初识 Nebula
文章目录
- 初识 Nebula
-
- 前置知识
-
- 什么是 Nebula
- 什么是图数据库
- Nebula 的优点
- Nebula 的使用场景
- Nebula 的安装
-
- 二进制压缩包安装
- 使用 nGql 操作 Nebula
-
- 图空间的操作
- 顶点与边的定义
- 插入顶点和边
- 删除顶点和边
- 查询操作
-
- match 语句(openCypehr 支持)
- lookup 语句
- go 语句(依据路劲查询属性)
- fetch 语句(获取指定边或者点的属性值)
- 图与路劲的查询
-
- get subgraph 语句
- find path 子句
前置知识
什么是 Nebula
Nebula Graph 是一个高性能、可线性扩展、开源的分布式图数据库。Nebula Graph 采用 shared-nothing 分布式架构,企业可针对性对业务进行扩缩容。
什么是图数据库
图数据库是专门存储庞大的图形网络并从中检索信息的数据库。它可以将图中的数据高效存储为点(Vertex)和边(Edge),还可以将属性(Property)附加到点和边上。
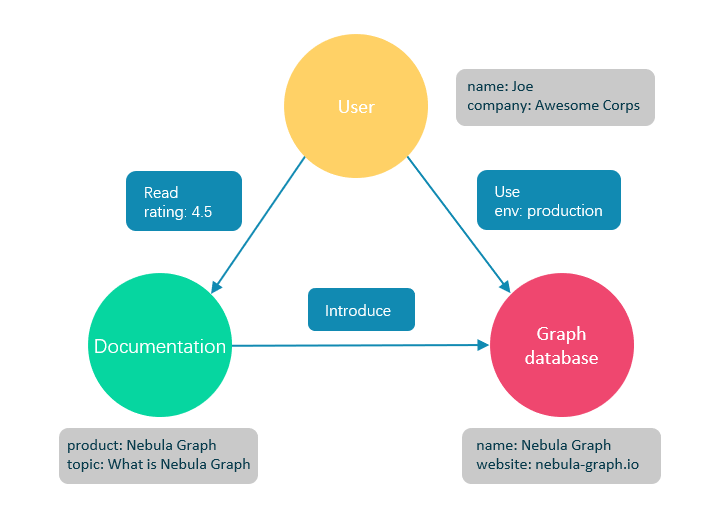
图数据库适合存储大多数从现实抽象出的数据类型。世界上几乎所有领域的事物都有内在联系,像关系型数据库这样的建模系统会提取实体之间的关系,并将关系单独存储到表和列中,而实体的类型和属性存储在其他列甚至其他表中,这使得数据管理费时费力。
Nebula Graph作为一个典型的图数据库,可以将丰富的关系通过边及其类型和属性自然地呈现。
Nebula 的优点
开源
Nebula Graph是在Apache 2.0条款下开发的。越来越多的人,如数据库开发人员、数据科学家、安全专家、算法工程师,都参与到Nebula Graph的设计和开发中来,欢迎访问Nebula Graph GitHub主页参与开源项目。
高性能
基于图数据库的特性使用C++编写的Nebula Graph,可以提供毫秒级查询。众多数据库中,Nebula Graph在图数据服务领域展现了卓越的性能,数据规模越大,Nebula Graph优势就越大。详情请参见Nebula Graph benchmarking页面。
易扩展
Nebula Graph采用shared-nothing架构,支持在不停止数据库服务的情况下扩缩容。
易开发
Nebula Graph提供Java、Python、C++和Go等流行编程语言的客户端,更多客户端仍在开发中。详情请参见Nebula Graph clients。
高可靠访问控制
Nebula Graph支持严格的角色访问控制和LDAP(Lightweight Directory Access Protocol)等外部认证服务,能够有效提高数据安全性。详情请参见验证和授权。
生态多样化
Nebula Graph开放了越来越多的原生工具,例如Nebula Graph Studio、Nebula Console、Nebula Exchange等,更多工具可以查看 生态工具概览。此外,Nebula Graph还具备与Spark、Flink、HBase等产品整合的能力,在这个充满挑战与机遇的时代,大大增强了自身的竞争力。
兼容openCypher查询语言
Nebula Graph 查询语言,简称为 nGQL,是一种声明性的、部分兼容 openCypher 的文本查询语言,易于理解和使用。详细语法请参见nGQL指南。
面向未来硬件,读写平衡
闪存型设备有着极高的性能,并且价格快速下降, Nebula Graph 是一个面向 SSD 设计的产品,相比于基于HDD + 大内存的产品,更适合面向未来的硬件趋势,也更容易做到读写平衡。
灵活数据建模
用户可以轻松地在Nebula Graph中建立数据模型,不必将数据强制转换为关系表。而且可以自由增加、更新和删除属性。详情请参见数据模型。
Nebula 的使用场景
Nebula Graph可用于各种基于图的业务场景。为节约转换各类数据到关系型数据库的时间,以及避免复杂查询,建议使用Nebula Graph。
欺诈检测
金融机构必须仔细研究大量的交易信息,才能检测出潜在的金融欺诈行为,并了解某个欺诈行为和设备的内在关联。这种场景可以通过图来建模,然后借助Nebula Graph,可以很容易地检测出诈骗团伙或其他复杂诈骗行为。
实时推荐
Nebula Graph能够及时处理访问者产生的实时信息,并且精准推送文章、视频、产品和服务。
知识图谱
自然语言可以转化为知识图谱,存储在Nebula Graph中。用自然语言组织的问题可以通过智能问答系统中的语义解析器进行解析并重新组织,然后从知识图谱中检索出问题的可能答案,提供给提问人。
社交网络
人际关系信息是典型的图数据,Nebula Graph可以轻松处理数十亿人和数万亿人际关系的社交网络信息,并在海量并发的情况下,提供快速的好友推荐和工作岗位查询。
Nebula 的安装
二进制压缩包安装
Nebula 的下载网址 https://nebula-graph.com.cn/download/
# 首先进入到需要安装的目录并将压缩包上传至该目录下(我这里默认是 /usr/local 目录下)
cd /usr/local
# 解压 Nebula 压缩包
tar -zxf nebula-graph-2.6.1.el7.x86_64.tar.gz
# 进入该压缩包目录下
cd nebula-graph-2.6.1.el7.x86_64/
# 进入 etc 目录
cd etc/
# 重命名文件
mv nebula-graphd.conf.default nebula-graphd.conf
mv nebula-metad.conf.default nebula-metad.conf
mv nebula-storaged.conf.default nebula-storaged.conf
