jieba �ִʻ��� ���£�
�����ʵ�
ʹ�� add_word(word, freq=None, tag=None) �� del_word(word) ���ڳ����ж�̬�Ĵʵ䡣
ʹ�� suggest_freq(segment, tune=True) �ɵ��ڵ�������Ĵ�Ƶ��ʹ���ܣ����ܣ����ֳ�����
ע�⣺�Զ�����Ĵ�Ƶ��ʹ�� HMM �´ʷ��ֹ���ʱ������Ч��
���ֵ���е���ʾ����
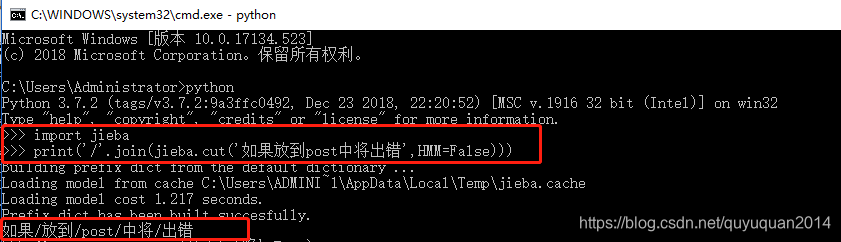

���Ա�ע
jieba.posseg.POSTokenizer(tokenizer=None) �½��Զ���ִ�����tokenizer ������ָ���ڲ�ʹ�õ� jieba.Tokenizer �ִ�����jieba.posseg.dt ΪĬ�ϴ��Ա�ע�ִ�����
��ע���ӷִʺ�ÿ���ʵĴ��ԣ����ú� ictclas ���ݵı�Ƿ���
�÷�ʾ��
# ���Ա�ע
import jieba.posseg as psegwords = pseg.cut("�Ұ������찲��")
# words���Ϊ��generatorfor word, flag in words:print('%s %s' % (word, flag))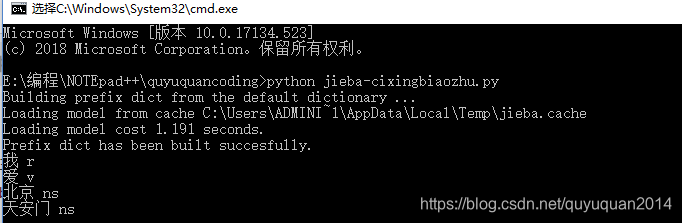
�ؼ�����ȡ
���� TF-IDF��term frequency�Cinverse document frequency�� �㷨�Ĺؼ��ʳ�ȡ
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence ��Ϊ����ȡ���ı�
topK�� Ϊ���ؼ��� TF/IDF Ȩ�����Ĺؼ��ʣ�Ĭ��ֵΪ 20
withWeight �� Ϊ�Ƿ�һ�����عؼ���Ȩ��ֵ��Ĭ��ֵΪ False
allowPOS �� ������ָ�����ԵĴʣ�Ĭ��ֵΪ�գ�����ɸѡ
# ����TF-IDF�㷨�Ĺؼ��ʳ�ȡ# ����TF-IDF�㷨�Ĺؼ��ʳ�ȡimport jieba
import jieba.analysesentence = 'ȫ���۰��о���᳤�����ڻ��Ϸ���ָ����ѧϰϵ����Ҫ����Ҫ��������ϯ������ۻع������ƻ�����������������������ǹ�ȥ20���ر����й�ʮ�˴�����һ�����������ʵ��ȡ�óɹ��ĸ������顣���ȣ�Ҫ�ں�ʵ ��۵����ƻ�����������۵�����������������ֻ������ȷ����һ�����Ƶ����������ܱ�֤һ������ʵ�������� �������Ρ���Σ�Ҫ�����ƻ�����ʵʩ���ƶȺͻ������ù�������ֱ����ʹ��Ȩ���������߶�����Ȩ�Ľ�������������� �ɻ�ȱ����������'
keywords = jieba.analyse.extract_tags(sentence, topK=20, withWeight=True, allowPOS=('n','nr','ns'))# print(type(keywords))
# <class 'list'>for item in keywords:print(item[0],item[1])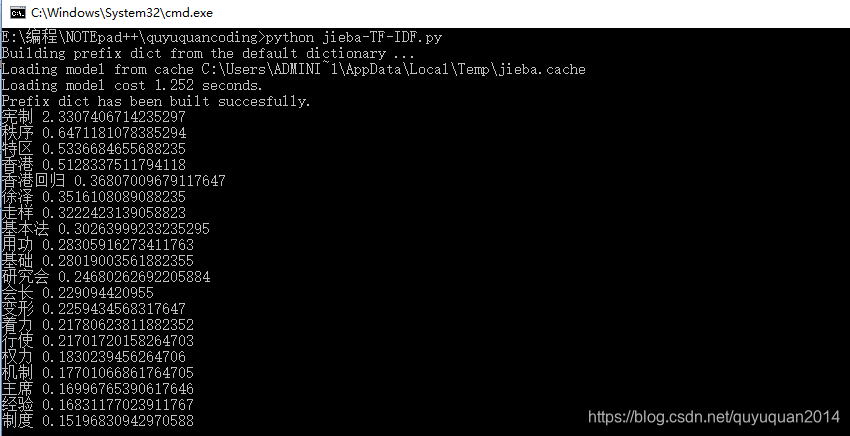
���� TextRank �㷨�Ĺؼ��ʳ�ȡ
ieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(��ns��, ��n��, ��vn��, ��v��)) ֱ��ʹ�ã��ӿ���ͬ��ע��Ĭ�Ϲ��˴��ԡ�
jieba.analyse.TextRank() �½��Զ��� TextRank ʵ��
����˼�룺
������ȡ�ؼ��ʵ��ı����зִ�
�Թ̶����ڴ�С(Ĭ��Ϊ5��ͨ��span���Ե���)����֮��Ĺ��ֹ�ϵ������ͼ
����ͼ�нڵ��PageRank��ע���������Ȩͼ
import jieba
import jieba.analysesentence = 'ȫ���۰��о���᳤�����ڻ��Ϸ���ָ����ѧϰϵ����Ҫ����Ҫ��������ϯ������ۻع������ƻ�����������������������ǹ�ȥ20���ر����й�ʮ�˴�����һ�����������ʵ��ȡ�óɹ��ĸ������顣���ȣ�Ҫ�ں�ʵ ��۵����ƻ�����������۵�����������������ֻ������ȷ����һ�����Ƶ����������ܱ�֤һ������ʵ�������� �������Ρ���Σ�Ҫ�����ƻ�����ʵʩ���ƶȺͻ������ù�������ֱ����ʹ��Ȩ���������߶�����Ȩ�Ľ�������������� �ɻ�ȱ����������'# ����TextRank�㷨�Ĺؼ��ʳ�ȡkeywords = jieba.analyse.extract_tags(sentence, topK=20, withWeight=True, allowPOS=('n','nr','ns'))# type(keywords)
