【论文】acob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova.2018. BERT: Pre-training of
Deep Bidirectional Transformers for Language Understanding. (pdf)
Why is BERT
以往的预训练模型的结构会受到单向语言模型(从左到右或者从右到左)的限制,因而也限制了模型的表征能力,使其只能获取单方面的上下文信息
BERT(Bidirectional Encoder Representation from Transformers) 不再采用以往这种单向语言模型(或把两个单向语言模型进行浅层拼接)进行预训练,而是采用新的 masked language model(MLM)来生成深度的双向语言特征
BERT 具有以下主要的优点:
- 采用 MLM 对双向的 transformer 进行预训练,以生成深层的双向语言表征
- 预训练后,只需要添加一个额外的输出层进行 fine-tuning,就可以在各种各样的下游任务中取得不错的表现。在这个过程中并不需要对 BERT 进行任务特定的结构修改
什么叫双向 transformer?
双向表示模型在处理一个词的时候,能够同时利用前面的词和后面的词两部分信息。它不是在给出前面词的条件下预测最可能的当前‘词,而是随机遮掩一些词,并利用所有没有被遮掉的词进行预测(如下图所示)

单向的 transformer 一般被称为 transformer decoder,每个token 只会注意到其左边的 token,而双向的 transformer 则被称为 transformer encoder ,每一个 token 会被所有的 token 注意到
