 shuffle����
shuffle����
һ��spark��RDD��һ��̶��ķ�����ɣ�ÿ��������һϵ�еļ�¼��ɡ�������խ�����任������map��filter�����ص�RDD����������RDD�ķ�����Ϣ����pipeline����ʽ���㡣ÿ������������ڸ�RDD�еĵ�����������coalesce֮��IJ������ܵ�����������������������ת����Ȼ����Ϊ��խ�����ģ���Ϊһ����RDD�ķ���ֻ�ᱻһ����RDD�����̳С�
Spark��֧�ֿ�������ת��������groupByKey��reduceByKey������Щ�������У����㵥�������еļ�¼��������ݿ��������ڸ����ݼ�����������С�Ҫִ����Щת����������ͬkey������Ԫ���������λ��ͬһ�����У���ͬһ��������Ϊ��������һҪ��Spark����һ��shuffle�����ڼ�Ⱥ�ڲ��������ݣ�������һ������һ���·�������stage��
���Կ�����Ĵ���Ƭ�Σ�
sc.textFile("someFile.txt").map(mapFunc).flatMap(flatMapFunc).filter(filterFunc).count()����Ĵ���Ƭ��ֻ��һ��action������count��������textfile��action����������ת����������δ���ֻ����һ��stage�����У���Ϊ������ת������û��shuffle��Ҳ��������ת��������ÿ����������ֻ���������ĸ�RDD�ĵ���������
���ǣ�����ĵ���ͳ�ƾ������кܴ�����
val tokenized = sc.textFile(args(0)).flatMap(_.split(' '))
val wordCounts = tokenized.map((_, 1)).reduceByKey(_ + _)
val filtered = wordCounts.filter(_._2 >= 1000)
val charCounts = filtered.flatMap(_._1.toCharArray).map((_, 1)).reduceByKey(_ + _)
charCounts.collect()������������reducebykey����������stage��
����ͼ�����ӣ���Ϊ��һ��join������
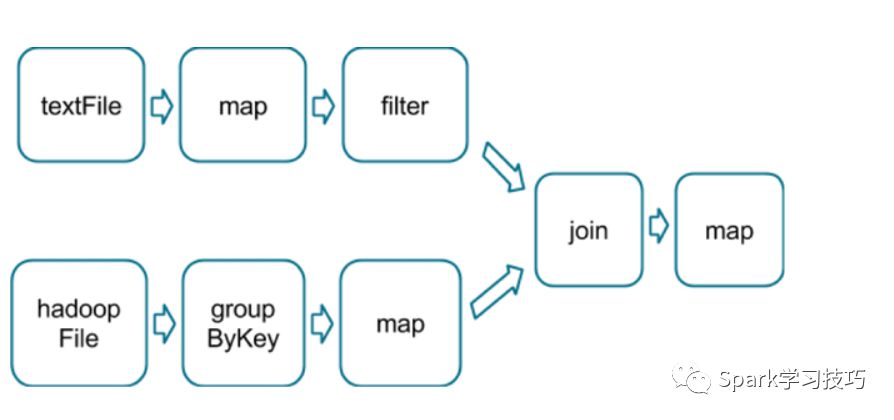
�ۿ�Ȧס�ľ�������DAG��stage���֡�
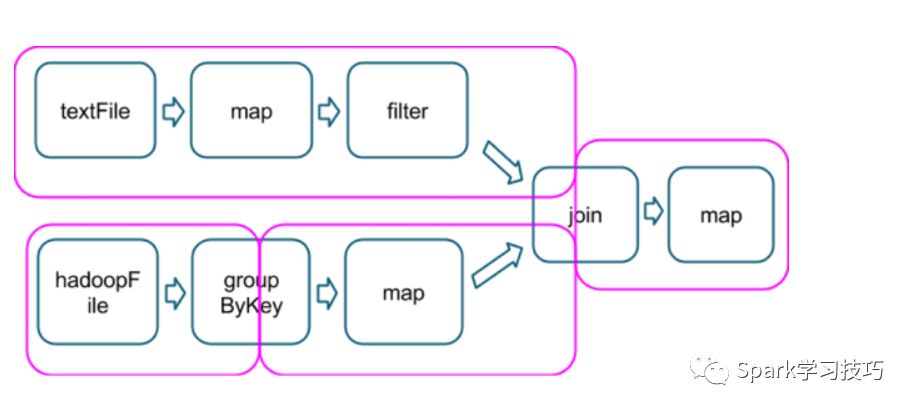