# 返回上级目录
cd ../
# 在 neubla 安装目录下启动 Neubla 服务
scripts/nebula.service start all
# 本地查看 Neubla 状态
curl -G "http://localhost:19559/stats"
# 关闭 neubla 服务
scripts/nebula.service stop all
然后需要安装 Neubla Console 控制台连接 Neubla
Neubla Console 的下载地址 https://github.com/vesoft-inc/nebula-console/releases
# 将下载的 Nebula Colsole 文件上传至 Nebula 的目录下,并且重命名该文件
mv nebula-console-linux-amd64-v2.6.0 nebula-console
# 为 nubula 添加权限
chmod 111 nebula-console
# 使用 nebula-console 连接
./nebula-console -addr 127.0.0.1 -port 9669 -u root -p 123456
# 使用 :exit 或 :quit 命令退出 console 窗口
# 同时也可以使用 nebula 执行脚本文件
./nebula-console -addr 127.0.0.1 -port 9669 -u root -p 123456 -f basketballplayer-2.X.ngql
然后安装 Nebula Graph Studio 可视化界面
Nebula Graph Studio 的下载地址为 https://oss-cdn.nebula-graph.com.cn/nebula-graph-studio/3.1.0/nebula-graph-studio-3.1.0.x86_64.tar.gz
Node.js 的下载地址为 https://nodejs.org/en/download/
# 首先进入安装 Nebula Graph Studio 的位置 (这里我默认为 /usr/local 目录),并且将 Nebula Graph Studio 压缩包目录上传至 目录
cd /usr/local
# 解压 Nebula Graph Studio 压缩包
tar -zxf nebula-graph-studio-3.1.0.x86_64.tar.gz
# 进入 Nebula 解压后的目录
cd nebula-graph-studio/
# 先启动 nebula-http-gateway
nohup nebula-http-gateway/nebula-httpd &
# 安装 losfyum install lsof# ================安装 Node.js===============# 进入 Node.js 的安装目录,并上传 Node.js 的压缩包cd /usr/local# 解压 Node.js 的压缩包tar -xf node-v16.13.0-linux-x64.tar.xz
# 添加环境变量
export PATH=$PATH:/usr/local/node-v16.13.0-linux-x64/bin
# 使环境变量生效
source /etc/profile
# 查看 node 是否安装成功
node -v
# =========================================
# 进入 Nebula Graph Studio 的安装目录
cd /usr/local/nebula-graph-studio/nebula-graph-studio/
# 启动 Nebula Graph Studio
npm run start
使用 nGql 操作 Nebula
图空间的操作
# 定义图数据库,并且设置 顶点的 id 长为 12
CREATE SPACE IF NOT EXISTS demospace (vid_type=fixed_string(32))
# 查看图空间
SHOW SPACES
# 查看图空间的详细信息
describe space kgdata
# 使用图空间
USER SPACES
顶点与边的定义
# 定义顶点
create tag tag_name (name string,key string,age int);
# 定义边
create edge edge_name (name string,key string,ooid string);
# 建立索引,便于按照属性进行查询
create tag index tag_name_index_name on tag_name(name(144),age,key(32));
# 查看已经建立的有关于边的索引
show tag indexes;
# 建立边的索引
create edge index if not exists edge_name_index_name on edge_name(name(144),key(32),ooid(32));
# 展示已经建立的有关于边的索引
show edge indexes;
# 重建边的索引
rebuild edge index edge_name_index_name;
# 显示已经定义的顶点类型
show tags
# 显示顶点类型的定义信息
desc tag tag_name
# 修改顶点类型的定义(添加属性)
alter tag tag_name add (color fixed_string(7) );
# 修改顶点类型的定义(修改属性的数据类型)alter tag tag_name change (color fixed_string(9));
# 修改顶点类型定义(删除属性)
alter tag tag_name drop (color)
# 删除顶点类型
drop tag if exists tag_name
