hello�����������ε����ķ���վ�����������������Neural Architecture Search: A Survey(������ṹ����)������һƪ��������������һ����~
ժҪ
Ŀǰ���õ���ϵ�ṹ�������ר���ֹ������ģ�����һ����ʱ�����׳����Ĺ��̡�����Ϊ��ˣ����Ƕ��Զ��ṹ��������Խ��Խ����Ȥ�������ṩ��һ�����еĹ�������һ������о��ͷ��࣬��������ά�ȣ������ռ䣬�������ԣ������ܹ��Ʋ��ԡ�
�ؼ������ṹ������AutoML��AutoDL�������ռ���ƣ��������ԣ�������������
1����
��֪���������ѧϰ�ijɹ��ܴ�̶��Ϲ鹦�������������̹��̵��Զ������ֲ�������ȡ�����Զ˵��˵ķ�ʽ��������ѧϰ�ģ��������ֶ���Ƶġ�Ȼ������һ�ɹ������ŶԹ��̵IJ�������������Խ��Խ���ӵ��ṹ���ֹ���Ƶ�**���ܹ�������NAS���Ǽܹ������Զ����Ĺ��̣��ǻ���ѧϰ�Զ�������һ����**��ĿǰΪֹ��NAS������һЩ�������Ѿ������ֶ���Ƶļܹ�������ͼ����ࣨZoph et al.��2018��Real et al.��2019����Ŀ���⣨Zoph et al.��2018��������ָChen et al.��2018����NAS����ΪAutoML��������Hutter et al.��2019�����볬�����Ż���Feurer and Hutter��2019����Ԫѧϰ��Vanschoren��2019���������ص���
���Ǹ�������ά�ȶ�NAS�������з��ࣺ�����ռ䡢�������Ժ������������ԣ�
?�����ռ䣺������ԭ���Ͽ��Ա�ʾ��Щ��ϵ�ṹ����Ϲ��ڷdz��ʺ����������ϵ�ṹ�ĵ������Ե�����֪ʶ���Լ�С�����ռ�Ĵ�С����������
?�������ԣ���ϸ˵�������̽�������ռ䣨�����ռ�ͨ����ָ�����ģ����������ģ���һ���棬ϣ�������ҵ��������õ���ϵ�ṹ����һ���棬Ӧ�������������������ϵ�ṹ����
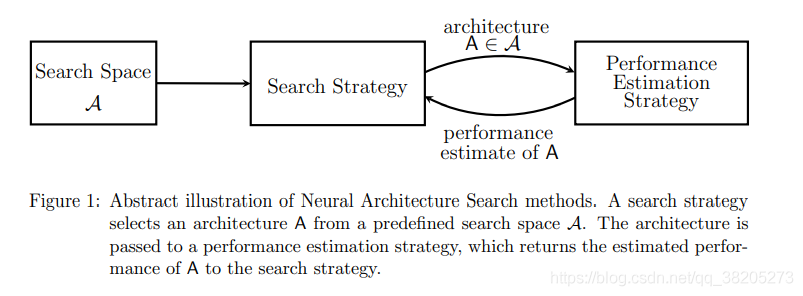
?������������������NAS��Ŀ��ͨ�����ҵ��ڿ�������������ʵ�ָ�Ԥ�����ܵ���ϵ�ṹ������������ָ�����������ܵĹ��̣����ѡ���Ƕ�����ִ�б�����ϵ�ṹ��ѵ����֤�������ҵ��ǣ����ڼ����Ϸdz������������˿����о�����ϵ�ṹ����������ˣ�����������о������ڿ���������Щ���������ɱ��ķ�����
2�����ռ�
�����ռ䶨����NAS����ԭ���Ͽ��ܷ��ֵ��ṹ����������������������г����������ռ䡣
һ����Լ������ռ�����ʽ�ṹ������Ŀռ䣬��ͼ2������ʾ��
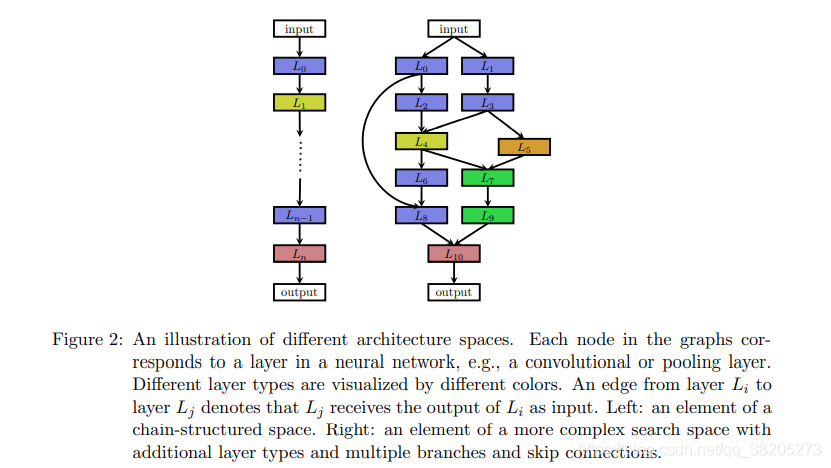
Ȼ�������ռ������Ϊ����i����ģ��������n����������ģ�����ii��ÿ��ִ�еIJ������ͣ����磬�ء�����������IJ���������ȿɷ��������Chollet��2016������չ������Yu��Koltun��2016�����Լ���iii����֮��صij��������㣬���磬��������˲����������ں˴�С�Ͳ�����Baker���ˣ�2017a��Suganuma���ˣ�2017��Cai���ˣ�2018a��������ȫ��������ĵ�Ԫ������Mendoza���ˣ�2016����ע�⣬��iii���еIJ����ԣ�ii��Ϊ��������������ռ�IJ��������ǹ̶����ȶ��������ռ䡣