所以,BERT 丢弃了 transformer 的 decoder,选择 encoder 作为基础集成单元。论文中介绍了两种版本:
- BERT BASE:与OpenAI Transformer的尺寸相当,以便比较性能
- BERT LARG:一个非常庞大的模型,它完成了本文介绍的最先进的结果
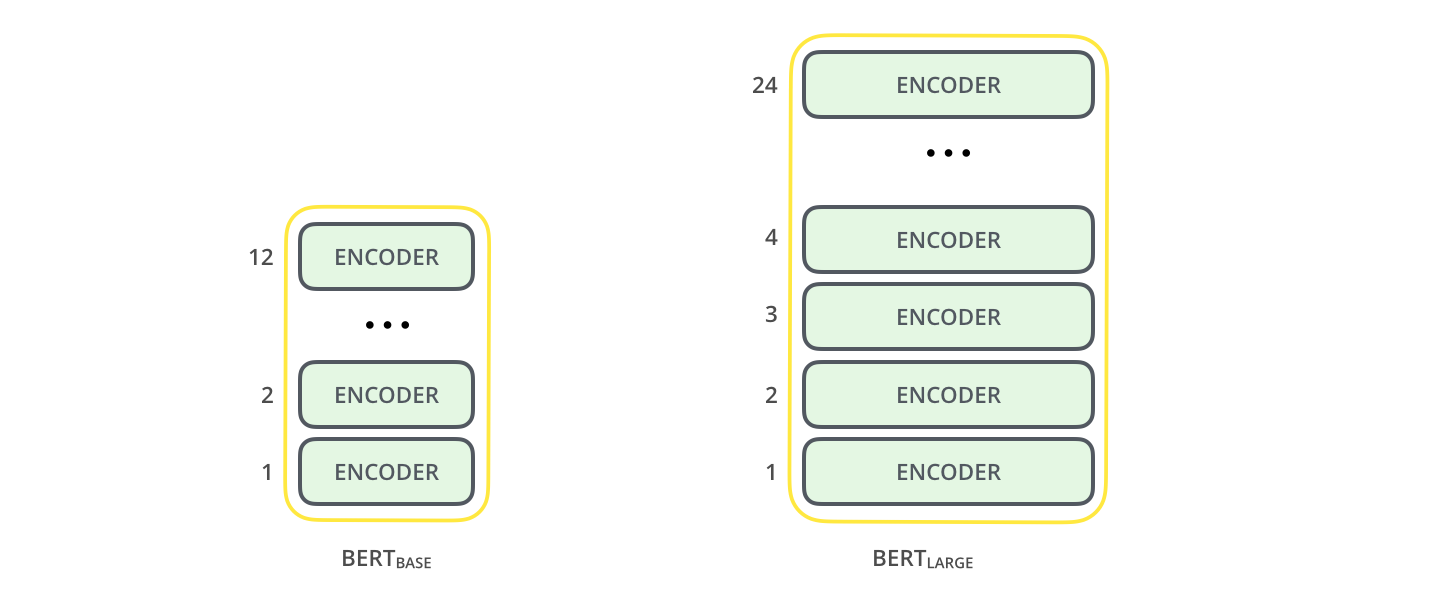
两个 BERT 模型的结构都比 transformer 更深,许多配置参数也更大:
- BASE 包含 12 层 encoder block,768 个隐藏层神经元,12 个 attention heads
- LARGE 包含 24 层 encoder block,1024 个隐藏层神经元,16 个 attention heads
BERT 的结构
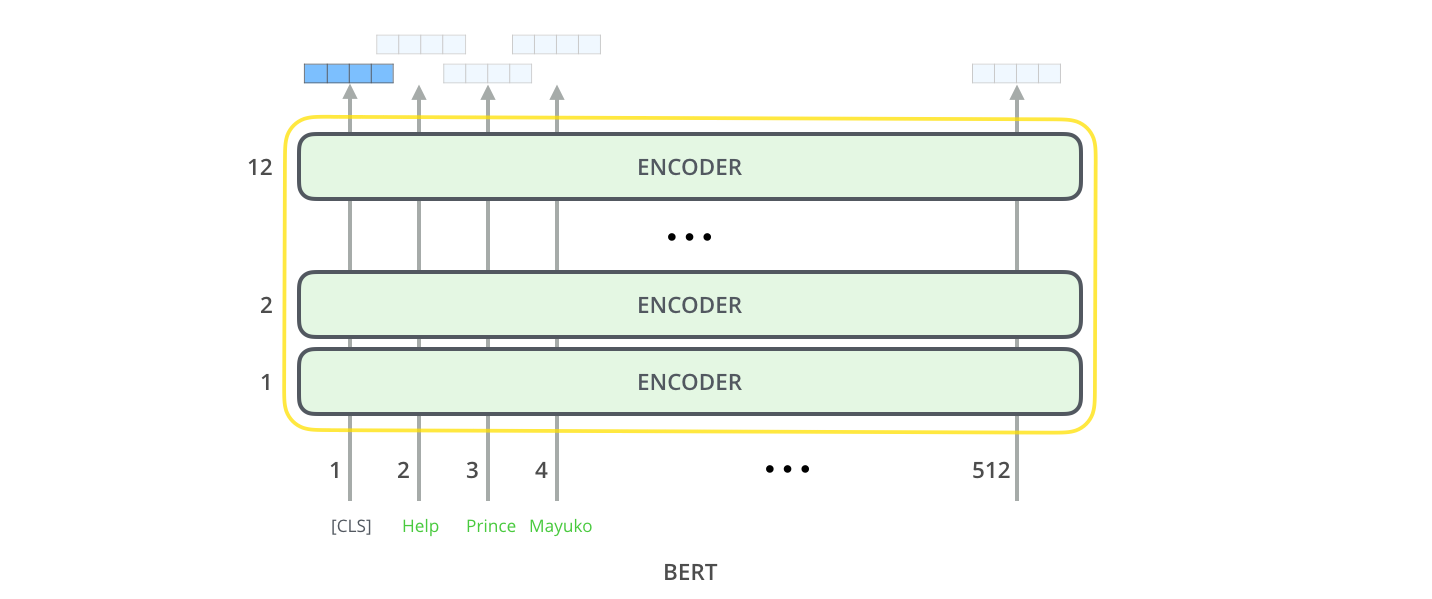
下面是 BERT 的完整结构

BERT 的输入
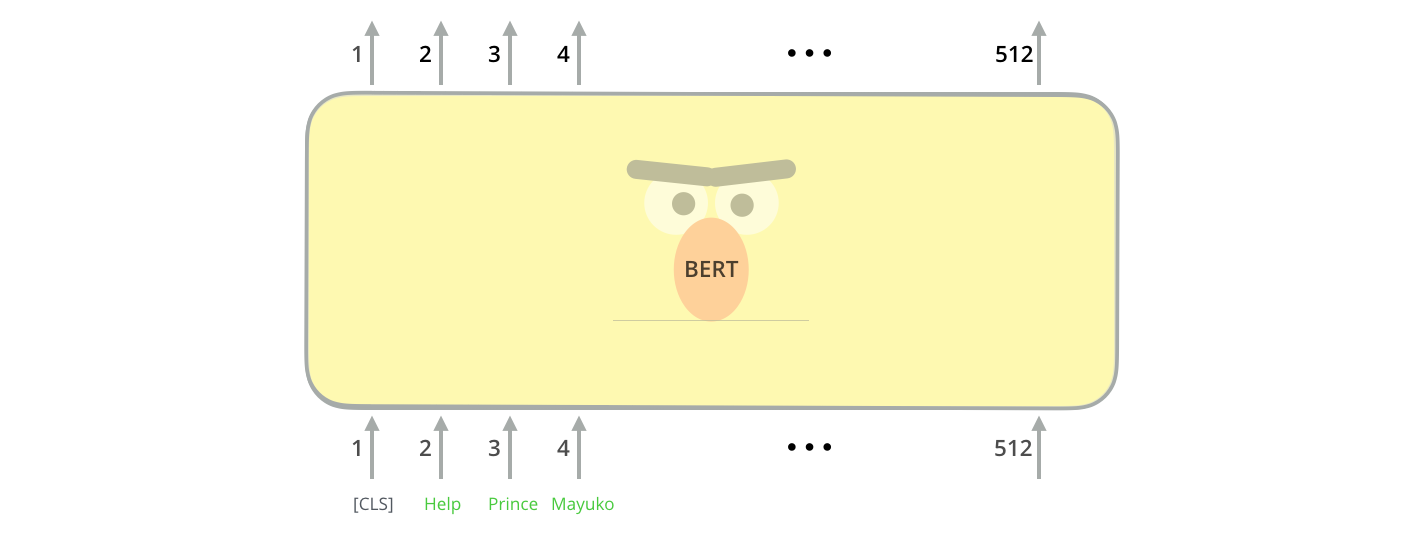
BERT 与 transformer 的编码方式一样。将固定长度的字符串作为输入,数据由下而上传递计算,每一层都用到了 self attention,并通过前馈神经网络传递其结果,将其交给下一个编码器(通过上图我们还可以知道,BERT 的最大输入序列长度为 512)
BERT 的输入为每一个 token 对应的表征,Fig.1 中粉色块就表示 token,黄色块是 token 对应的表征。另外,为了完成具体的分类任务,作者在输入的每一个序列开头都插入了特定的 classification token([CLS]),该 token 对应的最后的输出表征会被用来起到聚集整个序列表征讯息的作用