# 显示所有已经定义的边类型
show edges
# 查看边的定义信息
desc edge edge_name
# 其余与边相关的操作均与对于顶点的操作类似
Ps:
- 对于不定长的 String 类型建立索引时需要指定对前多少个字创建索引
- 使用复合索引时遵循最左匹配原则
- 复合索引不支持跨 edge 和 tag 的索引
Neubla 的数据类型
| 类型 | 声明关键字 | 说明 |
|---|---|---|
| 整数 | INT,INT64,INT32,INT16,INT8 |
64 位整数(INT64)、32 位整数(INT32)、16 位整数(INT16)和 8 位整数(INT8)。 |
| 浮点数 | FLOAT,DOUBLE |
单精度浮点(FLOAT)和双精度浮点(DOUBLE) |
| 布尔 | BOOL |
可选值为true或false |
| 字符串 | STRING,FIXED_STRING |
使用关键字STRING声明变长字符串。使用关键字FIXED_STRING(<length>)声明定长字符串,<length>为字符串长度,例如FIXED_STRING(32) |
| 日期时间类型 | DATE,TIME,DATETIME,TIMESTAMP |
DATE包含日期,但是不包含时间。TIME包含时间,但是不包含日期。DATETIME包含日期和时间。TIMESTAMP包含日期和时间。支持的范围是 UTC 时间的1970-01-01T00:00:01到2262-04-11T23:47:16。 |
插入顶点和边
# 插入顶点
insert vertex if not exists tag_name(name,key,age) \
values "vertex_id":("vertex_name_1","vertex_key_1",16);
# 插入多个顶点
insert vertex if not exists tag_name(name,key,age) values \
"vertex_src_id":("vertex_src_name","vertex_src_key",15), \
"vertex_tar_id":("vertex_tar_name","vertex_tar_key",19);
# 插入边
insert edge if not exists edge_name(name,key) values \
"vertex_src_id"->"vertex_tar_id"@3:("edge_name_1","edge_key_1");
Ps:
- 使用
if not exists仅检查 vid 和 tag 名称有没有重复,且会影响插入性能@后面是 rank 值,默认为 0
删除顶点和边
# 删除顶点
delete vertex vertex_id
# 删除边
delete edge edge_name "vertex_src_id" -> "vertex_tar_id" @1
查询操作
match 语句(openCypehr 支持)
# 查询所有标签为 tag_name 的顶点
match (m:tag_name) return m;
# 查询 vid 为 "vertex_id" 的顶点
match (m:tag_name) where id(m) == "vertex_id" return m;
# 依据属性查询顶点match (m:tag_name{name:"vertex_src_name"}) return m;# 匹配查询路径(双向 "--";单向 "-->" 或 "<--")match p=(m:tag_name)--(n:tag_name) return p# 也可写作(与 cypher 语法类似)match (m:tag_name)-[p]->(n:tag_name) return p
lookup 语句
# 查询所有带标签为 tag_name 的顶点的 vid 和属性
lookup on tag_name yield id(vertex) as vertex_id,properties(vertex);
# 按照属性查询顶点
lookup on tag_name where tag_name.name=="vertex_src_name" yield properties(vertex);
# 依据属性查询边
lookup on edge_name where edge_name.name=="
edge_name_1" yield properties(edge).key as key;
# 查询属性为某几个值
lookup on player where player.age in [45,40,35] yield properties(vertex).name as name,properties(vertex).age as age;
# 设置输出的个数(从第一位开始输出,输出两条记录)
lookup on player where player.age in [45,40,35] yield properties(vertex).name as name,properties(vertex).age as age | limit 0,2;
# 查询并按属性排序
lookup on player where player.age >= 30 yield properties(vertex).name as name,properties(vertex).age as age | order by $-.age desc;
# 使用 group 语句对结果进行分组
lookup on player yield properties(vertex).name as name,properties(vertex).age as age | group by $-.age yield $-.age,count($-.age) as res_num | order by $-.res_num desc | limit 3,7
