�����ġ�Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.��pdf��
������
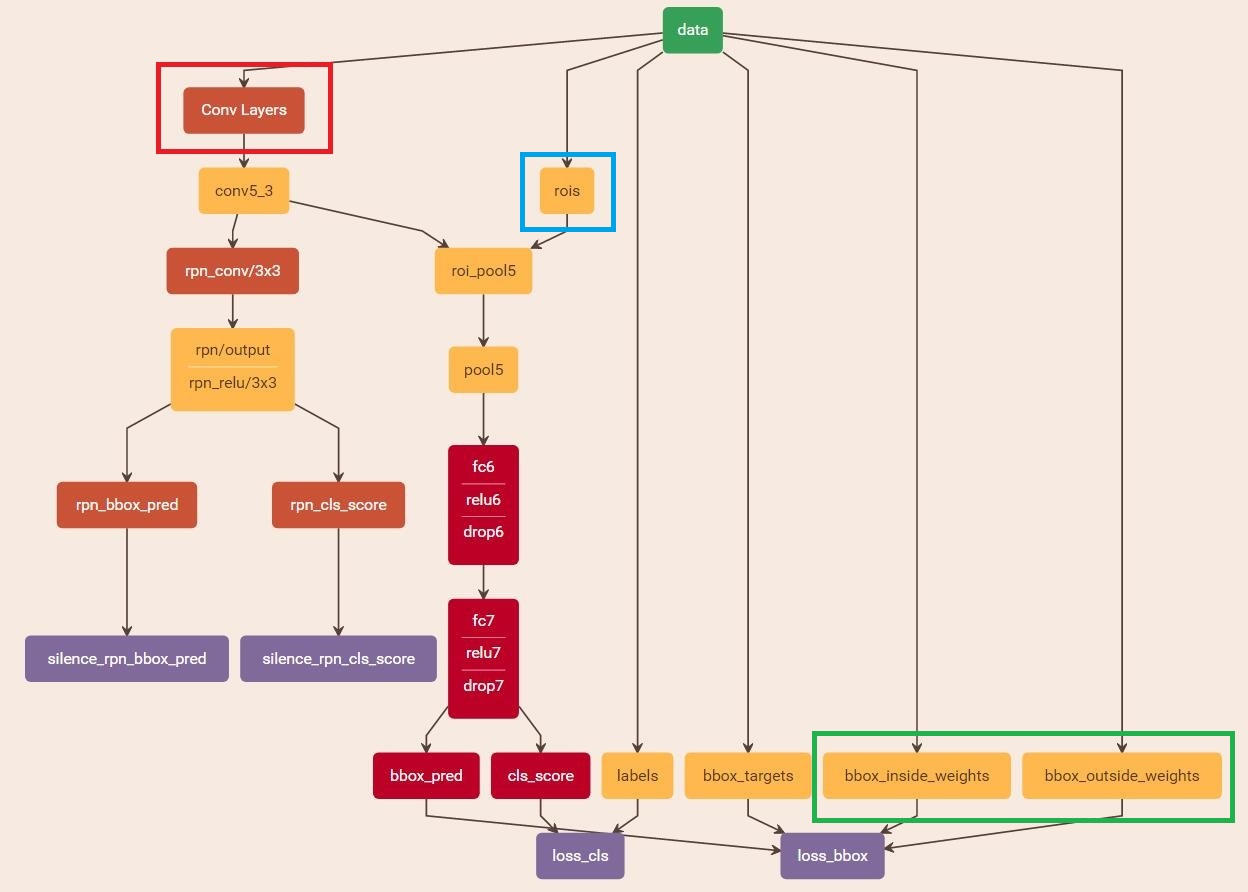
Faster RCNN ���Է�Ϊ 4 ����ģ��;
-
Conv Layers
����ͼƬ��������ȡ������һϵ�е� conv + relu + pooling ������ӳ��
-
Region Proposal Networks
�����Ƽ���ѡ�������֮ǰ�� RCNN �� Fast RCNN �е� search selective��ͨ�� softmax �ж� anchor �������������Ǹ�������Ȼ������ bbox regression ���� anchor ��þ�ȷ�� proposal
-
RoI Pooling
�� Fast RCNN һ��������ͬ��С��״�� proposal ת��Ϊ�̶���С����� proposal feature
-
Classification
���� proposal feature ���� proposal �����ͬʱ�ٴ�ʹ�� bbox regression ��üӲ������վ�ȷλ��

����չʾ�� Faster RCNN ��ϸ�ڴ�������������һ�������С��ͼƬ P��QP\times QP��Q
- ���ȣ��������̶���С M��NM\times NM��N��Ȼ���ٽ�ͼƬ��������
- Conv Layers ������ 13 �������㣨kernel_size = 3, padding = 1, stride = 1�� + 13 �� ReLU + 4 �� �ػ��㣨kernel_size = 2, padding = 0, stride = 2��
- RPN ���Ⱦ��� 3��33\times33��3 �ľ������ֱ����� positive anchor �Ͷ�Ӧ�� bbox regression��Ȼ��������Ҫ�� proposal
- RoI Pooling ������ proposal ��Ӧ feature map �õ� proposal feature����������ȫ��������ͨ�� softmax ������

Conv Layers
Faster RCNN �ж����о����������� padding ������padding = 1�������Ǿ��� 3��33\times33��3 �ľ��������ͼ�Ĵ�С���������ı䣨���������� (M?3+2��1)/1+1=M(M-3+2\times1)/1+1=M(M?3+2��1)/1+1=M��
�����ĺô��ǣ�ÿ�ξ����ػ���ͼƬ��С��СΪԭ����һ�룬�� M2��N2\frac{M}{2}\times\frac{N}{2}2M?��2N?���������� relu ���ı�ͼƬ��С�������ھ��� Conv Layers ��ͼƬ��Ϊ M16��N16\frac{M}{16}\times\frac{N}{16}16M?��16N?�������� RoI Pooling ʱ���dz�������
Anchor Generation Layer
Fast RCNN �лᷴ���ᵽһ�������anchor����ν anchor ��ʵ����һ����ο�9 �������� 3 ����״�������ȴ�ԼΪ 1:11:11:1������1:21:21:2 �� 2:12:12:1��ʵ����ͨ���� anchor �������˼���г��õĶ�߶ȷ���
�� Conv Layers ����� feature map ��ÿ���㶼�䱸�� 9 �� anchor ��Ϊ��ʼ�ļ���������õļ�����ڲ�ȷ������Ҳ����̫���ģ�����������λ���ͨ���ع����������λ��

���Ƕ�����ͼƬ������������ͣ�
-
���ȣ�Conv Layers �е� conv5 �����ά��Ϊ 256��Ҳ������ 256 ������ͼ��ѡ����һ��������� RPN �����룬��ô��ÿ������ά�ȶ��� 256
-
����ÿ������ kkk �� anchor��ÿ�� anchor ��Ϊ positive �� negative����ô����÷־��� 2k2k2k��ͬʱ��ÿ�� anchor ���� (x,y,w,h)(x, y, w, h)(x,y,w,h) 4 ��ƫ���������Ի��� 4k4k4k coordinates
���ǣ������� anchor generation layer �IJ���������ԭͼ�߶���������������ĺ�ѡ anchor��������ԭͼ�Ĵ�СΪ 800��600800\times600800��600����ͨ�� Conv Layer ��feature map �Ĵ�С���� 50��3850\times3850��38������ȡ��������ô�ͻ����� 50��38��9=1710050\times38\times9=1710050��38��9=17100 �� anchor

Bounding Box Regression
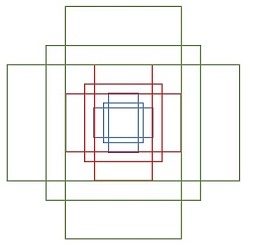
����ͼ��ʾ����ɫ�Ŀ�Ϊ��ȡ�� positive anchor box����ɫ�Ŀ�Ϊ ground truth box�������ɫ�Ŀ����ʶ����ɻ����������ڶ�λ��ȷ��������Ҫ bbox regression �Ժ�ɫ�Ŀ��������ʹ������ӽӽ��� ground truth