这里插一句 NLP 有四大类任务:
- 序列标注:如分词、实体识别、语义标注
- 分类任务:如文本分类、情感计算
- 句子关系判断:如 entailment、QA、自然语言推理
- 生成式任务:如机器翻译、文本摘要抽取
由于 BERT 是一个预训练模型,因此模型所输入的序列必须有能力包含一句话(e.g. 文本情感分类,序列标任务)或两句话(e.g. 文本摘要,自然语言推断,问答任务)。那么就需要让模型有能力去辨别哪一部分属于句子 A,或者哪一部分数据句子 B,BERT 采用两种方式:
- 在序列的 token 中把 special token ([SEP])插入到每个句子后面,以分开不同的句子的 token
- 为每一个 token 表征都添加一个可学习的 segment embedding 来指示这个 token 属于句子 A 还是句子 B
关于上图 BERT 输入的解释就是这样(如果输入序列只包含一个句子的话,则没有 [SEP] 和后面的 token)
上面提到了 token 的表征,实际上该表征由三部分组成:token embedding、segment embedding 和 position embedding

BERT 的输出
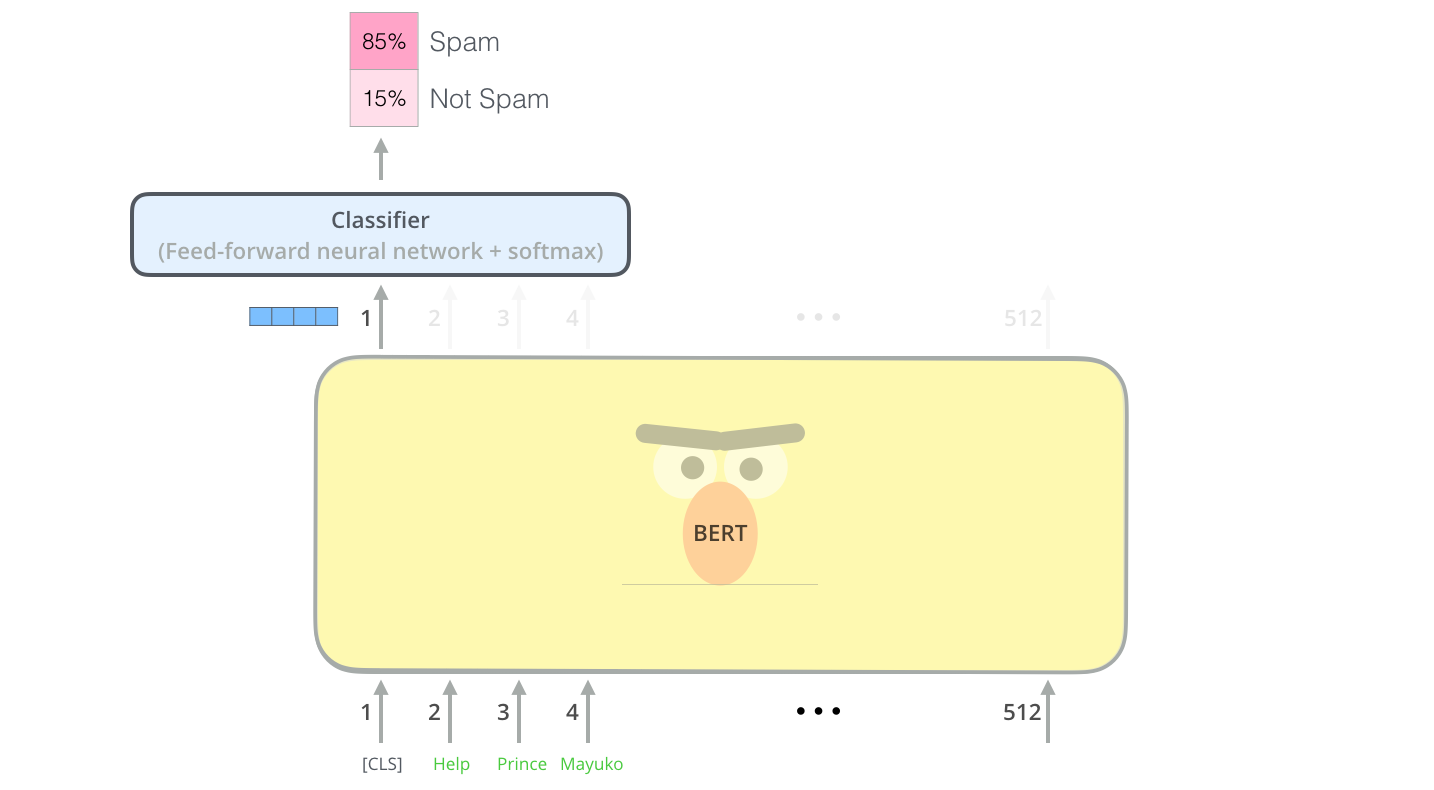
transformer 的特点是有多少个输入就会对应有多少个输出,每个位置返回的输出都是一个隐藏层大小的向量(基础版 BERT 为 768)
CCC 为 classification token([CLS])对应最后一个 transformer 的输出,TiT_iTi? 表示其他 token 对应的输出