查询时比较符号参照表
| 数据类型 | 符号 | 描述 |
|---|---|---|
| 字符串 | ==,<> ,!= |
“==”号代表两个字符串相等,“<>” 与“!=”代表不等于 |
| 整数,浮点数 | ==,<,<=,>.>= |
如平常代码中的运算符 |
| 时间 | ==,<,<=,>.>= |
如平常代码中的运算符 |
| 顶点与边的属性 | IS NULL, IS NOT NULL, IS EMPTY, IS NOT EMPTY |
用于判断属性是否为空,或者是否存在 |
go 语句(依据路劲查询属性)
# 从 vid 为 player102 的点出发,并且通过边 server 相连的顶点,并依次输出边的属性,起点 vid,终点 vid,起点属性,终点属性
GO FROM "player102" OVER serve yield properties(edge) as edge_prop ,src(edge) as start_vertex_id ,dst(edge) as end_vertex_id,properties($^) as start_vertex_prop,properties($$) as end_vertex_prop;
# 以 player101 为出发点,经过任意类型的边,且经过 1 - 2 跳,并输出所有边的标签,起点 vid,终点vid
go 1 to 2 steps from "player101" over *
yield type(edge)as edge_type,src(edge) as start_vertex_id ,dst(edge) as end_vertex_id;
# 由 player100 顶点出发,经过标签为 follow 的边,共两步,并输出边的起点和边的终点,以及终点边的 age 属性。然后将结果按照边的目的顶点进行分组。最后输出边的终点,起点和 age.
GO 2 STEPS FROM "player100" OVER follow
YIELD src(edge) AS src, dst(edge) AS dst, properties($$).age AS age
| GROUP BY $-.dst
YIELD $-.dst AS dst, collect_set($-.src) AS src, collect($-.age) AS age;
fetch 语句(获取指定边或者点的属性值)
# 获取点 player100 的所有属性
FETCH PROP ON player "player100";
# 获取 player100 的 name 属性
FETCH PROP ON player "player100" YIELD properties(vertex).name AS name;
# 获取顶点标签不同,但是顶点 id 相同的两个顶点的属性,并且将结果合并输出
FETCH PROP ON player, t1 "player100";
# 获取任意标签下,id 为 player100, player106, team200 的属性。
FETCH PROP ON * "player100", "player106", "team200";
# 获取连接 player100 和 team204 的边 serve 的所有属性值。
FETCH PROP ON serve "player100" -> "team204";
# 获取多条边的属性值
FETCH PROP ON serve "player100" -> "team204", "player133" -> "team202";
# 使用 rank 查询(默认会返回 rank 为 0 的边)
FETCH PROP ON serve "player100" -> "team204" @1;
图与路劲的查询
get subgraph 语句
# 查询从点player101开始、0~1 跳、所有边类型的子图。
GET SUBGRAPH 1 STEPS FROM "player101" YIELD VERTICES AS nodes, EDGES AS relationships;
# 查询从点player101开始、0~1 跳、follow类型的入边的子图。
GET SUBGRAPH 1 STEPS FROM "player101" IN follow YIELD VERTICES AS nodes, EDGES AS relationships;
# 查询从点player101开始、0~1 跳、serve类型的出边的子图,同时展示边的属性。
GET SUBGRAPH WITH PROP 1 STEPS FROM "player101" OUT serve YIELD VERTICES AS nodes, EDGES AS relationships;
find path 子句
# 寻找从 player102 到 team204 且经过任意类型的边的最短路径(单方向)
FIND SHORTEST PATH FROM "player102" TO "team204" OVER *;
# 寻找从 team204 到 player100 且经过任意类型的边的最短路径(方向可逆)
FIND SHORTEST PATH WITH PROP FROM "team204" TO "player100" OVER * REVERSELY;
# 寻找从 player100 到 team204 且经过任意类型的边,且如果边为 follow 的话则要求其 degree 不为空,或者其 degree 属性大于零。
FIND ALL PATH FROM "player100" TO "team204" OVER * WHERE follow.degree is EMPTY or follow.degree >=0;