Ŀ��ͼ�����(����ɫ)���ж�(����ɫ)ģ�͡������ж������ݼ��Ͻ���ѵ��ʱ��Ŀ��ʵ����������������ˣ������кܸߵ����Ŷȡ�
Ϊ�˸��õ�������ʲô���¹����ɹ������ǻ����˸ɾ��ĺ��ж�������ľ��߽߱�֮��ĽǶ�ƫ��(��Ȩ������֮��ĽǶȲ�)����ͼ2��ʾ(��ɫ���κ�����)����ƫ���Ƕ��ж�ʵ������ѵ��ʹ���߽߱���ת���������������ڵ��ж�ʵ���ij̶ȡ�����ƫ����Ҫ��������ͼ2b��ʾ�ĵ�һ��epoch�У��������ʹʹ�ô�����ѵ��������������Ҳ���ܳɹ���ƽ��23�ȵ�����ƫ��(ͼ2a)����������ʵ�������ղ�ľ��߽߱������ʵ���Ը��ġ���Щ�����֤�����ǵ�ֱ������Ŀ��Ĵ�����������ھ��߽߱�ı仯��ɵġ�
�����ǵ���Ҫ��ʽ1ͨ����L2�������ٽ�����ͻ���ͼ��֮��������ԣ�������ͨ��L��Ϊ2(�Ӷ�̬��Χ255)�ٽ�������ʱ����õijɹ���Ϊ100%��������Koh����[2017]��������������ʵ���ϸ���ڲ�����������˽��ܡ�
�����ʵ������һ����Ԫ���������Ͻ��е�(�������͡��㡱)��Ȼ������������������û��ʩ����ͬ���ж���������ơ��ڲ�������У���������˶����ʵ�飬����������һ���µ��ࡰcat�����������DZ������ڱ��ָɾ�����ͼ����96.4%��ȷ�ʵ�ͬʱ����3����������Ȼ�ﵽ��100%���ж��ɹ��ʡ�

4. �Զ˵���ѵ�����ж�����
�����ڵ������п������ж�������Ǩ��ѧϰ�Ƿdz���Ч�ġ������в㶼����ѵ��ʱ����Щ�����ͱ�ø������ѡ�Ȼ����ʹ�á�ˮӡ�����ɺͶ����ʵ����������Ȼ������Ч�ض����˵������硣
���ǵĶ˵���ʵ�鼯����cifar-10���ݼ�����С��alexnet��ϵ�ṹ(�����¼)������Ԥѵ��Ȩֵ��ʼ��(������)������ADAMѧϰ��Ϊ1.85��10?5��������Ϊ128����10��epoch�ڽ����Ż���
�������������������������ȷ����������epochs����ʧ�Ǻ㶨�ġ�
4.1 ����ʵ������
���Ǵ�һ��˵���Ե�ʾ����ʼ����ʾ��˵����ʹ�õ�������ʵ���������硣���ǵ�Ŀ���ǹ�˼��ҩ��������Ϊ��Ӱ�죬������Ϊʲô�˵���ѵ���µ��ж�������Ǩ��ѧϰ���ѡ�ʵ���У��������ѡ�ɻ�����ΪĿ���࣬�����ܡ���Ϊ���ࡣ���ڴ����к�ʵ��������ʹ�õĦ�ֵΪ0.1����������Ϊ12000��ͼ3a��ʾ��ͨ����193ά����������ͶӰ����άƽ���϶����ӻ���Ŀ�ꡢ���Ͷ������ռ��ʾ����һά�����ż�������Ŀ��������ĵ�����(u=?base??targetu = ?_{base} - ?_{target}u=?base???target?)�����ڶ�ά������u��������������u�ͦ������ǵ�ƽ����(�����ڶ����Ȩ�����������Ծ��߽߱�ķ���)�����ͶӰ�������Ǵ�һ����õر�ʾ������(Ŀ��ͻ�)����Ĺ۵������ӻ����ݷֲ���
Ȼ��ͨ��ʹ�øɾ�����+��������ʵ����ѵ��ģ���������ж�������ͼ3a��ʾ��Ŀ�ꡢ���Ͷ�ʵ���������ռ��ʾ���Լ��ڸɾ�(δ�����)���ж�(�����)ģ���µ�ѵ�����ݡ������Ǹɾ���ģ�������ռ��ʾ�У�Ŀ��ʵ���Ͷ�ʵ�����ص��ģ���������ǵĶ������Ż�����(�㷨1)�ǿ��еġ���ֵ��ǣ���Ǩ��ѧϰ������ͬ���ǣ����һ����߽߱���ת����Ӧ�������ڵĶ�ʵ�����˵���ѵ�������еľ��߽߱��ھ����ж����ݼ���ѵ���ֲ��䣬��ͼ2�еĺ�ɫ����ͼ������ʾ��
�ݴˣ��������������Ҫ�������ʹ�ö����ݽ�����ѵ���ڼ䣬��������dz���еĵͼ�������ȡ�����ˣ��Ա㽫��ʵ�����ص�����еĻ���ֲ��С�

���仰˵����ʵ���������������ڲ��е�������ȡ�������е�ȱ�ݣ��Ӷ��������ռ��н���ʵ��������Ŀ���Աߡ������类����ѵ��������к���ʵ���ϣ���Ϊ�������Ϊһ��������ô��Щ���ڵ����Ծ�����ȱ�ݾͻᱻ���������ҽ���ʵ�����ظ�����ַ�����һ�������������ʵ�����ɺ�����ѵ����Ŀ����������ģ���ˣ�һ����һ�Ķ�����ܲ��������������˵��ⲿĿ������ӡ�Ϊ��ʹ�����ɹ������DZ����ҵ�һ�ַ�������ȷ��Ŀ��Ͷ�ʵ��������ѵʱ�����������ռ��з��롣
4.2 ˮӡ��һ����ǿ�ж����������ķ���
Ϊ�˷�ֹѵ���еĶ����Ŀ����룬����ʹ����һ������Ч�ļ��ɣ���Ŀ��ʵ���ĵͲ�����ˮӡ���ӵ��ж�ʵ���У�������ijЩ���ɷָ�������ص���ͬʱ�����Ӿ��ϵIJ�ͬ����ὫĿ��ʵ����ijЩ���Ի�ϵ���ʵ���У����Ҽ�ʹ������ѵ����Ҳ��ʹ��ʵ��������Ŀ��ʵ���������ռ丽����ˮӡ������Chen�������й㷺��Ӧ��[2017]�������ǵĹ�����Ҫ������ʱ����Ӧ��ˮӡ���ڹ�����������Ŀ��ʵ��������£����Dz���ʵ�ġ�

��60������ж������У���12�γɹ��ص�������Ŀ��ʵ���ڶ˵���ѵ�������б�����ع���Ϊ���������춾��ʱ����Ŀ����ʵ���ĶԿ�ˮӡ(������30%)Ӧ���ڻ���ʵ����
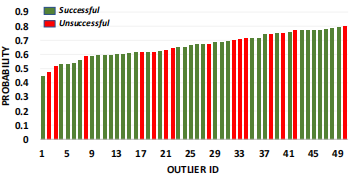
(a)��������Ⱥ��Ŀ��ɻ�������ͼ��ʾ����ǰĿ��ʵ���ĸ���(ʹ��Ԥ��ѵ�����������)����ɫ����ʾ�����dzɹ��Ļ���ʧ�ܵġ�ÿ��ʵ��ʹ��30%��ˮӡ�����Ⱥ�50�ֶ�ҩ������50���쳣���У�70%�Ĺ����ɹ�(�����Ŀ��Ĺ����ɹ���Ϊ53%)��

(b)�����Բ�ͬ���IJ�ͬĿ��Ĺ����ɹ���ȡ������ʹ�õĶ��������ͻ���ʵ�������ӵIJ�ͬĿ�겻���ȡ�
���û�b��Ŀ��ͼ��t��b����?t+(1?��)?bb����*t + (1 - ��) * bb����?t+(1?��)?b�ļ�Ȩ��ϣ��γɾ���Ŀ�겻���ȦõĻ�ˮӡͼ�����������ʾ��һЩ���ѡ��Ķ���ʵ��������ijЩĿ��ʵ����ˮӡ�����ߴ�30%�IJ��������Ӿ��ϲ������ԡ�ͼ4ʾ�������ڳɹ���������Ŀ��ʵ����60���ж�ʵ����
4.2.1 ���ж�ʵ������
�ڶ˵��˵�ѵ�������У��ж��Ǻ����ѵģ���Ϊ����ѧϰ������Ƕ�����ŵ�����Ŀ��Ͷ�����ǣ�������ǽ����Բ�ͬ����ʵ���Ķ���к�ʵ������ѵ�������ֻ�����أ�
Ϊ��ʹ�������ֿ�������������ѧϰһ�������ж�ʵ����Ŀ����������Ƕ�룬ͬʱȷ��Ŀ��ʵ��������Ŀ��ֲ��С�������ʵ���б�����ʹ�ø߶ȶ����ԵĻ����Է�ֹ�еȹ�ģ������ѧϰ��ͬ�ڻ�����Ŀ�����������ˣ������类����ѵ��ʱ��Ŀ��ʵ���붾ʵ��һ����������ֲ������ҹ���ͨ���dzɹ��ġ���Щ����ѧ��ͼ3b��ʾ��
��ͼ2�У����ǹ۲쵽����ʹ�ڶ�ζ���ʵ���У����ղ���ж��߽�Ҳ���ֲ��䡣���������Ǩ��ѧϰ�Ͷ˵��˵�ѵ�������У��ж��ijɹ���һ��������ͬ�Ļ��ơ�Ǩ��ѧϰͨ����ת���߽߱�������Ŀ�꣬�Ӷ��Զ��������Ӧ�����˵���ѵ��ͨ����Ŀ�����������ֲ���(�������ռ���)������Ӧ���ڶ��ж����ݼ�������ѵ��ʱ���˵��˳����еľ��߽߱���Ȼ����ƽ��(��ijһ�̶ȵķ����仯)����ͼ2��ʾ��
Ϊ�������ж�ʵ���������Գɹ��ʵ�Ӱ�죬���Ƕ�1��70֮���ÿ���ж�ʵ��������ʵ��(����Ϊ5)��ʵ��ʹ���˴Ӳ��Լ������ѡ���Ŀ��ʵ����ÿ�ֶ��ﶼ���ɲ��Լ��е������������(���¶���֮������������Ժܴ�)��ˮӡ�IJ�����Ϊ30%��20%��������ǿ������Ŀ��֮��������ص��������ɹ���(����30���������)��ͼ5b��ʾ����CIFAR-10�ж�һ����ͬ��Ŀ�������ظ���30��ʵ�飬����֤�ɹ��ʲ��������ࡣ���ǻ�����һ�����͵IJ����ȣ��۲쵽�ɹ����½����ɹ������ж�ʵ���������Ӷ��������ӡ�50��Ͷ������Թ�����ijɹ���ԼΪ60%��ע�⣬ֻ�е�Ŀ�걻����Ϊ��ʱ�����Dz���Ϊ�ɹ�����ʹĿ��ʵ�����������Ϊ��������࣬����Ҳ����Ϊ�Dz��ɹ��ġ�
���ǿ���ͨ����������Ⱥ���������һ�����ijɹ��ʡ���ЩĿ��Զ���������е�����ѵ�����������Ӧ�ø�����ת���ǵ����ǩ�����ǵ�Ŀ����50�ܡ��ɻ��������ǵķ������Ŷ����(����Ȼ��ȷ)��ÿ�ι���ʹ��50ֻ���ܡ���ι����ijɹ���Ϊ70%(ͼ5a)�������ѡ���Ŀ��߳�17%��
��֮���˵��˷����µĸɾ���ǩ������Ҫ���ּ������ܹ�����
(1)�㷨1���Ż���(2)����ʵ���Ķ����ԣ�(3)ˮӡ���ڲ�������У������ṩ��50�ֶ�������������о���֤ʵ�����ּ������dzɹ��ж��ı�Ҫ������
5. ����
�����о���������Ե�����ǩ�ж���������ѵ��ʱ�������磬Ŀ���Dz��ݲ���ʱ����Ϊ����Щ�������Ѽ�⣬��Ϊ�����漰�ǿ���(��ȷ��ǵ�)ѵ�����ݣ�Ҳ�����ڷ�����Ե������Ͻ������ܡ�������Ĺ��������������ռ�����Ŀ��ͼ����ײ���Ӷ�ʹ���������Էֱ�����Ŀ��ͼ����Щ������Ǩ��ѧϰ�������Ƿdz�ǿ��ģ����ҿ���ͨ��ʹ�ö���ж�ͼ���ˮӡ�����ڸ�һ����������б��ǿ��
ʹ�ö����ѵ�������ڶԿ�ѵ���������Է�ֹ�ӱܹ�����Goodfeler���ˣ�2015�꣩������ʵ����������Կ����ǻ���ĶԿ���ʾ������Ȼ���ǵ��ж����ݼ�ѵ��ȷʵʹ�������ƺõĴ������ΪĿ��Ļ���Կ��������ӽ�׳�������ᵼ��δ���ĵ�Ŀ��ʵ��������ع���Ϊ�������Ķ����ֶԿ���ѵ���ĸ����ý�����̽�֣�ֵ�ý�һ���о���
����������ʹ�����ױ����ֲ��ݵ�����Դ����ѵ��������ϣ�����������������ݿɿ��Ժ���Դ��һ��Ҫ����Ĺ�ע��
6. ��л
�ԡ�
�����
�ԡ�
The code is available at: ??