����һ�� box ʹ�� (x,y,w,h)(x,y,w,h)(x,y,w,h) ��ʾ���ֱ��ʾ���ĵ��λ�úͿ��ߡ���ͼ�л����ú�ɫ�Ŀ��ʾ positive anchor box A=(Ax,Ay,AwAh)A=(A_x,A_y,A_wA_h)A=(Ax?,Ay?,Aw?Ah?)����ɫ�Ŀ��ʾ ground truth box G=(Gx,Gy,Gw,Gh)G=(G_x,G_y,G_w,G_h)G=(Gx?,Gy?,Gw?,Gh?)������ϣ��Ѱ��һ�ֹ�ϵ����ʹ AAA ����ӳ��õ�һ���� ground truth box ���ӽ��� regression box G��=(Gx��,Gy��,Gw��,Gh��)G'=(G'_x,G'_y,G'_w,G'_h)G��=(Gx��?,Gy��?,Gw��?,Gh��?)

��������ƽ�Ʋ���
Gx��=Aw?dx(A)+AxGy��=Ah?dy(A)+AyG'_x=A_w\cdot d_x(A)+A_x\\ G'_y=A_h\cdot d_y(A)+A_y Gx��?=Aw??dx?(A)+Ax?Gy��?=Ah??dy?(A)+Ay?
��������
Gw��=Aw?exp(dw(A))Gh��=Ah?exp(dh(A))G'_w=A_w\cdot exp(d_w(A))\\ G'_h=A_h\cdot exp(d_h(A)) Gw��?=Aw??exp(dw?(A))Gh��?=Ah??exp(dh?(A))
��ʵ��������Ҫѧϰ�IJ���ֻ�� 4 �� dx(A),dy(A),dw(A),dh(A)d_x(A),d_y(A),d_w(A),d_h(A)dx?(A),dy?(A),dw?(A),dh?(A)���� anchor box �� ground truth box ֮��IJ��첻̫��ʱ�����ǿ��Խ��俴����һ�����Ա任����ô�Ϳ���ʹ�����Իع��������������ʱ����ʱ����һ�������Ե����⣩
���Ա任���Ա�ʾΪ Y=WXY=WXY=WX�������� anchor ��Ӧ�� feature map ��ɵ��������� ?(A)\phi(A)?(A)��ѵ��ͬʱ���� AAA �� GGG ֮��IJ��� (tx,ty,tw,th)(t_x,t_y,t_w,t_h)(tx?,ty?,tw?,th?)����ô�任��Ŀ�꺯���Ϳ��Ա�ʾΪ
d?(A)=W?T??(A)d_*(A)=W_*^T\cdot\phi(A) d??(A)=W?T???(A)
Ϊ����Ԥ��ֵ d?(A)d_*(A)d??(A) ����ʵֵ t?t_*t?? �IJ����С����� L1 ��ʧ����
Loss=��iN�Ot?i?W?T??(Ai)�OLoss=\sum_i^N|t_*^i-W_*^T\cdot\phi(A^i)| Loss=i��N?�Ot?i??W?T???(Ai)�O
�����Ż�Ŀ��Ϊ
W^?=argminW?��iN�Ot?i?W?T??(Ai)�O+�˨O�OW?�O�O\hat W_*=\underset{W_*}{argmin}\ \sum_i^N|t_*^i-W_*^T\cdot\phi(A^i)|+\lambda||W_*|| W^??=W??argmin? i��N?�Ot?i??W?T???(Ai)�O+���O�OW??�O�O
ʵ����ʹ�� smooth-L1 ��ʧ
smoothL1(x)={��2x22�O�Ox�O<1��2�Ox�O�O?0.5��2otherwisesmooth_{L1}(x)=\left\{\begin{matrix} \frac{\sigma^2x^2}{2} & ||x|<\frac{1}{\sigma^2}\\ |x||-\frac{0.5}{\sigma^2} & otherwise \end{matrix}\right. smoothL1?(x)={
2��2x2?�Ox�O�O?��20.5??�O�Ox�O<��21?otherwise?
����� bbox regression ��������Ҫ���ľ����� RPN �ĵڶ���·���� proposal ���� bbox regression��������ͨ�� 1��11\times11��1 �ľ���ʵ�֣����������Ϊ 36���պö�Ӧһ���� 9 �� anchor��ÿ�� anchor �� 4 ���ع�ƫ��
Region Proposal Network
Faster RCNN ������ͳ�Ļ������ں� ss��Selective Search���������ɼ���ֱ�Ӳ��� RPN ���ɼ���RPN �����Ϊ�����ߣ�һ��ͨ�� softmax �����ж� anchor ������������Ǹ��������࣬һ������ anchor �� bbox regression ƫ����������� proposal �㸺���ۺ� positive anchor �ͻع��ƫ������� proposal��ͬʱ���̫С���߽�ļ���

RPN ѵ����������ʧ�������Ա�ʾΪ
L({pi},{ti})=1Ncls��iLcls(pi,pi?)+��1Nreg��ipi?Lreg(ti,ti?)L(\left\{p_i\right\},\left\{t_i\right\})=\frac{1}{N_{cls}}\sum_iL_{cls}(p_i,p_i^*)+\lambda\frac{1}{N_{reg}}\sum_ip_i^*L_{reg}(t_i,t_i^*) L({
pi?},{
ti?})=Ncls?1?i��?Lcls?(pi?,pi??)+��Nreg?1?i��?pi??Lreg?(ti?,ti??)
pip_ipi? ��ʾ positive softmax probability������� iii �� anchor box �� ground truth box �� IoU > 0.7 �� pi?=1p_i^*=1pi??=1 ����� IoU < 0.3��pi?=0p_i^*=0pi??=0�����ڣ�IoU ���� 0.3 �� 0.7 ֮��� anchor ����ѵ����ttt ��ʾ predicted bounding box��t?t^*t? ���� positive anchor ��Ӧ�� ground truth box
�ع���ʧ������һ��ϵ�� pi?p_i^*pi?? ��ʾ����ֻ���� positive anchor ����ʧ������ʵ�ʼ����У�NclsN_{cls}Ncls? �� NregN_{reg}Nreg? �����������ϴ�����������ƽ������ ��\lambda��
��ǰ��������LregL_{reg}Lreg? ʹ�� smooth-L1 ��ʧ
Lreg(ti,ti?)=��i��{x,y,w,h}smoothL1(ti?ti?)ProposallayerL_{reg}(t_i,t_i^*)=\sum_{i\in\left\{x,y,w,h\right\}}smooth_{L_1}(t_i-t_i^*)Proposal layer Lreg?(ti?,ti??)=i��{
x,y,w,h}��?smoothL1??(ti??ti??)Proposallayer
tx=(x?xa)/wa,ty=(y?ya)/hatw=log(w/wa),th=log(h/ha)tx?=(x??xa)/wa,ty?=(y??y)/hatw?=log(w?/wa),th?=log(h?/ha)t_x=(x-x_a)/w_a,\ t_y=(y-y_a)/h_a\\ t_w=log(w/w_a),\ t_h=log(h/h_a)\\ t_x^*=(x^*-x_a)/w_a,\ t_y^*=(y^*-y)/h_a\\ t_w^*=log(w^*/w_a),\ t_h^*=log(h^*/h_a) tx?=(x?xa?)/wa?, ty?=(y?ya?)/ha?tw?=log(w/wa?), th?=log(h/ha?)tx??=(x??xa?)/wa?, ty??=(y??y)/ha?tw??=log(w?/wa?), th??=log(h?/ha?)
���У�x,xa,x?x,x_a,x^*x,xa?,x? �ֱ��Ӧ predicted box��anchor box �� ground truth box
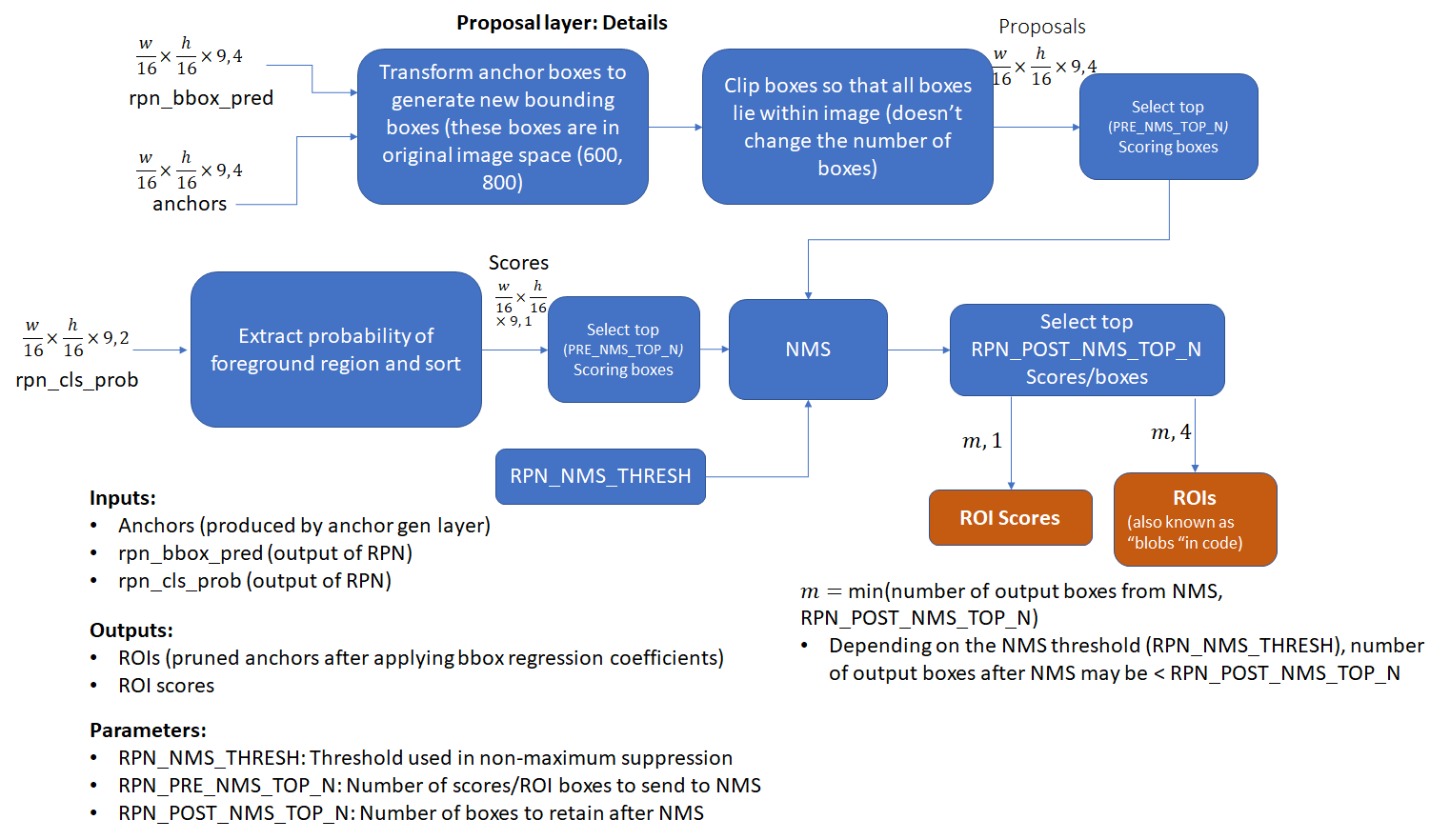
proposal layer
proposal layer �����ۺϻع�ƫ���� positive anchor���������ȷ�� proposal�����˻ع�ƫ���� positive anchor �⣬proposal layer ����һ������ im_info���Լ�һ������ feature_stride = 16
- feature_stride ��¼�� Conv Layers �����ų̶ȣ������� 4 �γػ���ÿ����СΪԭ����һ�룬���յ� feature map Ϊ M16��N16\frac{M}{16}\times\frac{N}{16}16M?��16N?
- ����һ�������С P��QP\times QP��Q ��ͼ�����ŵ��̶���С M��NM\times NM��N��im_fo ��¼��������һ����������Ϣ���� im_fo=[M,N,scale_factor]im\_fo = [M, N, scale\_factor]im_fo=[M,N,scale_factor]