# <class 'list'>for item in keywords:print(item[0],item[1])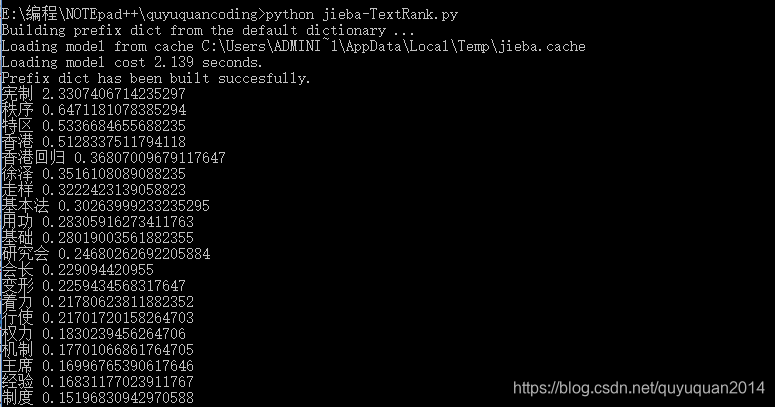
Tokenize
���ش�����ԭ�ĵ���ֹλ��
�˹����������ֻ���� unicode
Ĭ��ģʽ
����ģʽ
#encoding=utf-8
from __future__ import unicode_literals #��ģ������ʽ���ֵ������ַ���תΪunicode����
import jieba
result = jieba.tokenize('�˴�Ю������һ���ֵ�����') #Ĭ��ģʽ���зִʣ�Tokenize: ���ش�����ԭ�ĵ���ֹλ��
print("Ĭ��ģʽΪ��")
for tk in result:print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))result = jieba.tokenize(u'�˴�Ю������һ���ֵ�����', mode='search')
print("����ģʽΪ��")
for tk1 in result:print("word %s\t\t start: %d \t\t end:%d" % (tk1[0],tk1[1],tk1[2]))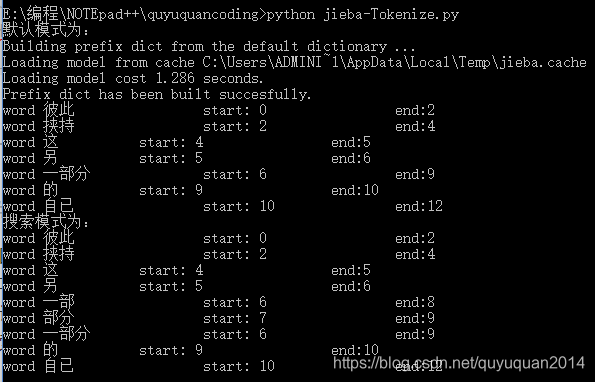
�ԡ����μǡ����зִʴ�������δ��������⣩
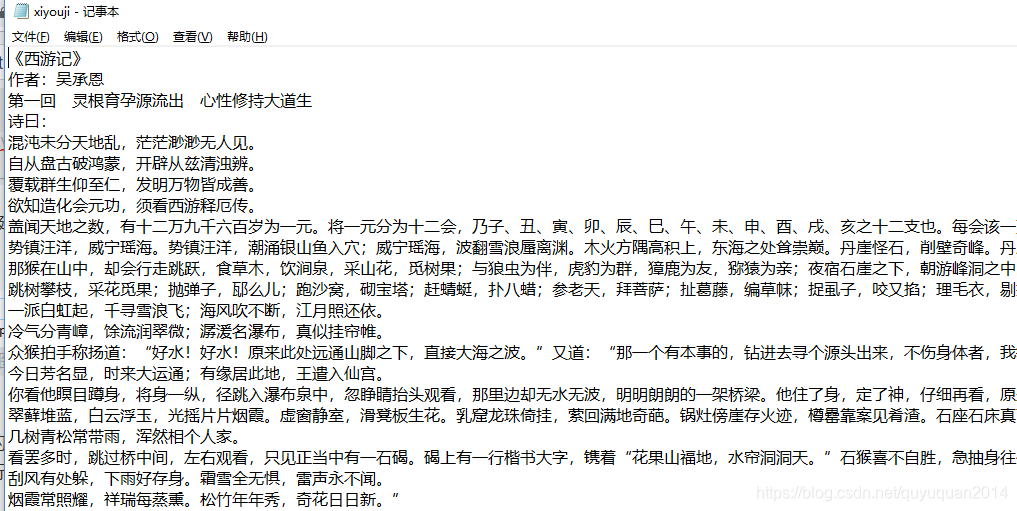
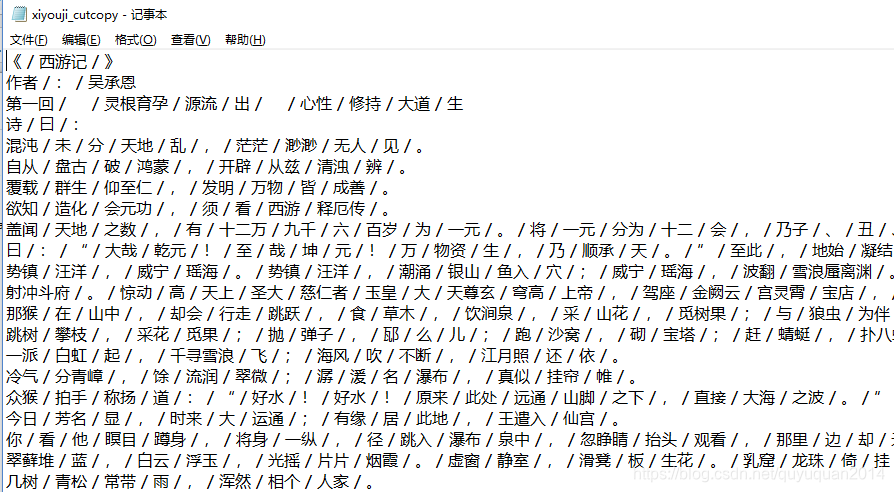
python -m jieba xiyouji.txt >xiyouji_cutcopy.txt
��������������ж������μǵķִ� ���������е����
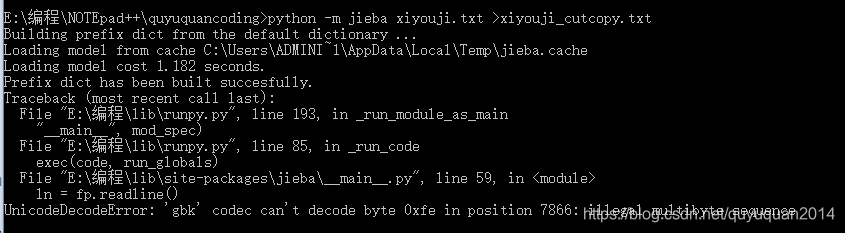
������ʾ ���� copy�ɹ��������ڷִʵ�0xfe֮�� �������зִ�

�������ı��Ĵ�С���ǿ��Կ��� ��cutcopy ��δ������е����������е�һС���ֽ����˷ִʡ