作者:徐晗曦
原文:写给大家看的机器学习书(第二篇)
本次转载已获得作者授权,尊重原创,若需转载请联系作者本人。相关文章:
写给大家看的机器学习书【Part1】什么是机器学习?机器学到的到底是什么?
在《写给大家看的机器学习书》的第一篇,我们了解了机器学习的基本概念,机器学习的三个要素——数据、学习算法和模型(如图1所示)。
图1:
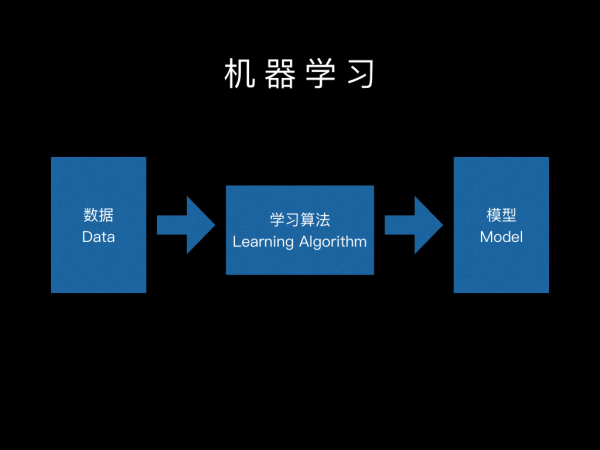
在这个系列的第二篇,我将首先借有好货这个真实的应用场景,让大家看看数据长什么样,了解现实中的机器学习输入数据是怎么来的。
接着,我们需要引出模型的的符号化表示和定义。数学符号的引入一方面有利于后续进入到具体的学习算法的讨论时有更高的效率,另一方面这也是每个学习者准确理解机器学习绕不过去的一环。
然后,在理解了输入数据,熟悉了模型的符号化表示后,我们将对图1所示的相对粗略的机器学习流程做进一步的细化,细化后如图3所示。如果说学完这一篇你只能带走一点知识的话,那就带走图3吧。一图胜千言,以后别人再问你机器学习是什么,大胆说出让机器学习专家也吃惊的精准理解吧:)
在这篇文章中,我们将接触到不少机器学习最常用到的名词、术语。不要小看名字的力量,一个东西一旦你知道了它的名字,就更容易注意到它的存在,并且掌握它。
1. 数据(Data)
1.1 数据长什么样
图2:
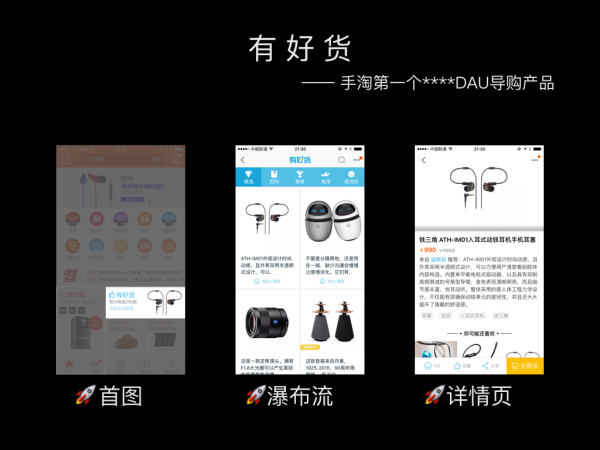
我们仍然以有好货产品的“瀑布流”页面(图2中间)为例,来看看机器学习的输入数据长什么样。
有好货瀑布流页是一个完全个性化的页面,不同的用户进入到有好货瀑布流页,看到的商品推荐是不同的。
我们希望在有限的屏幕空间内给每个用户展示他最有可能点击的商品,因此机器学习的目标是要让学得的模型能够预判用户是否会点击某个商品。
要学得这样的模型,输入数据简单来说大约长这样(表1所示):
表1
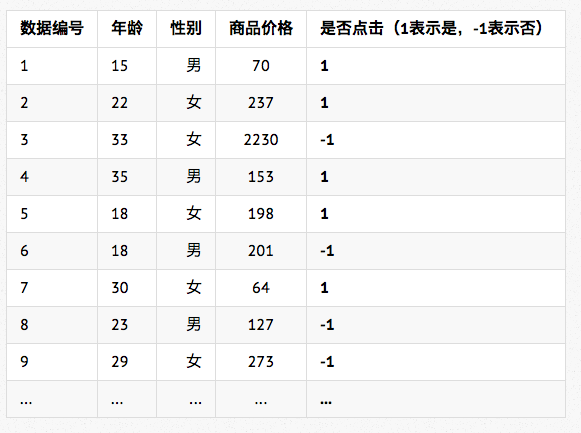
像这样的学习算法的输入数据,叫“训练数据”(Training Data)。
训练数据的每一行称为一个“训练样本”(Training Sample),通常大家就简称“样本”(Sample)。
我们注意到,每个样本有三个属性——年龄、性别、商品价格,代表了我们认为用户是否会点击某个商品主要由年龄、性别、商品价格三个因素共同决定(当然这里我们做了简化,实际上影响的因素远不止三个)。
这里的年龄、性别、商品价格我们称之为“特征”(Feature)。
在这个场景中,我们希望学得的模型可以用来预判用户是否会点击某个商品,因此光有年龄、性别、商品价格这样的特征信息还不够,还需要知道每个训练样本用户是否会点击。“是否点击”这个信息,称为样本的标注(Lable)。
1.2 训练数据怎么来的
了解了训练数据的长相,一定有人会问:训练数据是怎么来的呢?
其实也很简单,这个大数据时代,绝大多数互联网产品都会把用户的行为数据——包括浏览历史、点击历史记录下来,我们称为日志(Log)。
从日志数据中就能知道每个用户点过什么商品(对应标注为1的样本),看了什么商品却没有点(对应标注为-1的样本),再关联上用户的特征数据(年龄、性别)和商品的特征数据(价格),就得到学习算法所需要的训练数据了。
1.3 机器学习问题的分类
需要指出的是,并不是所有的机器学习问题都需要标注。事实上,根据训练数据是否有标注,机器学习问题大致划分为监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)两大类。
- 监督学习:每个输入样本都有标注,这些标注就像老师的标准答案一样”监督“着学习的过程。而监督学习又大致分成两类:分类(Classification)和回归(Regression):
- 分类问题:标注是离散值,比如用户”点击“和”不点击“。如果标注只有两个值,则称为二分类,如果标注有多个值,则称为多分类。
- 回归问题:标注是连续值,比如如果问题是预测北京市房屋的价格,价格作为标注就是一个连续值,属于回归问题。
- 无监督学习:训练样本没有标注,无监督学习解决的典型问题是聚类(clustering)问题。比如对一个网站的用户进行聚类,看看这个网站用户的大致构成,分析下每类用户群的特点是什么。
此外,机器学习还有其他的类别,比如半监督学习、增强学习,我们将慢慢涉及。
2. 模型 (Model)
还记得在第一篇我们说”机器学到的模型是一个映射”,这是一个很好理解又非常准确的表述。
可是在后续的学习中,尤其是进入到具体的学习算法的讨论时,文字表达的效率不如符号表示来的高,所以现在我们就要引出模型的符号化表示和定义。这不仅能大大的提升后续讨论学习算法时的效率,也是准确理解机器学习绕不过去的一环。
其实也很简单,映射包括输入和输出,在这里输入就是用户的年龄、性别、商品价格,输出就是用户是否会点击,好,我们开始吧。
2.1 映射的输入
- 输入样本用符号x表示,第i个样本记作xi。
- 每个样本有三个特征,于是样本xi又可以写成一个向量xi=(xi1, xi2, xi3)( xi1 在这里指年龄、xi2指性别、xi3指商品价格),称为“特征向量” (Feature Vector)。
- 所有的特征向量的集合就是总的输入集合,这个例子中本质上是个三维向量张成的三维空间,称为“样本空间” (Sample Space)或“输入空间”,记作χ。任意的输入x都是这个3维样本空间χ中的一个向量,用符号表示就是x∈χ(读作x属于χ)。
2.2 映射的输出
- 输出的样本标注用符号y表示,第i个样本的标注记作yi。
- 在这个例子中标注只有-1和1两种取值,我们用一个一维向量y=(yi1)就可以表示。同样的,这个一维向量张成的空间就是“标注空间”(Label Space)或“输出空间”,记作Y。任意的输出y都属于Y,用符号表示就是y∈Y。
2.3 映射的表示
于是机器学习模型就是输入空间χ到输出空间Y的一个映射,将映射用符号g表示,则模型记作g:χ→Y。
学得这个模型之后我们对于新的样本要预测用户是否会点击,只需要将样本x (x∈χ)传入映射函数g,得到的输出y=g(x) (y∈Y)就是对用户是否会点击的预测。
3. 机器学习概念图的细化
上面我们讲了训练数据,也讲了模型,现在我们知道学习算法的目标就是要学一个映射函数g 。一旦学到g之后对于任意的输入x,都可以计算出预测结果y就等于g(x) 。
这小节我们将图1所示的相对粗略的机器学习概念做进一步的细化,细化后如图3所示。
如果说学完这一篇你只能带走一点知识的话,那就带走这张图吧。一图胜千言,希望你看到图3就能回忆起整篇内容。
3.1 数据(Data)部分的细化
首先,我们假设有一个完美的映射f,它不仅对训练数据中的所有样本都能够正确的预测用户是否点击,对于遇到的新的样本也是一样(用符号表示就是对于任意样本(xi,yi),映射f都能够使得yi=f(xi))。
如果我们能得到这样一个完美的映射,问题就解决了,不过很可惜,这样一个完美的模型只有上帝才知道,它代表了学习的最理想的目标,人们称它为“上帝真相”(Ground Truth),有时也叫做目标函数(Target Function)。
既然我们不知道,也无法知道Ground Truth f,我们怎么能做到以它为目标进行学习呢?不要忘了我们还有训练数据,既然训练数据中所有样本都满足f,当训练样本足够多时我们不妨认为海量的样本就反映了Ground Truth f
的样子,我们称这种情况为“训练数据来自于f”。(如图3下半的左侧部分所示)
3.2 学习算法和模型部分的细化
假设了Ground Truth f的存在,那么学习算法要做的就是找出某个映射,这个映射尽可能得接近f。在实际的训练过程中,学习算法会有一个假设集合(Hypothesis Set,记作H),这个集合包含所有候选的映射函数。学习算法做的事情就是从中选出最好的g,使得g越接近f越好。(如图3下半的中间部分和右侧侧部分所示)
综上
综上,我们把机器学习流程重新细化成下图所示:
图3:
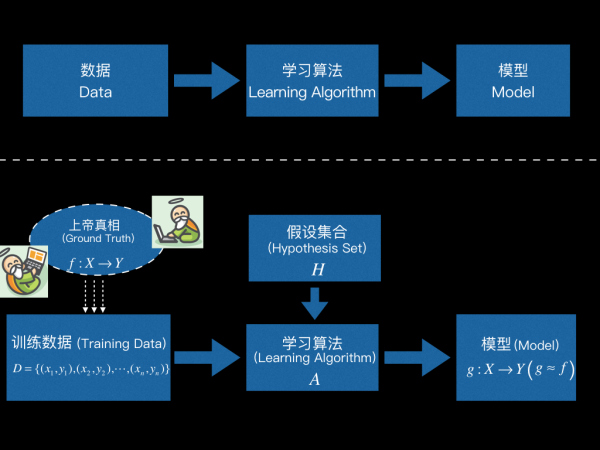
输入数据D={(x1,y1),(x2,y2),…,(xn,yn)},来自于Ground Truth。
Learning Algorithm根据训练数据,从Hypothesis Set中选出最优的那个映射g:χ→Y作为最终学得的模型,使得g越接近f越好(g≈f)。
到这里,我们看着图3就可以用一句话来定义机器学习
Machine Learning:Use training data to compute model g that approximates Ground Truth f.
预告和其它
下一篇将介绍一个具体的学习算法和模型,它足够基础也足够典型,甚至是人工神经网络大门入门的第一步。
另外,有同学在评论中问怎样可以收到后续文章的更新,经测试,如果你希望在Timeline中收到更新,可以考虑关注我。如果你希望在通知中心中收到通知以确保不miss更新,可以考虑关注这个同名专栏。
再次感谢您的阅读。希望我有把事情说清楚,有任何疑惑或者问题,欢迎留言。
祝开心 :)
下一篇:写给大家看的机器学习书【Part3】直观易懂的感知机学习算法PLA