proposal layer ����Ĺ����������£�
- ���ûع�ƫ�������е� anchor ��λ���������� anchor
- ��������� positive softmax socre �� anchor ��������Ȼ����ȡǰ 12k ��������ʱ 6k������λ�ú�� positive anchor
- ������ͼ��߽�� positive anchor Ϊͼ��߽磬��ֹ���� RoI Pooling ʱ proposal ����ͼ��߽�
- ���ߴ�dz�С�� positive anchor
- ��ʣ��� positive anchor ���з�������ƣ�Ȼ��ȡǰ 2k ��������ʱ300 ���� positive anchor
- ���ȡ���� 128 ���������� 128 ������������ѵ��
ֵ��һ��������� proposal layer ������Ƕ�Ӧ M��NM\times NM��N ����߶ȵģ������� feature map �ϵij߶�
RoI Pooling
Ϊʲô��Ҫ RoI Pooling �أ�
����ʷ�ϣ�����ѵ���ú�����ͼ��ijߴ�Ҳ�̶��ˣ����������С��ͬ��ͼ�������ֽ����������1����ͼ���н�ȡ���̶���С������2����ͼ�� warp �ɹ̶���С�����������ַ�ʽ������һ�������⣬��һ���ƻ���ͼ��������ṹ���ڶ����ƻ���ͼ���ԭʼ��״��Ϣ

�� RoI Pooling ���������Ϊ�˽����Щ���⣬�Դ�С��״��ͬ�� proposal ����һ��ͳһ���Ĵ�����RoI Pooling �� Fast RCNN �о��Ѿ��������������Ҳ����ͬ�ģ�
- ����ǰ�洫��� proposal �ߴ��Ӧ M��NM\times NM��N�������Ƚ���ӳ��� M16��N16\frac{M}{16}\times\frac{N}{16}16M?��16N? �� feature map ��С��������
- ��ÿ�� proposal ��Ӧ�������Ϊ pooled_w��pooled_hpooled\_w\times pooled\_hpooled_w��pooled_h��e.g. 7��77\times77��7����С������
- ������ max pooling ����
Classification
Classification ͨ��ǰ��� proposal feature map ����ȫ���Ӳ�� softmax ����ÿ�� proposal ��Ӧÿ�����ĵ÷֡�ͬʱ���� Classification �л��ٴ����� bbox regression ��ÿ�� proposal ��λ�ý��о���

Faster RCNN ѵ��
RPN �� Fast RCNN ����Ҫ������ CNN ������ȡͼ���������������ĵ�������ʹ RPN �� Fast RCNN ����ͬһ���������硣���ǣ�Fast RCNN ��ѵ��������һ��Ū�����Ĺ��̣�
- ��ѵ�� RPN��Ȼ��ʹ�õõ��ĺ�ѡ����ѵ�� Fast RCNN
- ����ʹ�� Fast RCNN �й��ھ�������IJ���ȥ��ʼ�� RPN��Ȼ���ٴ�ѵ�� RPN�����ﲻ���¹��ھ�����������ݣ������� RPN ���еIJ���
- ����ٴ�ѵ�� Fast RCNN������Ҳ�Dz����¹��ھ�������IJ��֣������� Fast RCNN ���еIJ�
�����ڣ��� github �Ͽ�Դ��ʵ�ִ����ý�������ѵ�� approximate joint training�����ö˵��˵�һ��ѵ����

��������ͼչʾ�� Fast RCNN ����������