- 对于一些 token 级别的任务(e.g. 序列标注和问答任务),就把 TiT_iTi? 输入到额外的输出层中进行预测
- 对于一些句子级别的任务,就把 CCC 输出到额外的输出层中(以文本分类为例,如下图所示)
BERT 的预训练任务
预训练的概念在 CV 中比较成熟,如我们会使用在 ImgeNet 上预训练好的 backbone 完成物体检测的任务(e.g. RCNN 一族)
虽然在 NLP 领域没有像 ImageNet 这样高质量的人工标注数据,但是可以利用大规模数据点的自监督性质来构建预训练任务。因此,BERT 构建了两个预训练任务――masked language model 和 next sentence prediction
MLM
MLM 是 BERT 突破单向语言模型限制的重要原因
简单来说,MLM 就是以 15% 的概率用 mask token([MASK])随机地替换掉训练序列中的 token,然后预测出 [MASK] 位置原来的单词是什么。然而,这种方式也导致了一定的问题――预训练的过程产生的语言表征对 [MASK] 比较敏感,而对其他 token 不是很敏感,又 mask token 并不会出现在下游任务的 fine-tuning 阶段,那么这就会导致与训练和 fine-tunning 的一丢丢不匹配
BERT 采用下面的策略来解决这个问题:
首先,在每个训练序列中以 15% 的概率随机选中一些 token 用于预测,
- 这些选中的 token 中 80% 会被替换为 [MASK](e.g. my dog is hairy → my dog is [MASK])
- 10% 的会用其他随机的 token 进行替换(e.g. my dog is hairy → my dog is apple)
- 还有 10% 保留原来的 token 不变(这部分样本可以理解为与前一个替换方式形成了正负样本的比较)
现在,假如 ithi\ thi th token 被选中,那么在后面的时候就用 TiT_iTi? 去预测原来的 token(p.s. 将 TiT_iTi? 输入到全连接层,然后用 softmax 输出每个 token 的概率,最后使用交叉熵计算损失)
通过这样的策略就可以使得 BERT 不再只对 mask token 敏感,而对所有的 token 都敏感,于是就能抽取出任何 token 的表征信息
论文提供了 ablation for different masking procedures,其中基于特征方法的 NER 并没有添加任何 adjust representation 的操作,因此它的 mismatch 会更大一些。作者的实验结果如下表格所示,可以发现,完全使用 [MASK] 替换的 feature-based NER 确实存在严重的 mismatch 的问题。同样的,完全使用随机替换的方式也并不是很好

next sentence prediction
MLM 任务倾向于抽取 token 层次的表征,对于一些需要理解两个句子之间关系的任务,MLM 就会有一些问题。为了使模型能够理解句子之间的关系,BERT 使用了 NSP――预测两个句子是否连在一起。具体的做法是:我们在语料库中挑选出来句子 A 和句子 B 组成一个训练样本,50% 的情况句子 B 就是句子 A 的下文(标注为 IsNext),50% 的情况是随机挑选的(标注为 NotNext)。接下来就把训练样本输入到 BERT 模型中,根据输出 CCC 去进行二分类预测
举个例子,0

这样子每个训练样本就能够对应两个任务(MLM 和 NSP),把这两个的损失加在一起就得到了整个预训练的损失
可以明显看出,这两个任务的数据集都是从无标签的文本数据中构建的,这也就是我们前面提到的自监督性质,比 CV 中人工标注的 ImageNet 数据集简单多了
Fine tuning
fine tuning 所需要做的就是在预先训练好的模型中添加一个简单的分类层,然后所有的参数根据下游任务联合进行适当调整。如下图所示,论文介绍了如何将 BERT 用于 4 种下游任务

BERT for feature extraction
fine tuning 并不是使用 BERT 的唯一方式。我们可以使用预训练的 BERT 来创建语境化词嵌入。这么做是有意义的,
- 不是所有的任务都可以使用 transformer encoder 的输出,需要根据下游任务添加特定的模块
- 预先通过一次复杂的计算得到训练数据有效的表征,然后通过表征去完成后面的一些应用和实验,这样是十分节约计算成本的
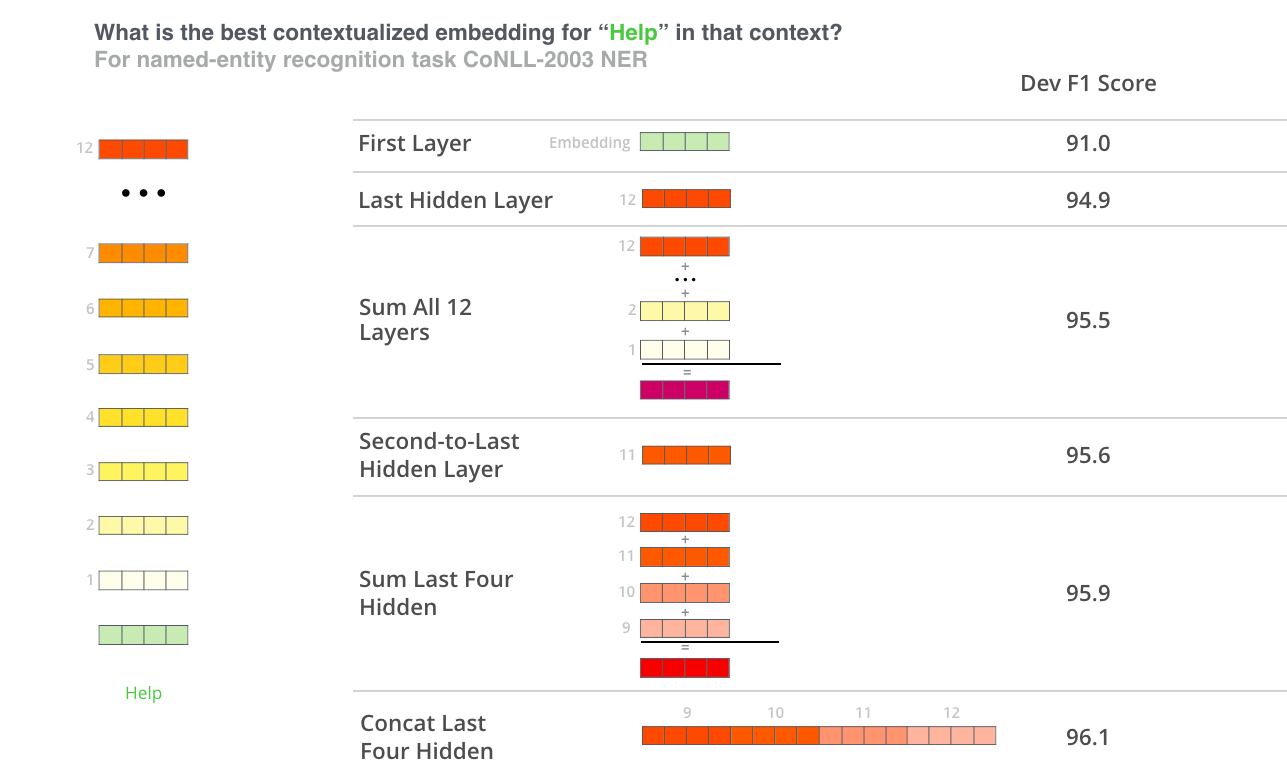
那么选取哪些向量作为词嵌入呢?这取决于具体的下游任务,论文比较了 6 中词嵌入的选择,如下图所示

关于 BERT 的思考
BERT 有个很严重的问题,速度慢,计算资源消耗大。其效果的提升跟大语料有不可分割的关系
但是 BERT 又是具有里程碑意义的,其里程碑意义就在于:证明了一个非常深的模型可以显著提高 NLP 任务的准确率,而这个模型可以从无标记数据集中预训练得到
Reference
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
- BERT的理解
- 什么是BERT?
- 如何评价 BERT 模型?