����NAS�������о���Brock et al.��2017��Elsken et al.��2017��Zoph et al.��2018��Elsken et al.��2019��Real et al.��2019��Cai et al.��2018b��������ֹ��������ִ����Ԫ�أ������������ӣ������������ӵĶ��֧���磬��ͼ2���ң���ʾ������������£���i�����������ʽ������Ϊһ�������������������ǰ�IJ������ʹ������һ���������Եõ���������ɶȡ���Щ���֧�ܹ�����������ǣ�i�����ṹ���磨ͨ�����ã�����ii��ʣ�����磨He���ˣ�2016��������ǰһ�������ͣ�1���ͣ�iii��DenseNets
��Huang���ˣ�2017����������ǰ�IJ�����Ǵ�����(���ֹ����������ظ�ͼ����ɵļܹ���Szegedy et al.��2016��He et al.��2016��Huang et al.��2017�����ƶ���Zoph et al.��2018����Zhong et al.��2018a������ֱ�������Щͼ����������Ϊϸ����飬������������ϵ�ṹ��
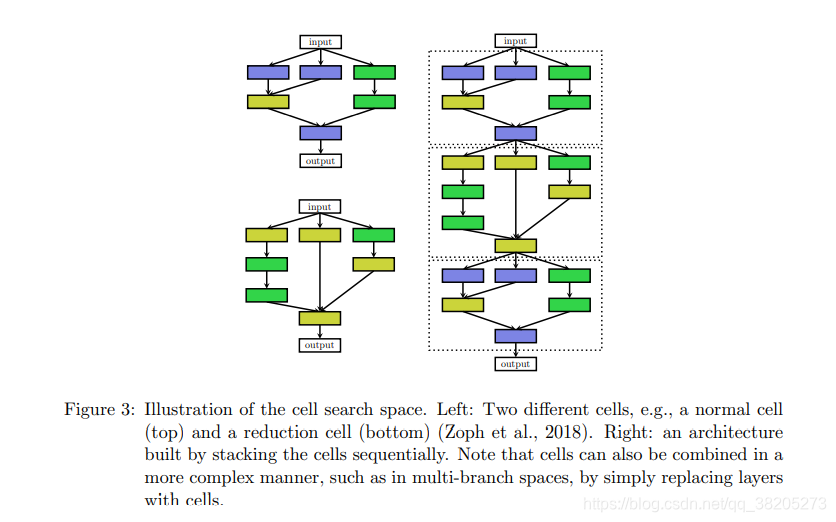
�Ż������ֲ�ͬ���͵ĵ�Ԫ��һ���DZ�������ά�ȵ�������Ԫ����һ���Ǽ��ٿռ�ά�ȵ�������Ԫ�����ļܹ���ͨ����Ԥ����ķ�ʽ�ѵ���Щ��Ԫ�������ģ���ͼ3��ʾ�����������۵������ռ���ȣ��������ռ����������ƣ�
- �����ռ�Ĵ�С����С����Ϊ��Ԫͨ������������������ϵ�ṹ�IJ���ɡ����磬Zoph���ˣ�2018�꣩���ƣ�������֮ǰ�Ĺ�����Zoph��Le��2017�꣩��ȣ���ʵ�ָ������ܵ�ͬʱ���ٶ������7����
- ͨ���ظı�ģ����ʹ�õĵ�Ԫ���������������ӵ�Ԫ��������ϵ�ṹ���Ը����ش������Ӧ�������ݼ�����ʵ�ϣ�Zoph���ˣ�2018�꣩��CIFAR-10���Ż���ϸ��ת�Ƶ�ImageNet��ʵ�����Ƚ������ܡ�
- ͨ���ظ���������������ϵ�ṹ�ѱ�֤����һ�����õ����ԭ��������RNN���ظ�LSTM���ѵ�ʣ��顣
��ˣ����ֻ���ϸ���������ռ�Ҳ�������������Ʒ�ɹ������ã�Real et al.��2019��Liu et al.��2018a��Pham et al.��2018��Elsken et al.��2019��Cai et al.��2018b��Liu et al.��2019b��Zhong et al.��2018b����Ȼ������ʹ�û��ڵ�Ԫ�������ռ�ʱ��������һ���µ����ѡ�����ѡ�����ϵ�ṹ��Ӧ��ʹ�ö��ٸ���Ԫ���Լ������������������ʵ��ģ�ͣ����磬Zoph et al.��2018���ӵ�Ԫ����һ������ģ�ͣ�����ÿ����Ԫ����ǰ������Ԫ�������Ϊ���룬��Cai et al.��2018b���������������ֶ���Ƽܹ��ĸ��ṹ������DenseNet��Huang et al.��2017����������Щģ����ʹ�����ǵĵ�Ԫ��ԭ���ϣ�����ͨ�����õ�Ԫ�滻����������ϵ�Ԫ�����磬���������֧�ռ��ڡ���������£�����ϵ�ṹ����ϵ�ṹ������Ԫ�Ľṹ����Ӧ�������Ż��������ǵ����Ż���ϵ�ṹ���������ҵ��������õĵ�Ԫ�����Ͳ��ò������ֶ�����ϵ�ṹ���̡��Ż���ܹ���һ��������Liu���ˣ�2018b������ķֲ������ռ䣬���ɶ����εĻ�����ɡ���һ����һ���Ԫ������ɣ��ڶ�����ͨ��������ͼ���ӻ�Ԫ�����IJ�ͬ��Ԫ��ɣ��������ɱ���������ӵڶ�����Ԫ�Ļ�Ԫ��ɣ��������ơ����ڵ�Ԫ�������ռ���Կ��������ֲַ������ռ��һ�����������в����Ϊ3���ڶ���εĻ����Ӧ�ڵ�Ԫ�����������Ӳ����ĺ�ṹ��
�����ռ��ѡ���ںܴ�̶��Ͼ������Ż�������Ѷȣ���ʹ�ǻ��ھ��й̶���ṹ�ĵ�����Ԫ�������ռ䣬�Ż�������Ȼ�ǣ�i���������ĺͣ�ii����Ը�ά�ģ���Ϊ�����ӵ�ģ���������ָ��ã����¸������ƣ�ѡ��
����ע������������ռ��еļܹ�����дΪ�̶��������������磬Zoph���ˣ�2018����������Ԫ�е�ÿ����Ԫ�������ռ����дΪ���з���ά�ȵ�40ά[1]�����ռ䣬ÿ�������ռ���������ͬ�Ĺ����������֮�����ѡ���������ռ���Ա�����Ϊ���У����ܷdz������ޣ������IJ㣬���ٴβ������У����ࣩܺܶ����ά�Ĺ̶���С�����ռ䡣
3.��������
���ͬ���������Կ�������̽���ṹ�Ŀռ䣬���������������Ҷ˹�Ż�������������ǿ��ѧϰ��RL���ͻ����ݶȵķ�������ʷ�ϣ���ʮ��ǰ�������о���Ա�Ѿ�ʹ�ý����㷨�������ṹ��ͨ���������ǵ�Ȩ�أ����μ�������Angeline et al.��1994��Stanley and Miikkulainen��2002��Floreano et al.��2008��Stanley et al.��2009��Jozefowicz et al.��2015����Ҧ��1999����2000����ǰ�Ĺ�������������������
��2013����������Ҷ˹�Ż���NAS����ȡ���˼������ڳɹ����γ������Ƚ����Ӿ���ϵ�ṹ��Bergstra et al.��2013����ʵ����CIFAR-10����������ǿ������µ����Ƚ����ܣ�Domhan et al.��2015�����Լ���һ����������ר�ҵ����ݼ������л�ʤ���Զ���г�����磨Mendoza et al.��2016������Zoph��Le��2017��ͨ������ǿ��ѧϰ������������CIFAR-10��Penn Treebank�������л�þ����Ա��ֺ�NAS��Ϊ����ѧϰ��������о����⡣��ȻZoph��Le��2017��ʹ���˴����ļ�����Դ��ʵ����һ�����800 gpu������3��4�ܣ����������ǵĹ���֮���ָ����ķ�����̷������Խ��ͼ���ɱ���ʵ�����ܵĽ�һ���Ľ���
Ϊ�˽�NAS�綨Ϊǿ��ѧϰ��RL�����⣨Baker et al.��2017a��Zoph and Le��2017��Zhong et al.��2018a��Zoph et al.��2018�������Խ��ṹ��������Ϊ�����Ķ����������ռ��������ռ���ͬ�������ı����ǻ��ڶԲ��ɼ����ݵ�ѵ����ϵ�ṹ���ܵĹ��ƣ�����4�ڣ�����ͬ��RL��������α�ʾ�����IJ����Լ�����Ż����Է���������ͬ��Zoph��Le��2017��ʹ�õݹ������磨RNN���������ζ��ַ������в��������ַ������������ṹ���б��롣�������ʹ��ǿ�������ݶ��㷨��Williams��1992��ѵ�������磬���ں���������Zoph et al.��2018����ʹ���˽��˲����Ż���Schulman et al.��2017����Baker���ˣ�2017a��ʹ��Q-ѧϰ��ѵ�����ԣ��ò�������ѡ�������ͺ���Ӧ�ij���������Щ��������һ�ֹ۵�����Ϊ˳����߹��̣����в��ԶԲ������в�����˳��������ϵ�ṹ�������ġ�״̬��������ĿǰΪֹ�����IJ�����ժҪ�����ң�δ�ۿ۵ģ������������ղ���֮���á�Ȼ�����������������������û���뻷���Ľ�����û�й۲쵽�ⲿ״̬��Ҳû���м�ر��������Ƿ��ֽ��ܹ��������̽���Ϊ�����������������ɸ�Ϊֱ�ۣ���ͽ�RL�����Ϊ��״̬����װ�������⡣
Cai���ˣ�2018a�������һ����صķ���������NAS����Ϊһ��˳����߹��̣������ǵķ����У�״̬�ǵ�ǰ������ѵ���ģ��ܹ����ر��Ǽܹ����ܵĹ��ƣ�������Ӧ�ڱ������ܵ�ͻ���Ӧ�ã�����Ϊ������壨Chen���ˣ�2016��Wei���ˣ�2017����������4�ڣ�������������ѵ�Ρ�Ϊ�˴����ɱ䳤�ȵ�����ṹ������ʹ��˫��LSTM���ṹ����ɹ̶����ȵı�ʾ���������ֱ����ʾ��������������������Ķ������������������Ϲ����˲��ԣ��ò���ͨ����ǿ�����ݶ��㷨���ж˵��˵�ѵ��������ע����ַ����������η�����ͬ��״̬���ܹ�����
ʹ��RL����һ�ַ�����ʹ�ý����㷨�Ż��ṹ������������������֪���ĵ�һ�����������ķ��������ݵ�����ʮ��ǰ��Miller���ˣ�1989��ʹ���Ŵ��㷨������ṹ����ʹ�÷������Ż���Ȩ�ء��˺���������������Angeline et al.��1994��Stanley and Miikkulainen��2002��Stanley et al.��2009��ʹ���Ŵ��㷨���Ż��ṹ����Ȩ�أ�Ȼ��������Լලѧϰ������չ������������Ȩ�صĵ����ṹʱ������SGD��Ȩ���Ż�����Ŀǰ���ڽ���������[2]���������������Real et al.��2017��Suganuma et al.��2017��Liu et al.��2018b��Real et al.��2019��Miikkulainen et al.��2017��Xie and Yuille��2017��Elsken et al.��2019������ٴ�ʹ�û����ݶȵķ����Ż�Ȩ�أ�������ʹ�ý����㷨�Ż��ṹ�����������㷨������һ��ģ��Ⱥ�壬��һ�飨���ܾ���ѵ���ģ����磻��ÿһ�����������У����ٴ�Ⱥ���г�ȡһ��ģ����Ϊĸ�壬ͨ������Ӧ��ͻ�������ɺ������NAS���������У�ͻ���Ǿֲ��������������ӻ�ɾ���㡢���IJ�ij��������������������Լ�����ѵ������������ѵ�����֮���������ǵ���Ӧ���������磬����֤���ϵı��֣��������������ӵ�Ⱥ���С�
���������IJ�֮ͬ��������ζԸ�ĸȡ����������Ⱥ�Ͳ�����������磬Real et al.��2017����Real et al.��2019����Liu et al.��2018b��ʹ�ý�����ѡ��Goldberg��Deb��1991���Ը�ĸ���г�������Elsken et al.��2019��ʹ�����ܶȴӶ�Ŀ��Paretoǰ�ضԸ�ĸ���г�����Real et al.��2017������Ⱥ���Ƴ������壬��Real et al.��2019�������Ƴ����ϸ��壨����̰����������ģ���Liu et al.��2018b���������Ƴ����塣Ϊ�˲����������������������ʼ�������磬��Elsken et al.��2019������Lamarckian�Ŵ�����֪ʶ����ѧϰȨ�ص���ʽ��ͨ��ʹ������̬��Ӹ����紫�ݸ��������硣Real���ˣ�2017�꣩����������̳��丸ĸ�����в�������Щ��������Ӧ��ͻ���Ӱ�죻��Ȼ���ּ̳в����ϸ�ĺ������֣����������ʼ����ȣ���Ҳ���ܼӿ�ѧϰ�ٶȡ����⣬���ǻ������ı�ѧϰ�ʣ�����Կ�������NAS�ڼ��Ż�ѧϰ�ʵ��ȵ�һ�ַ��������Dzο�Stanley���ˣ�2019���������������������������
Real���ˣ�2019��������һ����о����Ƚ���RL�����������������RS�����ó����ۣ�RL�ͽ��������ղ��Ծ��ȷ��������ͬ���������и��õ���ʱ���ܣ����ҵ���С��ģ�͡������ǵ�ʵ���У����ַ����ı��ֶ���RS�ã�������С��RS��CIFAR-10�ϵIJ������ԼΪ4%����RL��evolution�IJ������ԼΪ3.5%���ڡ�ģ����ǿ������Ⱥ��˲����������ӣ�ʵ��ʹ�õķ���ǿ�ռ�IJ����������ԼΪ2%����Liu���ˣ�2018b���IJ���������С�����DZ�����CIFAR-10�IJ������Ϊ3.9%��ImageNet��RS��top-1��֤���Ϊ21.0%�������ڽ����ķ����ֱ�Ϊ3.75%��20.3%��
��Ҷ˹�Ż���BO���μ������磬��Shahriari et al.��2016�����dz������Ż������еķ���֮һ�������ڵ��͵�BO��������ڸ�˹���̣��������ڵ�ά�����Ż����⣬�������С����δ����Ӧ����NAS��Swersky et al.��2013����Kandasamy et al.��2018���Ƶ��˼ܹ������ռ�ĺ˺������Ա�ʹ�þ���Ļ���GP��BO���������֮�£�һЩ��Ʒʹ�û�������ģ�ͣ��ر�����Parzen��������Bergstra et al.��2011�������ɭ�֣�Hutter et al.��2011��������Ч��������ά�����ռ䣬���ڹ㷺��������ʵ�����Ƚ������ܣ������Ż������ṹ���䳬������Bergstra et al.��2013��Domhan et al.��2015��Mendoza et al.��2016��Zela et al.��2018������Ȼȱ��ȫ��ıȽϣ����г���֤�ݱ�������Щ����Ҳ�������ڽ����㷨��Klein���ˣ�2018����
Negrinho��Gordon��2017���Լ�Wistuba��2017�������������ռ�����ṹ����ʹ�����ؿ�����������Elsken et al.��2017�������һ�ּ��������õ���ɽ�㷨�����㷨ͨ��̰���������ܸ��õļܹ������ƶ������ָ������ļܹ���������Ҫ�����ӵ�̽�����ơ�
��Ȼ��������������ɢ�����ռ䣬��Liu���ˣ�2019b�������һ�������ɳڷ�������ʵ��ֱ�ӻ����ݶȵ��Ż�������û�й̶�Ҫ���ض���ִ�еĵ�������oi�����������أ������Ǵ�һ�����{o1������om}������ϡ��������˵������������x�������y������Ϊ=1������ϵ����i��Ч�ز���������ܹ���Liu���ˣ�2019b��Ȼ��ͨ�������ݶ��½������Ȩ�ص�ѵ�����ݺͽṹ���������������֤�����Ż�����Ȩ�غ�����ṹ�����ͨ��Ϊÿһ��ѡ��i?=argmaxi��i�IJ���i?�������ɢ��ϵ�ṹ��Xie et al.��2019����Cai et al.��2019�������Ż����ܲ����IJ������ֲ����������Ż����ܲ�����Ȩ�ئ���Shin et al.��2018����Ahmed and Torresani��2018��Ҳ�����˻����ݶȵ��ṹ�Ż������ֱ�������Ż��㳬������������ģʽ��
4������������
��������ּ���ҵ�һ�������ijЩ���ܶ������ṹ�������δ֪���ݵ�ȷ�ԡ�Ϊ��ָ�����ǵ��������̣���Щ������Ҫ���Ƹ����ܹ�A�����ܡ�ʵ����һ���������Ǹ���ѵ�����ݶ�A����ѵ������������֤�������������ܡ�Ȼ����ѵ��ÿһ����ͷ��ʼ�����ļܹ�ͨ���������ǧ��ļ�������Zoph and Le��2017��Real et al.��2017��Zoph et al.��2018��Real et al.��2019��������Ȼ�ᵼ�¿����������������ķ������������ڽ�������Щ�������й����з����ĸ���������ı�4��
���ܿ��Ի�������ѵ����ʵ�����ܵĽϵͿ��Ŷ������ƣ�Ҳ��ʾΪ���������������ֽϵ͵Ŀ��ŶȰ����϶̵���ѵʱ��
ʱ�䣨Zoph et al.��2018��Zela et al.��2018���������Ӽ���ѵ��Klein et al.��2017b�����ͷֱ���ͼ����ѵ��Chrabaszcz et al.��2017������ÿ����������٣�ϸ�����٣�Zoph et al.��2018��Real et al.��2019������Ȼ��Щ�ͱ���Ƚ��ƽ����˼���ɱ���������Ҳ���ڹ���������ƫ���Ϊ����ͨ���ᱻ����ֻҪ�������Խ������ڶԲ�ͬ��ϵ�ṹ����������������ȶ�������ܲ��������⡣Ȼ��������Ľ�������������۽���ֵ�͡�����������ֵ֮��IJ������ʱ����������������ܻᷢ����仯��Zela���ˣ�2018������������߿��Ŷȣ�Li���ˣ�2017��Falkner���ˣ�2018����
������ϵ�ṹ���ܵ���һ�ֿ��ܷ����ǻ���ѧϰ�������ƣ�Swersky et al.��2014��Domhan et al.��2015��Klein et al.��2017a��Baker et al.��2017b��Rawal and Miikkulainen��2018����Domhan et al.��2015���������Ƴ�ʼѧϰ���ߣ�����ֹ��ЩԤ����ֲ��ѵ����ߣ��Լ��ټܹ���architecture���������̡�Swersky et al.��2014����Klein et al.��2017a����Baker et al.��2017b���Լ�Rawal��Miikkulainen��2018��Ҳ������Ԥ����Щ����ѧϰ��������ǰ���ļܹ���������Liu���ˣ�2018a��Ҳ�����һ������Ԥ�����ͼܹ����ܵ����ģ�ͣ���ģ�Ͳ�����ѧϰ�������ƣ���֧�ֻ��ڼܹ�/��Ԫ����Ԥ�����ܣ������Ƶ���ѵ���ڼ俴���ĸ���ļܹ�/��Ԫ��Ԥ���ṹ���ܵ���Ҫ��ս�ǣ�Ϊ�˼ӿ��������̣���Ҫ����Խ��ٵ������Ļ����ϣ�����Խϴ�������ռ��н������õ�Ԥ�⡣
��һ�ּ������ܹ��Ƶķ����ǻ�����ǰѵ������������ϵ�ṹ��Ȩֵ��ʼ������ϵ�ṹ��Ȩֵ��ʵ����һ���һ�ַ�������Ϊ������壨Wei et al.��2016���������ļܹ���ͬʱ���������ʾ�Ĺ��ܲ��䣬�Ӷ�����ֻ��Ҫ����GPUʱ��ķ�����Elsken et al.��2017��Cai et al.��2018a��b��Jin et al.��2018����������������������������������ָ����ܣ��������ͷ��ʼ��ѵ������ʱ�ڵļ���ѵ��Ҳ�������������������Ķ�����������Щ������һ���ŵ��ǣ��������������ռ䣬����������ϵ�ṹ��С�Ĺ������ޣ�Elsken et al.��2017������һ���棬�ϸ���������ֻ��ʹ��ϵ�ṹ���Ӷ����ܵ��¹��ڸ��ӵ���ϵ�ṹ�������ͨ���������������ܹ��Ľ���������̬��������Elsken et al.��2019����
һ���Լܹ���������ͼ4�������мܹ���Ϊһ����ͼ�IJ�ͬ��ͼ������ģ�ͣ������ھ��иó�ͼ��ͬ��Ե�ļܹ�֮�乲��Ȩ�أ�Saxena��Verbeek��2016��Brock et al.��2017��Pham et al.��2018��Liu et al.��2019b��Bender et al.��2018��Cai et al.��2019��Xie et al.��2019����ֻ��ѵ����������ģ�͵�Ȩ�أ��Ը��ַ�ʽ֮һ����Ȼ��ͨ���ӵ���ģ�ͼ̳�ѵ����Ȩ�أ������κε�����ѵ�����������ܹ�����Ϊ����ģ�͵���ͼ��������ӿ�����ϵ�ṹ��������������Ϊ����Ҫ�κ���ѵ��ֻ������֤���ݵ����ܣ���ͬ��������ֻ��Ҫ����GPUʱ��ķ�����һ����ģ��ͨ��������ܴ��ƫ���Ϊ�����ص��������ϵ�ṹ��ʵ�����ܣ�Ȼ��������������ϵ�ṹ��������������Ƶ�������ʵ������������أ�����㹻�ˡ�Ȼ����Ŀǰ�в������������Ƿ���ʵ��Bender���ˣ�2018�ꣻSciuto���ˣ�2019�꣩��
��ͬ�ĵ���NAS�����ڵ���ģ�͵�ѵ����ʽ��������ͬ��ENAS��Pham et al.��2018��ѧϰRNN���������ÿ������������ռ�Լܹ����в�����������ͨ����ǿ��õĽ����ݶ�ѵ������ģ�͡�DARTS��Liu���ˣ�2019b��ͨ������ѡ�����Ļ�Ϸ����ڵ���ģ�͵�ÿһ�����ϣ���������ռ�������ɳڣ��Ż��˵���ģ�͵�����Ȩ�ء�SNAS��Xie���ˣ�2019��û����DARTS�����Ż�������ʵֵȨ�أ������Ż��˺�ѡ�����ķֲ������߲��þ���ֲ���Maddison et al.��2017��Jang et al.��2017�������²�������Kingma and Welling��2014����������ɢ�ֲ���ʹ������Ӷ�ͨ���ݶ��½�ʵ���Ż���Ϊ�˿˷�������һ����ģ�ͱ�����GPU�ڴ��еı�Ҫ�ԣ�ProxylessNAS��Cai et al.��2019������ֵ�����ܹ�Ȩ�أ��ڸ�ÿ����������һ����֮������бߡ�Ȼ��ͨ������һЩ��ֵ���ļܹ���ʹ��BinaryConnect��Courbariaux et al.��2015��������Ӧ�ĸ�����ѧϰ��Ե���ڱλ��ڱεĸ��ʡ�Bender���ˣ�2018�ֻ꣩ѵ��һ�ε���ģ�ͣ���������ʹ��·���˳���ѵ���ڼ����ͣ�ø�ģ�͵IJ���ʱ�������㹻�ġ�

��Ȼ������������ѵ�ڼ��Ż��˼ܹ��ϵķֲ�����Bender���ˣ�2018���ķ������Ա���Ϊʹ�ù̶��ֲ����������ܻ�õĸ����ܱ����������ֵ��̶�����ϸѡ�ֲ�����Ͽ��ܣ�Ҳ�����˾��ȵأ���һ����NAS�����Ψһ�ɷ֡�����Щ������ص��dz������Ԫѧϰ����Ϊ�µ���ϵ�ṹ����Ȩ�أ����ֻ��Ҫѵ�������磬������Ҫѵ����ϵ�ṹ������Brock et al.��2017��Zhang et al.��2019�����������Ҫ��������Ȩ�ز����ϸ����ģ������ɹ����ij��������ɵģ��Բ�������ϵ�ṹΪ��������
����NAS��һ���ձ������ǣ�Ԥ�ȶ���ij�ͼ�������ռ�����������ͼ�ϡ����⣬�ڼܹ������ڼ�Ҫ��������ͼפ����GPU�洢���еķ�������Ӧ������Ϊ��Խ�С�ij�ͼ�������ռ䣬�������ͨ������ڵ�Ԫ�������ռ���ʹ�á���Ȼ����Ȩ�ع����ķ�����������NAS����ļ�����Դ������ǧ����ٵ��˼���GPU����������ܹ��IJ����ֲ���һ����ģ��һ���Ż���������������Ŀǰ���������������������������Щƫ��Bender et���ˣ�2018�꣩�����磬��̽�������ռ��ijЩ����ʱ���������ָ���ij�ʼƫ����ܻᵼ��һ����ģ�͵�Ȩ�ظ��õ���Ӧ��Щ�ܹ����ⷴ�����ֻ��ǿ�����������ռ����Щ���ֵ�ƫ�����ܵ���NAS�������������ܹ���һ�������ܺ���ʵ����֮�������Ժ�С��Sciuto et al.��2019����һ����˵����ϵͳ�ط����ɲ�ͬ�����ܹ��������ƫ���δ��������һ�����뷽��
5δ����չ����
�ڱ����У����ǽ�����NAS�о��ļ�����ǰ��δ���������е��о���༯���ڻ���NAS��ͼ������ϡ�һ���棬���ṩ��һ��������ս�ԵĻ����ԣ���Ϊ�����ֹ����̶�������Ѱ��������������������Ҳ����ױ�NAS��Խ����ϵ�ṹ����һ���棬ͨ�������ֹ������е�֪ʶ��������ʵ������ռ�������ס��ⷴ������ʹ��NAS��̫�����ҵ����ܴ������������ϵ�ṹ����ϵ�ṹ����Ϊ�ҵ�����ϵ�ṹ�����и�����������ˣ�������Ϊ��Ҫ����Ҫ��Խͼ��������⣬��NASӦ����̽�����ٵ�������ͼ��ָ���Suganuma et al.��2018��������ָChen et al.��2018��Nekrasov et al.��2018��Liu et al.��2019a����ת��ѧϰ��Wong et al.��2018�����������루So et al.��2019����ǿ��ѧϰ��Runge et al.��2019��[3]�Լ��Ż��ݹ������緽�棬�Ѿ����ⷽ��������ֵ��ע��ĵ�һ�����磨Greff et al.��2015��Jozefowicz et al.��2015��Zoph and Le��2017��Rawal and Miikkulainen��2018�����������Ի����ֽ�ģ��NAS�Ľ�һ����ϣ����Ӧ�������������ԶԿ���������ںϡ�
��һ����ϣ���ķ����ǿ��������������NAS������Liang���ˣ�2018��Meyerson��Miikkulainen��2018���Ͷ�Ŀ�������NAS������Elsken���ˣ�2019��Dong���ˣ�2018��Zhou���ˣ�2018����������ԴЧ�ʵIJ���ֵ���δ֪���ݵ�Ԥ������һ������Ŀ�ꡣ����ǿ����Ŀ��NAS������ѹ��������أ�Han et al.��2016��Cheng et al.��2018�������߶�ּ���ҵ��������õ���Ч�ļܹ�����ˣ�һЩѹ������Ҳ����ΪNAS������Han et al.��2015��Liu et al.��2017��Gordon et al.��2018��Liu et al.��2019c��Cao et al.��2019������֮��Ȼ��Saxena and Verbeek��2016��Liu et al.��2019b��Xie et al.��2019����
ͬ������չRL/bandit���������3�������۵ķ�������ѧϰ�Ա�����������/��Դ�����״̬Ϊ�����IJ��ԣ�����������ת��Ϊ������bandit��Ҳ�Ǻ�����˼�ġ�Ramachandran��Le��2018��Ҳ��ѭ�����Ƶķ�����չ��һ����NAS���Ը��������ʵ����̬���ɲ�ͬ����ϵ�ṹ�����⣬��NASӦ���������ԶԿ���ʾ����ǿ��ļܹ���Cubuk et al.��2017����һ����Ȥ�Ľ��ڷ���
�����ص��Ƕ����ͨ�ú����������ռ���о������磬���ڵ�Ԫ�������ռ��ڲ�ͬ��ͼ���������֮���ṩ�˺ܸߵĿ�ת���ԣ�����Ҫ����������ͼ������ľ��飬�������ƹ㵽Ӳ�����νṹ������״�ṹ���ظ���ͬ��ϸ�����Σ������õ������������磬����ָ��Ŀ���⣩����ˣ�������ʾ��ʶ���һ���νṹ�������ռ佫ʹNAS���㷺�����ã��ⷽ��ĵ�һ�����Liu���ˣ�2018b��2019a�������⣬���������ռ仹����Ԥ����Ĺ����飬���粻ͬ���͵ľ����ͳأ����������ڴ˼�����ʶ���µĹ����飻���������ƿ��ܻ�������NAS�Ĺ��ܡ�
NAS��ͬ�����ıȽϣ��������������������[4]���ܸ��ӣ���Ϊ��ϵ�ṹ���ܵIJ���ȡ������ϵ�ṹ����������������ء���Ȼ��������߱�����CIFAR-10���ݼ��Ľ������ʵ�������������ռ䡢����Ԥ�㡢�������䡢ѵ�����������������ط���������ͬ�����磬����CIFAR-10����ʹ�������˻�ѧϰ���ʱ���Loshchilov��Hutter��2017����ͨ�����У�Devries��Taylor��2017����ͨ����ϣ�Zhang���ˣ�2017����ͨ��������ϣ�Cubuk���ˣ�2018����ͨ����������Gastaldi��2017����ScheduledDropPath��Zoph���ˣ�2018������ˣ�����������NAS���ֵĸ��õ���ϵ�ṹ��ȣ���Щ�ɷֵĸĽ��Ա�������������и����Ӱ�졣��ˣ�������Ϊ��ͬ���Ķ�����ڹ�ƽ�Ƚϲ�ͬ��NAS����������Ҫ����һ����ĵ�һ����Ying���ˣ�2019������Ļ������п������ɴ�Լ423000�����ؾ����ṹ��ɵ������ռ䡣�ÿռ��ÿ��Ԫ�ض��������Ԥѵ�����������γ���һ������ѵ������֤�Ͳ��Ծ����Լ�ѵ��ʱ���ģ�ʹ�С�����ݼ������ڶ�����еIJ�ͬѵ��Ԥ�㡣��ˣ�ͨ���ز�ѯԤ�ȼ�������ݼ������Խ���ͬ������������˻��ϵĵͼ�����Դ���бȽϡ���֮ǰһ���С���о��У�Klein���ˣ�2018�����ṹ�ͳ������Ĺؽڿռ������Ԥ����������NAS����Ҳ����Ȥ�����ǹ����ģ�������Ϊһ�������Ŀ���Դ��AutoMLϵͳ��һ���֣����г�������Mendoza et al.��2016��Real et al.��2017��Zela et al.��2018����������ǿ�ܵ���Cubuk et al.��2018��Ҳ��NASһ���Ż���
��ȻNAS�Ѿ�ȡ��������ӡ����̵����ܣ�����ĿǰΪֹ���������ض���ϵ�ṹΪʲô���������Լ�������������������ϵ�ṹ���������ṩ�˺��ٵļ��⡣ʶ���Ļ�������Ϊʲô��Щ����Ը����ܺ���Ҫ����������Щ�����Ƿ������ڲ�ͬ�����⡣