��ÿ��stage�ı߽磬��stage��task�Ὣ����д����̣���stage��task�Ὣ����ͨ�������ȡ���������ǻᵼ�ºܸߵĴ��̺�����IO������shuffle�����൱�ߣ�Ӧ�þ������⡣��stage�����ݷ�����������stage�ķ�������ͬ������shuffle�IJ���������������ָ���������ģ�Ҳ����numPartitions�����¸�stage���ж��ٸ�����������mr������reducer�������Ƿdz���Ҫ��һ������һ����shuffle��ʱ��ָ��������Ҳ���ںܴ�̶��Ͼ���һ��Ӧ�ó�������ܡ�
�Ż�shuffle
ͨ���������ѡ��ʹ�ò�����ͬ�����action��transform��滻�����Dz����Dz�����ͬ��������Ӿͻ�����ͬ�����ܡ�ͨ�����ⳣ�������岢ѡ����ȷ�����ӿ����������Ӧ�ó�������ܡ�
��ѡ��ת��������ʱ��Ӧ��С��shuffle������shuffle����������shuffle�Ƿdz��������ܵIJ��������е�shuffle���ݶ��ᱻд����̣�Ȼ��ͨ�����紫�䡣repartition , join, cogroup, �� *By ���� *ByKey ���͵IJ����������shuffle�����ǿ��Զ�һ�¼����������ӽ����Ż���
1. groupByKeyijЩ����¿��Ա�reducebykey���档
2. reduceByKeyijЩ����¿��Ա� aggregatebykey���档
3. flatMap-join-groupByijЩ����¿��Ա�cgroup���档
����ϸ�ڣ�֪ʶ�������ѿ��Ե���Ķ�ԭ������֪ʶ�����Ķ���
no shuffle
��ijЩ����£�ǰ��������ת���������ᵼ��shuffle������ǰ��ת�������Ѿ�ʹ���˺�shuffle��ͬ�ķ������������ݵ�ʱ��spark�Ͳ������shuffle��
�ٸ����ӣ�
rdd1 = someRdd.reduceByKey(...)
rdd2 = someOtherRdd.reduceByKey(...)
rdd3 = rdd1.join(rdd2)����ʹ��redcuebykey��ʱ��û��ָ�������������Զ���ʹ�õ�Ĭ�Ϸ��������ᵼ��rdd1��rdd2�����õ���hash������������reducebykey�������������shuffle���̡���������ݼ�����ͬ�ķ�������ִ��join������ʱ��Ͳ���Ҫ���ж����shuffle���������ݼ��ķ�����ͬ�����rdd1���κε��������е�key����ֻ�ܳ�����rdd2�ĵ��������С� ��ˣ�rdd3���κε���������������ݽ�ȡ����rdd1�е������������ݺ�rdd2�еĵ������������Ҳ���Ҫ������shuffle��
���磬���someRdd���ĸ�������someOtherRdd��������������reduceByKeys��ʹ���������������е�����������ʾ��
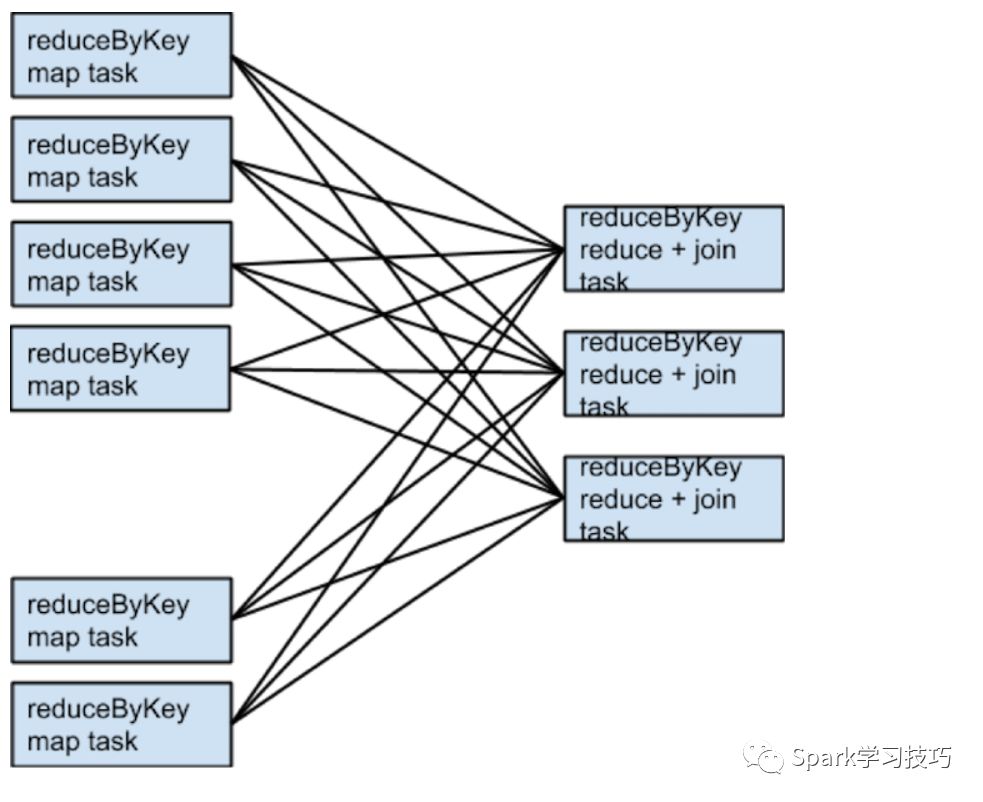
���rdd1��rdd2ʹ�ò�ͬ�ķ�����������ͬ�ķ�������ͬ�ķ�����������һ�����ݼ���join�Ĺ�������Ҫ����shuffle
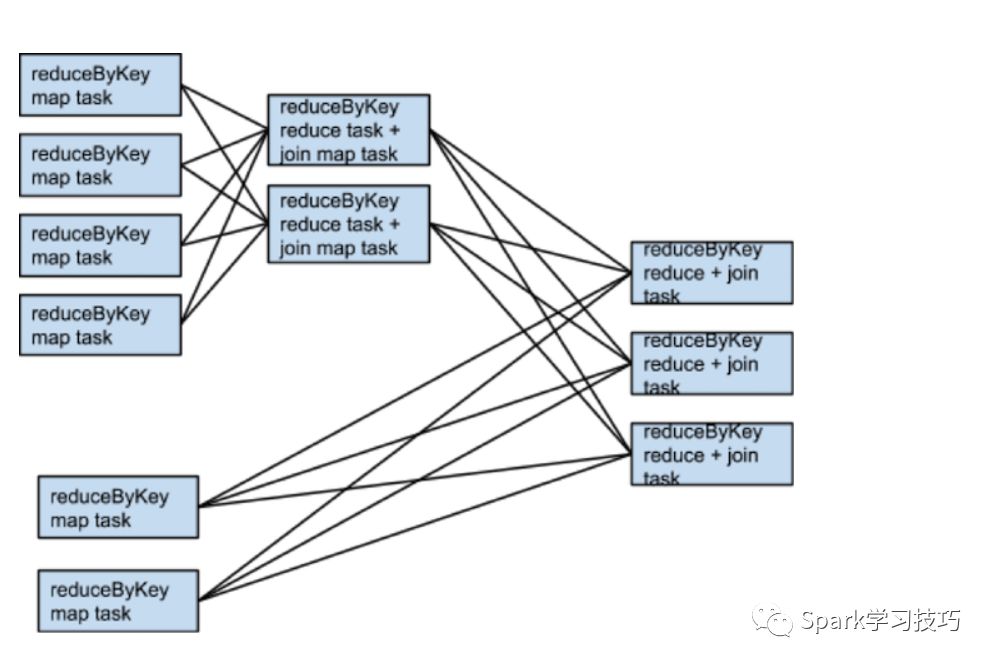
��join�Ĺ�����Ϊ�˱���shuffle������ʹ�ù㲥��������executor�ڴ���Դ洢���ݼ�����driver�˿��Խ�����ص�һ��hash���У�Ȼ��㲥��executor��Ȼ��mapת���������ù�ϣ����ִ�в��ҡ�
����shuffle
��ʱ����Ҫ������С��shuffle�����Ĺ���
�����Ӳ��жȵ�ʱ�����shuffle�������ġ����磬��������һЩ�ļ��Dz��ɷָ�ģ���ô�ô��ļ���Ӧ�ķ����ͻ��д����ļ�¼��������˵�����ݷ�ɢ�������ܶ�ķ����ڲ���ʹ�������Ѿ�����cpu������������£�ʹ��reparition���²�������ķ����������������ת����������IJ��жȣ���������ܴ����ܡ�
ʹ��reduce��aggregate���������ݾۺϵ�driver�ˣ�Ҳ���������ĺܺõ����ӡ�
�ڶԴ�������ִ�оۺϵ�ʱ����driver�ĵ��߳��оۺϻ��Ϊƿ����Ҫ��driver�ĸ��أ���������ʹ��reducebykey����aggregatebykeyִ��һ�ֲַ�ʽ�ۺϣ�ͬʱ��������ݼ����������١�ʵ��˼·��������ÿ�������ڲ����г����ۺϣ�ͬʱ���ٷ�������Ȼ���ٽ��ۺϵĽ������driver��ʵ�����վۺϡ����͵IJ�����treeReduce �� treeAggregate��
���ۺ��Ѿ�����key���з���ʱ���˷����ر����á����磬����һ������������Ͽ���ÿ�����ʳ��ֵĴ������������ʹ��map���ص�driver��һ�ַ����ǿ���ʹ�þۺϲ��������ÿ����������ֲ�map��Ȼ����driver�кϲ�map��������aggregateByKey����ȫ�ֲ��ķ�ʽ����ͳ�ƣ�Ȼ�����collectAsMap��������ص�driver��
����spark���ɣ������ݼ��ɣ���ӭ����Ķ�ԭ������֪ʶ������
�Ƽ��Ķ���
����|�������Spark��Դ
���� | hive on spark ���ŵ�
