目录
- 入门篇:图像深度估计相关总结
- 应用篇:Learning to be a Depth Camera
- 尺度篇:Make3D
- 迁移篇:Depth Extraction from Video Using Non-parametric Sampling
- 深度篇:David Eigen
- 无监督篇:Left-Right Consistency & Ego Motion
- 相对深度篇:Depth in the Wild & Size to Depth
- SLAM辅助篇:MegaDepth
- 方法比较篇:Evaluation of CNN-based Methods
单目图像深度估计 - 相对深度篇:Depth in the Wild & Size to Depth
目前单目图像深度估计需要面临的主要问题之一就是我们用来获得ground truth depth的硬件设备本身具有一定误差和环境限制,比如说基于红外的相机(Kinect)无法在室外使用,而所有设备都只在一定距离范围内具有精确度,超出这个范围的获取结果是不可信的,因此我们所获得的深度图本身就具有一定误差。在误差的基础上进行建模,使得后续模型拟合的难度加大了。
因此就有科学家提出,其实人类对深度的实际数值并不敏感,反而是对相对深度即物体的前后关系更加敏感。这篇笔记打算写的两篇论文都是基于这个思考而来:
[1] Single-Image Depth Perception in the Wild, NIPS, 2016 [Project Page]
[2] Size to Depth: A New Perspective for Single Image Estimation, CVPR, 2018
1. Single-Image Depth Perception in the Wild, NIPS, 2016
这篇文章很有趣,作者指出就算是具有完备又复杂视觉系统的人类也很难推断出物体的实际深度(距离)值,而且人也会被迷惑(比如“鸽子为什么这么大”),但人可以根据经验(物体大小)、遮挡关系、光线和阴影等知识来准确的判断相对深度,即物体的前后关系。之前已经有由相对深度估计绝对深度的研究,但缺少适用于现状的数据集。因此这篇文章的贡献主要有:
- Depth in the Wild数据集
- 通过相对深度预测绝对深度的方法
DIW数据集
目前已有的数据集的缺陷有:基于Kinect的数据集局限于室内场景;基于LIDAR的数据集局限于人造的场景(街道)。因此DIW的数据集的目的是采集更多的非人造场景。
文章作者详细写了数据集的整理和标注方法。首先,从英文词典中随机抽取关键词到图片网站Flickr上搜索,然后手动去除剪贴画等人造的图片,最后用众包的方式获取打标结果。
数据集中相对深度的表达方式为问询(query),一个query可以表达为(i,j,r),其中i,j为两个数据点,r为两点像素的相对深度,0表示难以判断的接近,+1表示i比j更近,-1表示i比j更远。
为了更有效的利用人为的打标信息,数据集中每幅图片选取一对像素点进行一次问询。作者解释说,在一幅图片上选取多个点获取其相对深度是可行的,但存在问题是往往相似的点具有相似的深度,因此在一幅图上标记多点难免产生数据冗余。
文章还对如何选取这唯一的一对像素点进行了探讨。有趣的实验结果如下:
- 直接判定更靠近图片底部的点为较近点可以获得85.8%的预测正确率。
- 同一水平线上的两个点,直接判定更靠近中心点的点为较近的点可以获得71.4%的预测正确率。
因此本文作者选取的方式为:选取同一水平线上距离中心点距离相同(左右对称)的两个点。用这样的选取方式选取的两个点,左边的点为较近点的概率为50.3%。
通过相对深度预测绝对深度
这部分也比较有意思,以我的理解,作者的意思是说假如数据集足够大只需要一个能够拟合相对深度的网络就可以预测绝对深度。是不是说一幅图片如果相对深度能够确定,自然可以确定绝对深度呢?
作者提出的Loss缺失没有依赖绝对深度,而是只根据相对深度。
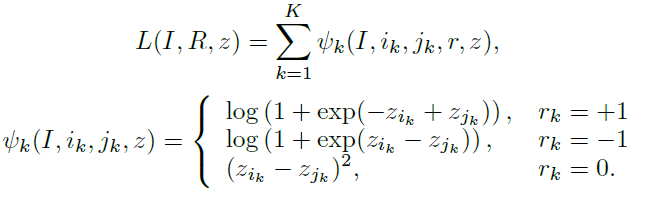
上图为文章提出的Loss,若两个点的相对深度关系为“接近”时Loss让两个点的绝对深度更加接近,反之则让两个点的绝对深度之间具有较大差距。
通过实验发现先在NYU Depth数据集上训练然后在DIW数据集上进行Refine得到的网络具有最优的预测表现。
2. Size to Depth: A New Perspective for Single Image Estimation, CVPR, 2018
上一篇文章有一个主要的问题就是同样的图片可能会对应完全不同的距离值,假设同一部相机在不同距离拍摄相同场景的情况。这篇文章针对这种问题,提出size to depth的方法。
文章中提到了两个很有趣的实验:
- 从2D图片判断绝对深度:被试验者犹豫的时间较长,且结果有21%的相对误差。
- 从2D图片中判断物体尺寸: 被试验者犹豫的时间较短,且结果只有8%的相对误差。
我个人理解,犹豫时间可以表达人类在这方面能力的强弱,因此人类由于先验知识的影响,判断物体尺寸的能力远远好于判断距离的能力。
Size to Depth,根据画面内物体的size信息推测深度。具体过程首先是把图片分割成小块(pitch)为每个pitch设定一个size,这个size由人工标注,size的值为pitch中的主要物体(dominant component)的实际大小,最后用CRF进行平滑。
CRF的研究不算多,可能是因为CRF的复杂度比较高而且会影响到输出size的原因。
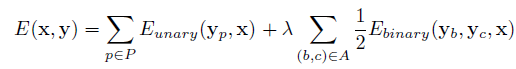
上面公式为文章使用的energy function,其中第一部分的目标是缩小预测值与标记值的差异,第二部分是consistency约束。


