2019 Interspeech
-
- 1. Improved End-to-End Speech Emotion Recognition Using Self Attention Mechanism and Multitask Learning
-
- ʵ��
- 2. Self-attention for Speech Emotion Recognition
-
- ʵ��
- 3. Deep Learning of Segment-Level Feature Representation with Multiple Instance Learning for Utterance-Level Speech Emotion Recognition
-
- Abstract
-
- 1. Introduction
- ʵ��
1. Improved End-to-End Speech Emotion Recognition Using Self Attention Mechanism and Multitask Learning
- ������ѧ
- �˵��˶�����ѧϰwith self attention������������gender��
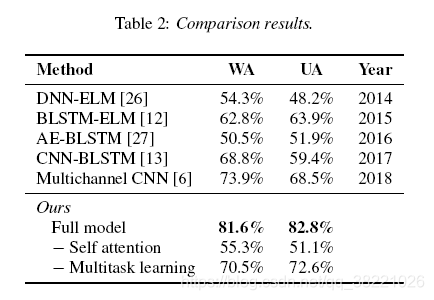
���ȴ�����ͼ��ȡ����speech spectrogram�����������ֹ�������Ȼ��CNN-BLSTM E2E���硣�����self attention mechanism�۽������ salient periods������ǵ�emotion and gender classification tasks֮����������������Ա������Ϊ����task������Ҫ����emotion classification share���õ���Ϣ�� - ժҪ���˻�����Ӧ��˵��SER has attracted great attention�����л���С����ܣ��ֱ�����������������ͼ����Խ�� ��HMM GMM SVM��traditional machine learning approaches, CNN RNN traditional machine learning approaches��
- multi-headed self attention
- ��ȡ����ͼ�����ȹ�һ����7.5s������IJ��㣬����cut��Hanning windows 800��sampling rate 16000Hz.
��ʱ����Ҷ�任 - ��\alpha������\beta�� ��1
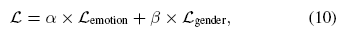
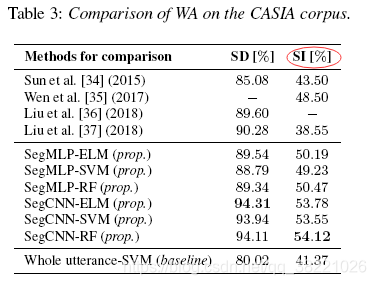
ʵ��
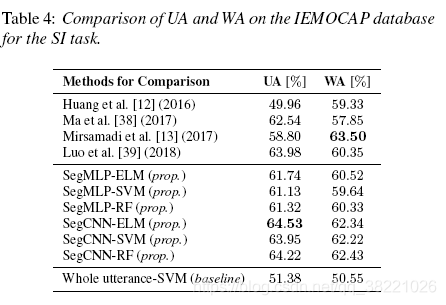
IEMOCAP combine EXCITED and HAPPY into HAPPY ���� һ��5531samples��
ʵ�����Ա���5-fold cross-validation��2018����Ҳ��leave-one-session-out��
2. Self-attention for Speech Emotion Recognition
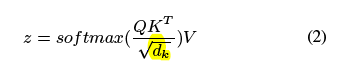
- ��Attention is all you need��2017 Available
based on an encoder-decoder structure that û��ʹ���κ� recurrence, but instead uses weighted
correlations between the elements of the input sequence
Transformer����input sequenceӳ���a query, a key and a value
�����˸���attention�� - ����� a global windowing system that works works on top of the local windows.
- classification and regression.
ʵ��
5 fold cross validation.
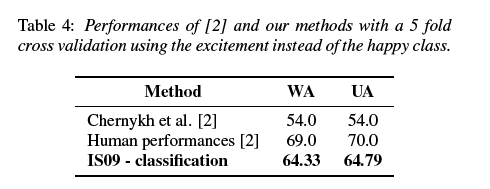
��Ϊhappy�٣�������excited������balance����֪�����ϸ�ȽϵĶԲ��ԣ�[2]Ҳ��excited 5����
3. Deep Learning of Segment-Level Feature Representation with Multiple Instance Learning for Utterance-Level Speech Emotion Recognition
Deep Learning of Segment-Level Feature Representation with Multiple Instance Learning for Utterance-Level Speech Emotion Recognition
������Ĵ�ѧ Shuiyang Mao
Abstract
�����ʾ��ѧϰ�����ѧϰSER��
�ȸ�ÿ��segment�������״̬��Utterance-Level ��������Segment-Level���ߵ�aggregation��������ͬ��DNN��SegMLP������֪����ȡ�ֹ������ĸ�γ������ and SegCNN����log Mel filterbanks���Զ���ȡ������fea���������� CASIA�� IEMOCAP��
���֣���������ṩ�� richer information��automatic feature learning�����ֹ������������state-of- the-art methods�������
1. Introduction
ʶ��model���·ֳ����ࣺ
dynamic modeling approach where frame-based low-level descriptors (LLDs) ����MFCCs ��Ȼ������HMM��
�������� statistics of the fundamental frequency (pitch), spectral envelop and energy contour����Щͳ�ƺ�����������suprasegment �������Σ����� whole utterance, ��˱�����global features��Ȼ������ȫ��model SVM KNN�ȡ�
��Щ��ͳ������ȱ�㣺���ڴ��ڷ����ԣ�����ƣ���mainfold��˵statistically inefficient��
- Segment-Level
���ȸ�ÿһ��segment���࣬utterance-level �ķ�������segment-level�� aggregation
of the segment-level decisions
������(1) the aggregation of segment-level decisions provides richer information than the statistics over the low-level descriptors (LLDs) across the whole utterance;
(2)automatic feature learning outperforms manual features
����SegMLP��������IS09(manually designed perceptual features)��SegCNN�������� log Mel filterbanks.�ٷֱ��ELM SVM RF һ��6��ʵ��
automatic feature learning outperforms manually designed perceptual features
aggregation�ķ�������f matrix���뵽���ַ�������
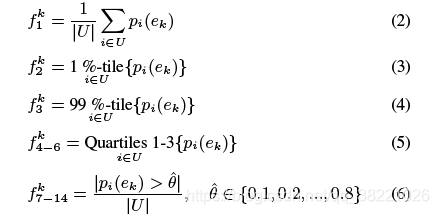
- multiple instance learning (MIL)
ʵ��
������ CASIA IEMOCAP